Yun Bloghttps://www.gravatar.com/avatar/d313a2c442931458ed624a3999d75011기술 블로그2024-04-07T09:50:37.685Zhttps://cheese10yun.github.io/Yuncheese10yun@gmail.comHexoLocust 성능 테스트 도구 소개 Part 2https://cheese10yun.github.io/locust-part-2/2024-04-06T15:00:00.000Z2024-04-07T09:50:37.685Z이 글을 읽기 전에, Locust 성능 테스트 도구 소개를 먼저 확인해 보시는 것이 좋습니다. 이를 통해 Locust의 기본적인 사용법과 개념을 이해하신 후, 본 글에서 다루는 보다 심화된 사용 방법과 전략에 쉽게 접근하실 수 있습니다.
on_start와 on_stop 메서드는 사용자의 세션 시작과 종료 시 특정 작업을 실행하는 데 사용됩니다. 로그인과 로그아웃 외에도, 사용자가 시나리오를 시작하기 전에 필요한 데이터를 세팅하거나, 시나리오 종료 후 사용한 리소스를 정리하는 데 사용할 수 있습니다. 예를 들어, 시나리오 시작 시 특정 API를 호출하여 필요한 설정을 하거나, 시나리오가 끝난 후 생성된 데이터를 삭제하는 등의 작업이 있을 수 있습니다. 이러한 메서드를 통해 테스트의 사전 준비와 후처리를 자동화할 수 있습니다. on_start는 사용자가 시작될 때 호출되며, on_stop은 사용자가 종료될 때 호출됩니다. 강제로 loucst를 종료하면 on_stop 메서드가 호출되지 않습니다.
@task 데코레이터는 Locust에서 작업의 실행 빈도나 우선순위를 지정하는 데 사용됩니다. 숫자를 인자로 제공함으로써, 특정 작업이 다른 작업들에 비해 상대적으로 얼마나 자주 실행될지 결정할 수 있습니다. 예를 들어, @task(3)은 해당 작업이 같은 TaskSet 내 다른 @task(1) 작업보다 세 배 더 많이 실행됨을 의미합니다. 이를 통해 실제 사용자 행동을 더 잘 모방한 부하 테스트 시나리오를 구성할 수 있습니다.
classOrderTask(HttpUser): wait_time = constant_pacing(2) # 최소 10초 간격으로 작업 실행이 보장되도록 대기 시간 설정 host = "http://localhost:8080"# 테스트 대상 호스트 주소 지정
tasks = [OrderTaskSet]
순차적 TaskSets를 사용하는 워크플로우 시뮬레이션은 사용자가 실제 애플리케이션을 사용할 때의 행동 순서를 모방하는 데 사용됩니다. 이 방식에서는 TaskSet 클래스 내에서 각각의 @task 함수가 사용자의 다음 동작을 시뮬레이션합니다. 이 예제에서는 OrderTaskSet 내의 getOrder와 getShop이 동일한 비율로 실행되며, 사용자는 이 두 작업 사이를 순차적으로, 또는 랜덤으로 전환하면서 진행할 수 있습니다. constant_pacing 설정을 통해 각 작업 사이의 실행 간격을 조절함으로써, 실제 사용자 경험에 더 가까운 테스트 환경을 구성할 수 있습니다. 자세한 내용은 Locust 공식 문서를 참조하세요.
공식 문서는 정확한 비율의 작업 호출을 달성하기 위해 루프와 제어문 사용을 권장합니다. @task를 이용한 간단한 호출 비율 조정은 대략적인 작업 순서에 적합하지만, 정확한 작업 순서가 필요한 경우, 공식 문서의 권장 사항을 따르는 것이 더 바람직합니다.
# 사용자 정의 부하 모양을 정의하는 LoadTestShape 클래스 classCustomShape(LoadTestShape): time_limit = 600# 부하 테스트의 총 시간 한계 설정 spawn_rate = 20# 초당 새로운 사용자를 생성하는 속도 설정
deftick(self): run_time = self.get_run_time() # 현재 실행 시간 가져오기
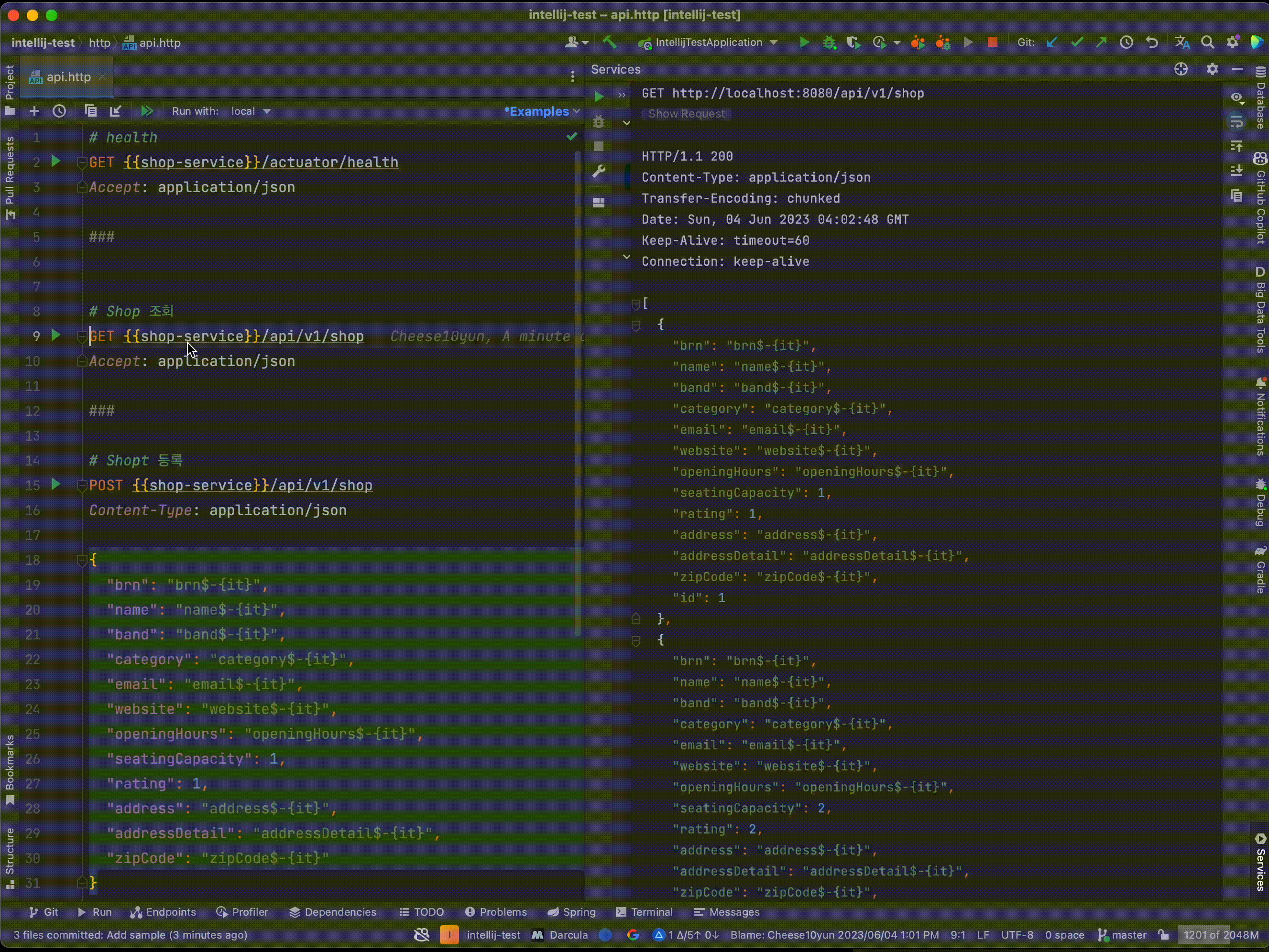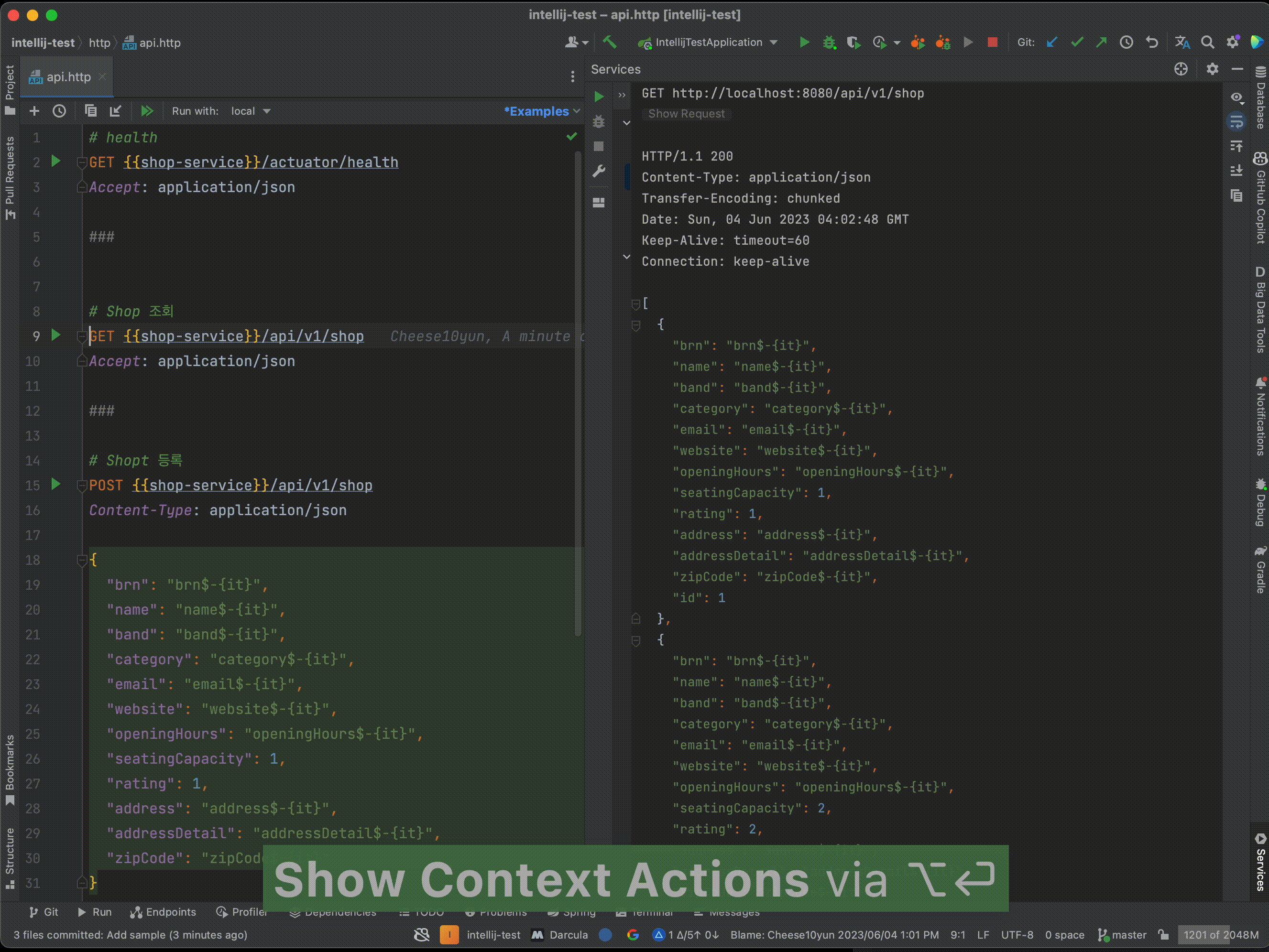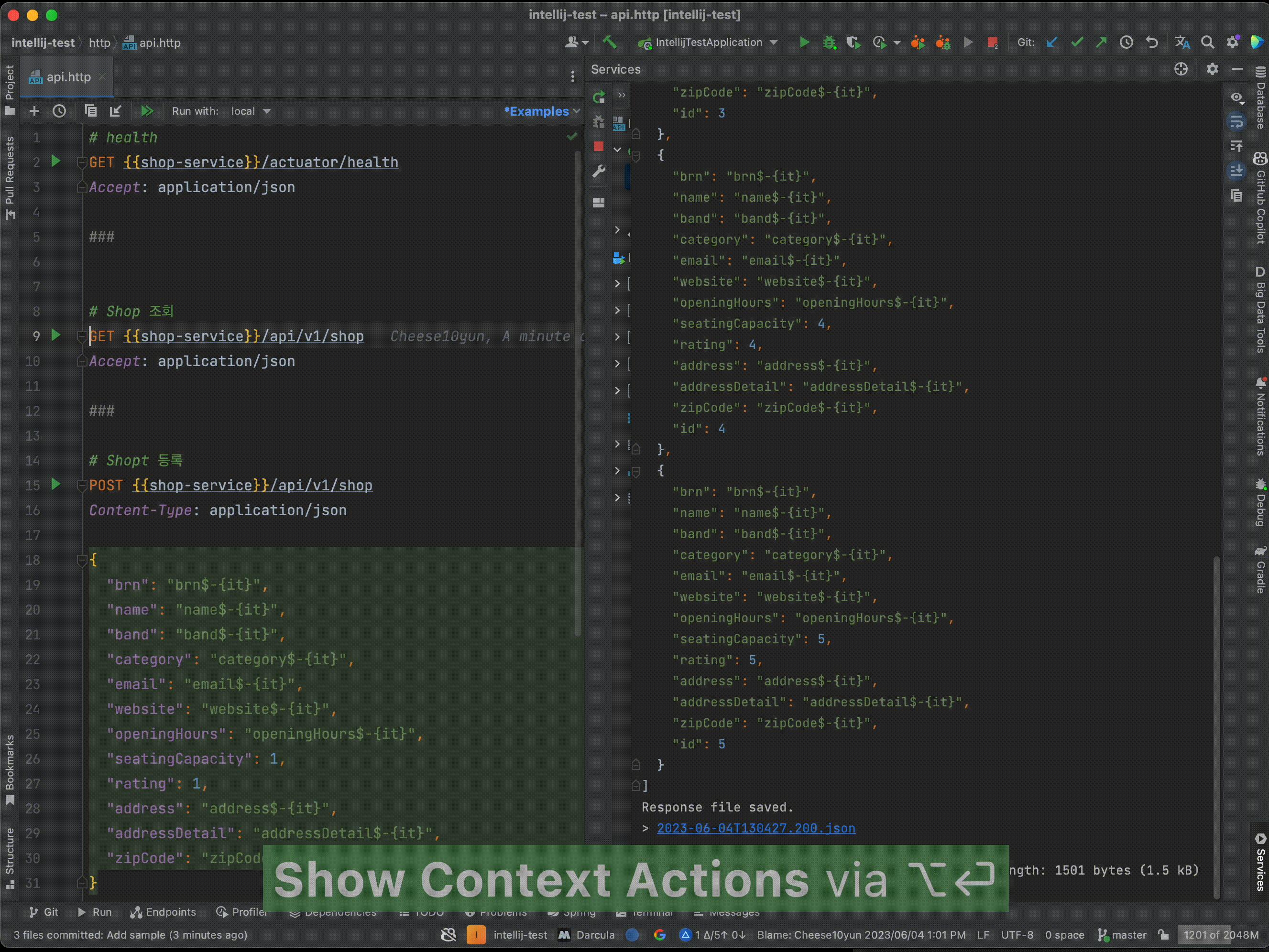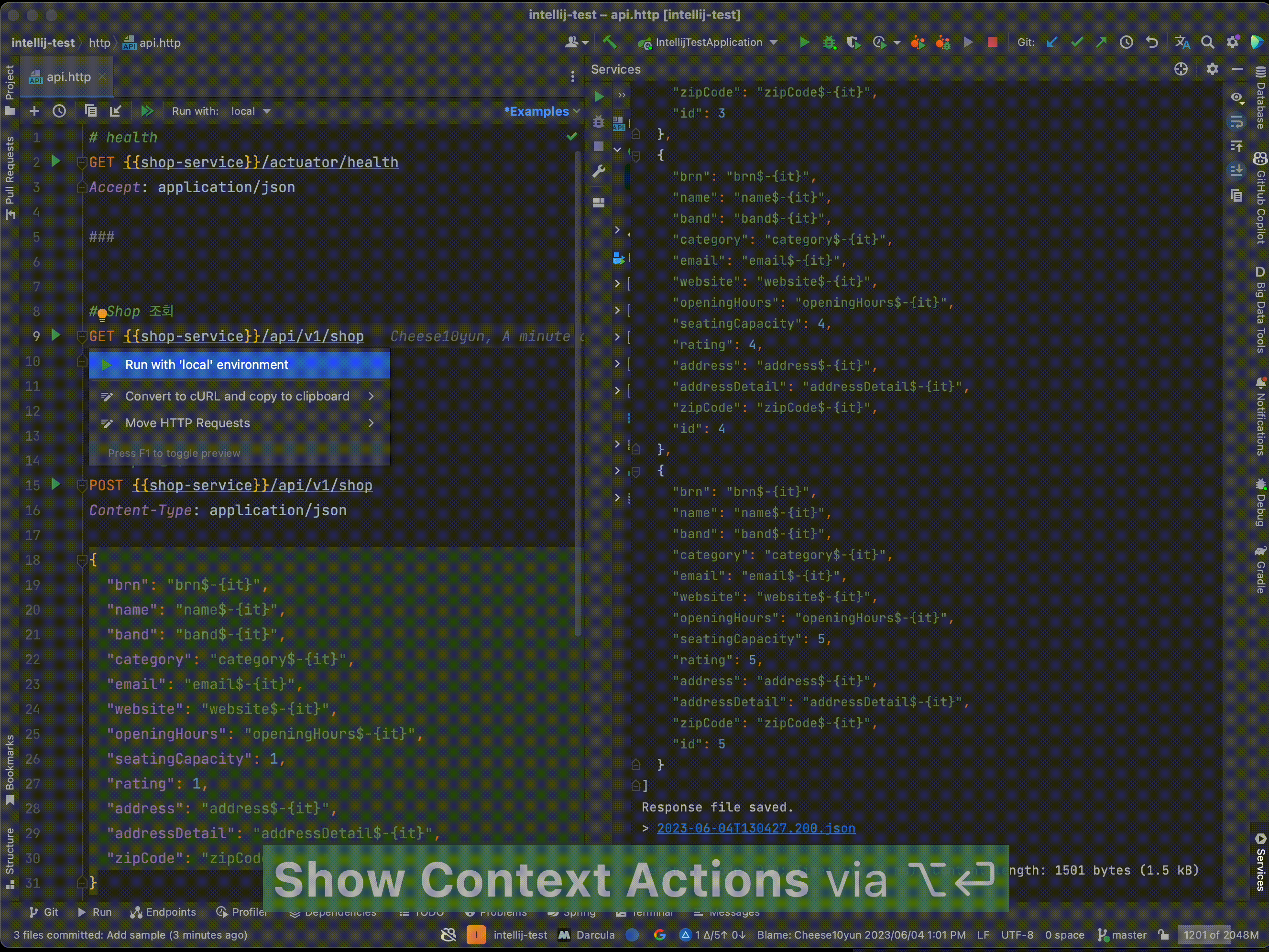
if run_time < self.time_limit: # 실행 시간에 따라 사용자 수 증가 user_count = run_time // 10 return (user_count, self.spawn_rate)
returnNone# 시간 한계를 넘으면 테스트 종료
위 코드는 Locust를 사용한 사용자 정의 부하 테스트 시나리오를 설정하는 예시입니다. 테스트 시작부터 시간이 600초(10분)에 이르기까지 실행 시간에 따라 사용자 수를 점진적으로 증가시킵니다. tick 함수는 현재 실행 시간을 기반으로 사용자 수를 결정하고, 실행 시간이 10초마다 사용자 수를 1명씩 증가시키는 로직을 포함하고 있습니다. 시간 한계에 도달하면, 즉 실행 시간이 600초를 초과하면, 테스트는 자동으로 종료됩니다. 이를 통해 초기 단계에서는 부하가 점점 증가하다가 설정된 시간이 지나면 테스트가 종료되는 시나리오를 구현할 수 있습니다.
정리
사용자 세션 시작과 종료에 필요한 동작을 자동화하는 on_start와 on_stop 메서드, 다양한 API 요청의 실행 비율을 조절하는 @task, 실제 사용자 워크플로우 시뮬레이션에 유용한 순차적 TaskSets, 그리고 테스트 동안 사용자 부하를 동적으로 조절할 수 있는 맞춤형 부하 형태 CustomShape에 대해 설명합니다. 이 방법들은 Locust를 활용하여 보다 실제적이고 유연한 성능 테스트를 구현하는 데 도움을 줍니다.
]]>
<p>이 글을 읽기 전에, <a href="https://cheese10yun.github.io/locust-part-1/">Locust 성능 테스트 도구 소개</a>를 먼저 확인해 보시는 것이 좋습니다. 이를 통해 Locust의 기본적인 사용법과 개
Locust 성능 테스트 도구 소개 Part 1https://cheese10yun.github.io/locust-part-1/2024-03-30T15:00:00.000Z2024-04-07T09:50:37.682ZLocust 란?
Locust는 오픈 소스 부하 테스트 도구로, 사용자가 Python으로 시나리오를 작성하여 웹 애플리케이션의 성능을 측정할 수 있게 해줍니다. 이 도구는 이벤트 기반 모델을 사용하여 수천 명의 사용자를 시뮬레이션하고, 웹사이트나 API 서버에 대한 부하 테스트를 실시간으로 실행할 수 있습니다. Locust는 사용자 친화적인 웹 인터페이스를 제공하여 테스트의 진행 상황을 모니터링하고, 결과를 분석할 수 있게 합니다.
Locust 설치
1
$ pip install locust
pip를 통해서 locust를 설치합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from locust import HttpUser, task, constant import random
class HelloWorldUser(HttpUser): wait_time = constant(1) # 모든 요청 사이에 1초의 고정된 대기 시간 설정 host = "http://localhost:8080" # 테스트 대상 호스트 주소 지정
간단하게 HTTP GET 요청을 보내는 Locust 스크립트를 작성해보았습니다. HttpUser 클래스를 상속받아 사용자 클래스를 정의하고, @task 데코레이터를 사용하여 테스트 함수를 정의합니다. self.client.get 메서드를 사용하여 GET 요청을 보내고, params와 name 매개변수를 사용하여 요청 파라미터와 요청 이름을 설정합니다.
1
$ locust -f <file_name.py>
locust 명령어를 사용하여 Locust 스크립트를 실행합니다. -f 옵션을 사용하여 실행할 스크립트 파일을 지정합니다. 실행 후 웹 브라우저에서 http://localhost:8089로 접속하여 Locust 웹 인터페이스를 확인할 수 있습니다. 만약 파일명을 locustfile.py 으로 지정했다면 locust 명령어만 수행하면 됩니다.
Locust의 특징
API 서버 성능 테스트 도구로 많이 알려진 도구들 중 JMeter와 nGrinder는 강력한 기능과 세밀한 설정 옵션으로 널리 사용되고 있습니다. 이러한 도구들은 복잡한 시나리오를 구현하고 대규모의 부하 테스트를 수행할 수 있는 뛰어난 능력을 가지고 있습니다. 그러나 이러한 기능성과 다양성이 더 간편하고 신속한 테스트 실행을 선호하는 사용자들에게는 설정과 실행 과정에서의 복잡성으로 인해 접근성이 떨어질 수 있습니다.
이에 비해 Locust는 사용자 친화적인 API 서버 성능 테스트 도구로, 그 사용의 용이성과 편리함에서 큰 장점을 가지고 있습니다. 특히, Locust는 Python으로 테스트 스크립트를 작성하기 때문에, 기존에 Python을 사용해본 경험이 있는 개발자라면 누구나 쉽게 접근할 수 있습니다. 이는 테스트 스크립트의 작성과 수정을 매우 간단하게 만들어 줍니다.
Locust의 설치 및 운용의 용이성은 테스트 프로세스를 대폭 단순화시킵니다. 몇 가지 간단한 명령어로 Locust를 설치할 수 있으며, 별도의 복잡한 설정 없이도 로컬 환경에서 바로 부하 테스트를 시작할 수 있습니다. 이러한 점은 개발 초기 단계에서 빠르게 API 성능을 평가하고자 할 때 특히 유용합니다.
또한, Locust로 작성된 테스트 스크립트는 Python 코드로 구성되어 있기 때문에, GitHub과 같은 원격 저장소에 코드를 올려두면 팀원이나 다른 개발자들이 언제든지 손쉽게 해당 스크립트를 클론하고, 필요한 부하 테스트를 즉시 실행할 수 있습니다. 이는 협업 환경에서의 테스트 과정을 매우 효율적으로 만들어 줍니다. 팀원들은 최신의 테스트 스크립트를 공유받아, 실시간으로 테스트 결과를 확인하고 성능 개선 작업을 진행할 수 있습니다.
이와 더불어, Locust는 실시간으로 테스트 결과를 웹 인터페이스를 통해 제공합니다. 사용자는 웹 브라우저를 통해 테스트의 진행 상황을 모니터링하고, 성능 지표를 실시간으로 확인할 수 있습니다. 이는 테스트 과정에서의 직관적인 데이터 분석과 신속한 의사 결정을 가능하게 합니다.
요약하자면, Locust는 설치와 사용이 쉬우며, 로컬 환경에서의 빠른 구동 능력으로 인해 개발자가 신속하게 성능 테스트를 수행할 수 있게 해줍니다. Python 기반의 스크립트 작성 방식은 깃헙과 같은 원격 저장소를 통한 협업에 매우 유리하며, 이로 인해 개발 프로세스의 효율성과 속도를 크게 향상시킬 수 있습니다.
Locust Dashboard
Start new load test
Start new load test 버튼을 클릭하여 새로운 부하 테스트를 시작할 수 있습니다. 이 버튼을 클릭하면 다음과 같은 옵션을 설정할 수 있는 팝업 창이 나타납니다.
Number of Users
정의: 테스트에서 동시에 시뮬레이션할 가상 사용자의 총 수입니다.
목적: 애플리케이션이 동시에 처리할 수 있는 사용자 수를 설정하여, 애플리케이션의 동시 사용자 처리 능력을 테스트합니다.
Ramp Up (일반적으로 Ramp Up 시간을 의미하며, Locust에서는 Spawn Rate으로 표현될 수 있음)
정의: 테스트 시작부터 설정된 전체 사용자 수에 도달하기까지의 시간 또는 사용자가 점진적으로 증가하는 속도입니다.
목적: 사용자 수가 점진적으로 증가하는 상황을 모델링하여, 애플리케이션이 사용자 증가 속도에 어떻게 대응하는지 평가합니다.
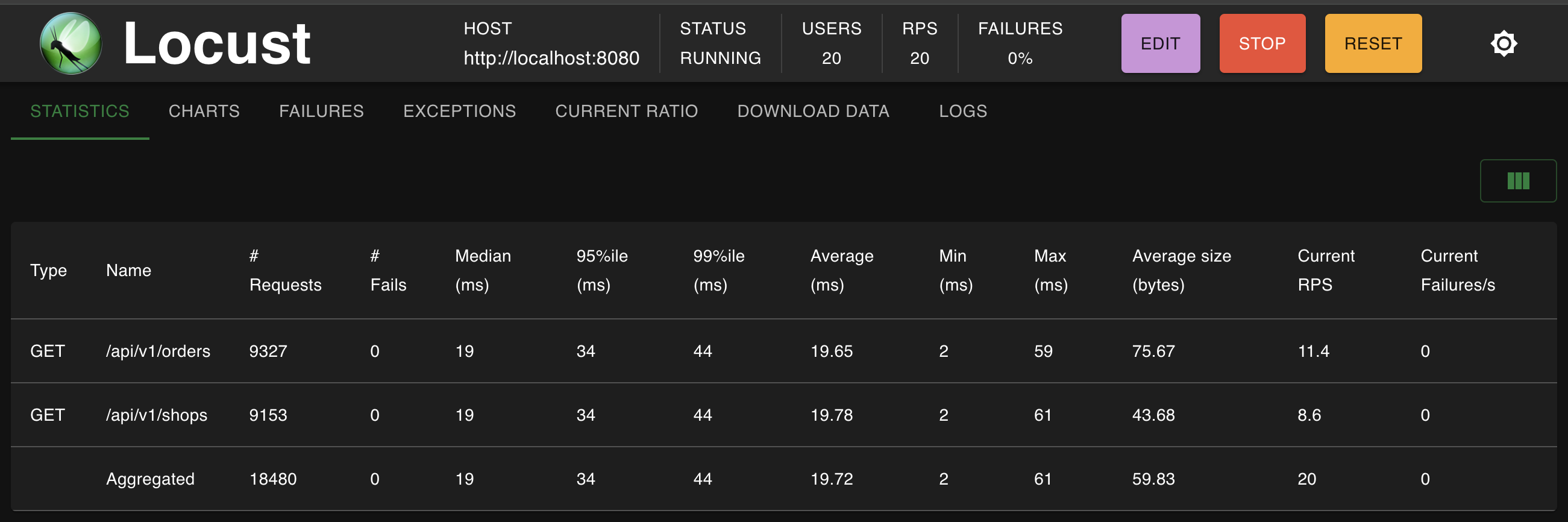
Statistics
Statistics 섹션은 현재 진행 중인 테스트의 실시간 통계를 제공합니다. 이 테이블에는 각 요청 유형별로 세분화된 데이터가 포함되어 있으며, 다음과 같은 정보를 확인할 수 있습니다:
Name: 요청의 이름이나 경로를 나타냅니다.
requests: 해당 요청이 몇 번 실행되었는지 보여줍니다.
failures: 요청 실패 횟수를 나타냅니다.
Median response time: 응답 시간의 중앙값(밀리초 단위)을 보여줍니다. 이는 모든 요청 중간에 위치하는 응답 시간을 의미합니다.
Average response time: 평균 응답 시간을 나타냅니다.
Min/Max response time: 관찰된 최소 및 최대 응답 시간입니다.
Request per second: 초당 요청 수를 보여줍니다.
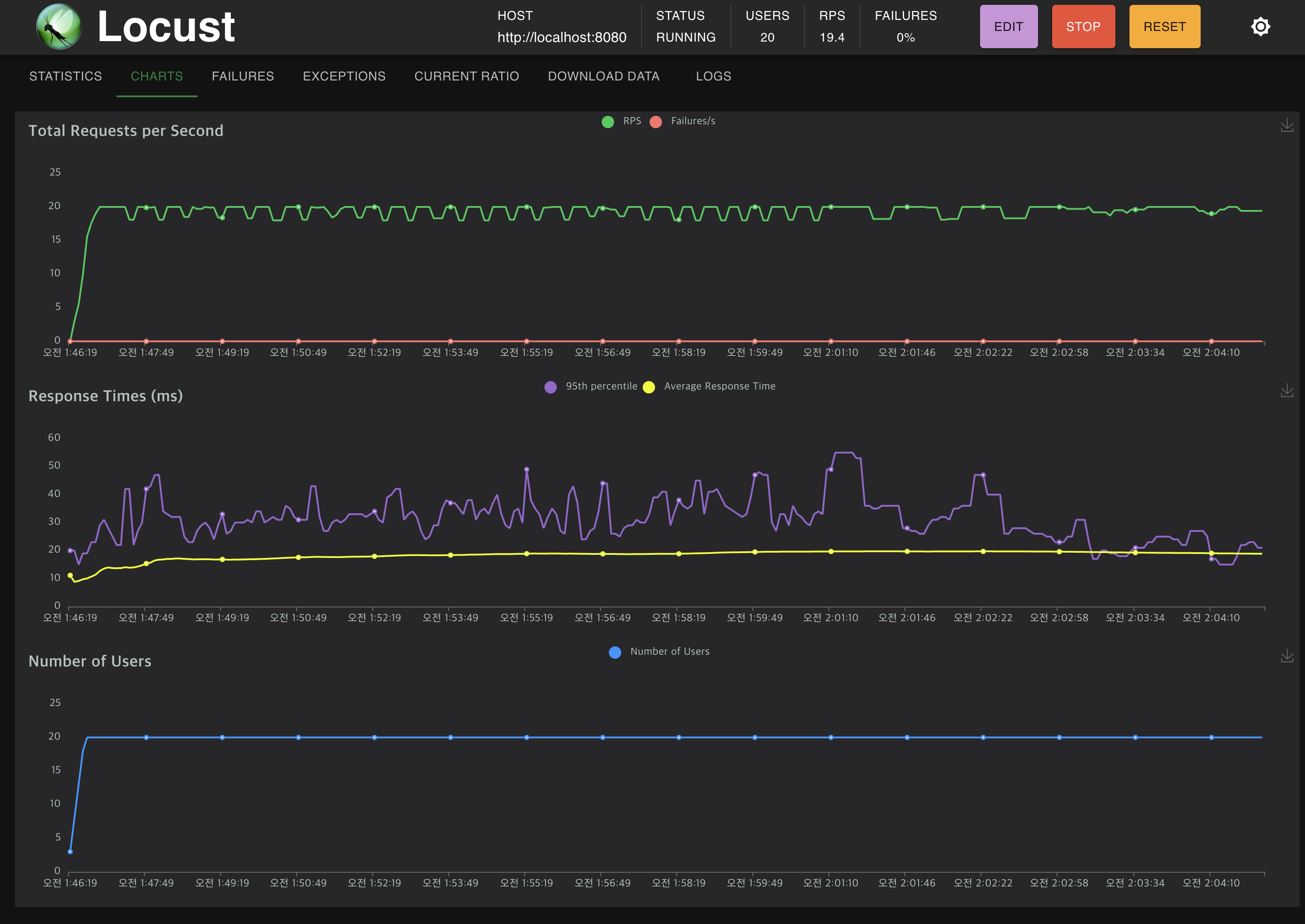
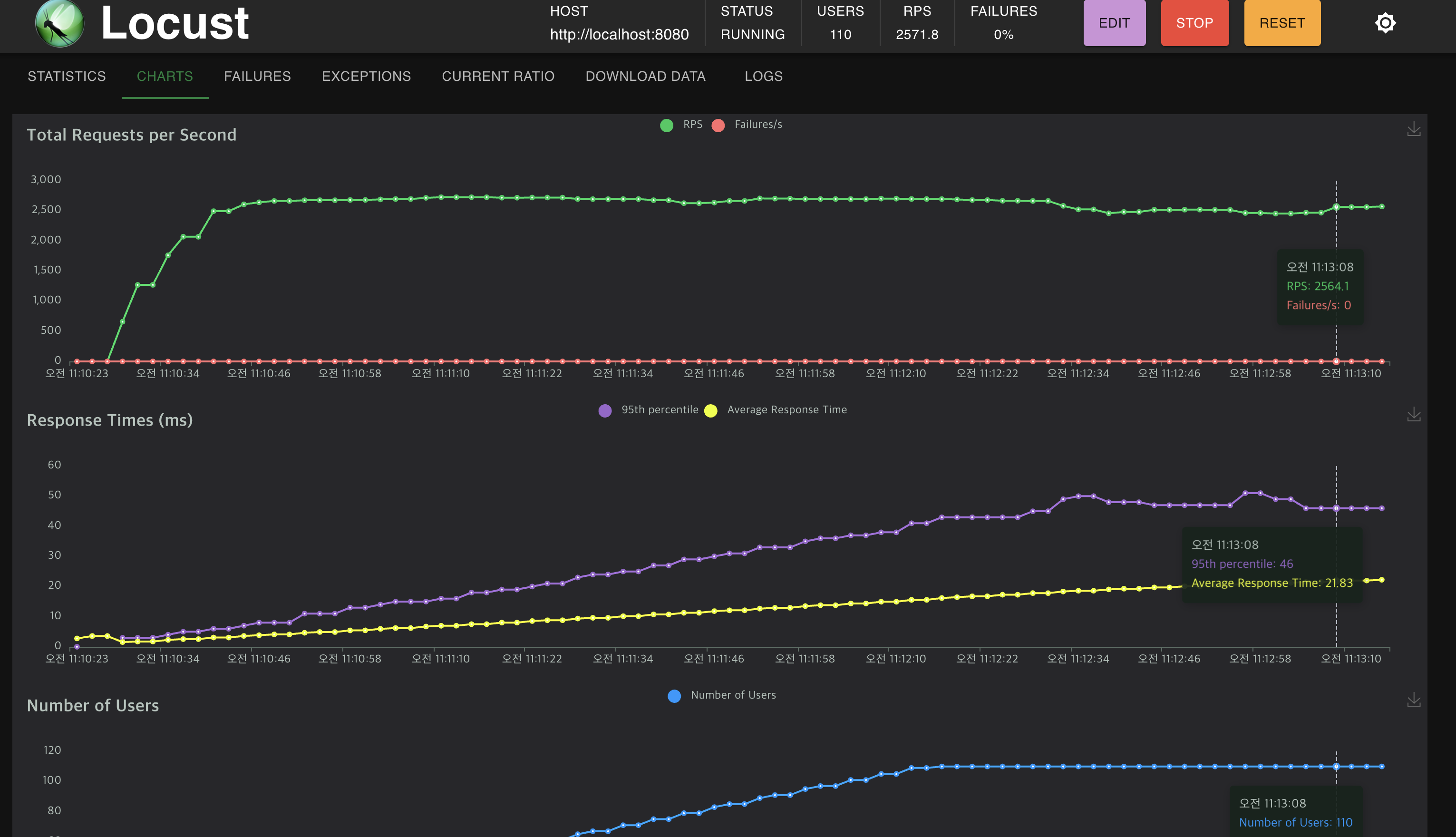
Charts
Charts 섹션은 테스트 동안 수집된 데이터를 그래프 형태로 시각화합니다. 이 차트는 테스트의 진행에 따라 동적으로 업데이트되며, 주로 다음과 같은 정보를 제공합니다.
Requests per second (RPS): 시간에 따른 초당 요청 수의 변화를 나타냅니다.
Response times: 다양한 응답 시간(평균, 최소, 최대)을 시간 경과에 따라 보여줍니다.
Number of users: 시간에 따른 사용자 수의 변화를 보여줍니다.
Download Data
Download Data 메뉴는 테스트 결과를 다운로드할 수 있는 옵션을 제공합니다. 테스트의 통계 및 차트 데이터를 CSV 파일 형식으로 내보낼 수 있으며, 이는 보다 심층적인 분석이나 문서화, 또는 다른 팀 구성원과의 공유를 위해 사용될 수 있습니다.
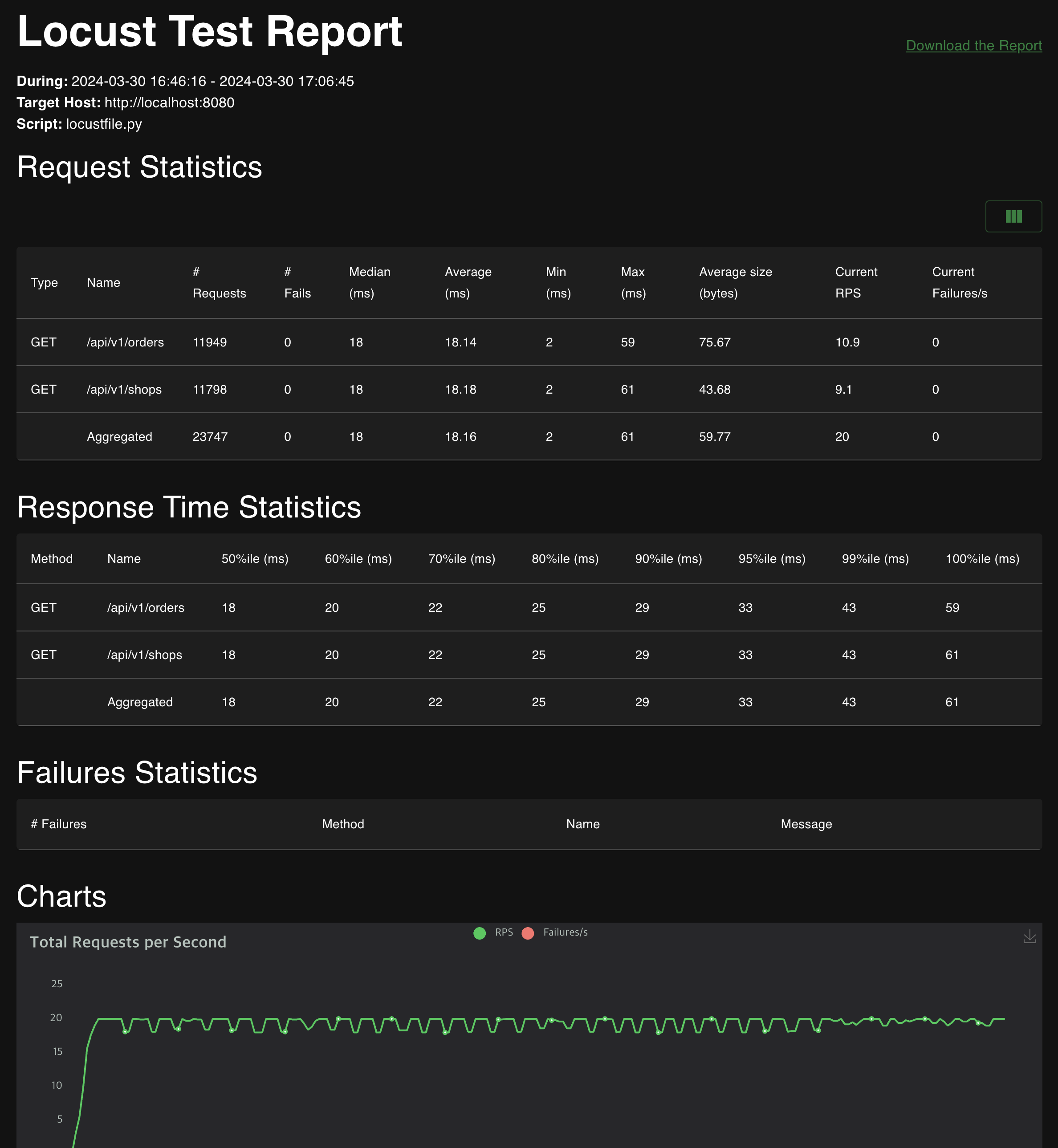
특히 Download the Report 메뉴를 통해 테스트 결과를 HTML 형식으로 다운로드할 수 있습니다. 이 HTML 리포트는 테스트의 요약 정보와 세부 통계, 그리고 차트 데이터를 포함하고 있으며, 테스트 결과를 보다 시각적으로 표현할 수 있습니다. 이 리포트는 테스트 결과를 문서화하거나, 다른 팀원과 공유할 때 유용하게 사용될 수 있습니다.
Local Performance Test
로컬 환경에서의 성능 테스트 결과, 루프백 네트워크를 통해 2,500 TPS를 달성했습니다. 이는 로컬 환경의 특성을 활용한 결과이며, 실제 운영 환경에서는 성능이 다를 수 있지만, 로컬에서 쉽게 높은 TPS를 달성할 수 있다는 점을 시사합니다.
정리
Locust는 사용의 용이성과 빠른 테스트 실행 능력으로 개발자에게 탁월한 부하 테스트 도구를 제공합니다. Python 기반으로 간단한 설치와 함께, 누구나 쉽게 테스트를 시작할 수 있으며, 이는 빠른 성능 평가와 적시의 개선으로 이어집니다.
원격 저장소를 통한 테스트 스크립트 공유는 팀 내 협업을 강화하며, 모든 팀원이 필요한 테스트를 쉽게 실행할 수 있게 합니다. 이러한 접근성은 테스트의 재사용성을 높이고, 개발 프로세스의 효율성을 개선합니다.
Locust는 단순한 테스트 도구를 넘어, 성능 모니터링과 개선을 위한 협업의 핵심이 됩니다. 이를 통해, 사용자에게 최적의 경험을 제공하는 애플리케이션을 구축할 수 있습니다.
]]>
<h2><span id="locust-란">Locust 란?</span></h2>
<p>Locust는 오픈 소스 부하 테스트 도구로, 사용자가 Python으로 시나리오를 작성하여 웹 애플리케이션의 성능을 측정할 수 있게 해줍니다. 이 도구는 이벤트 기
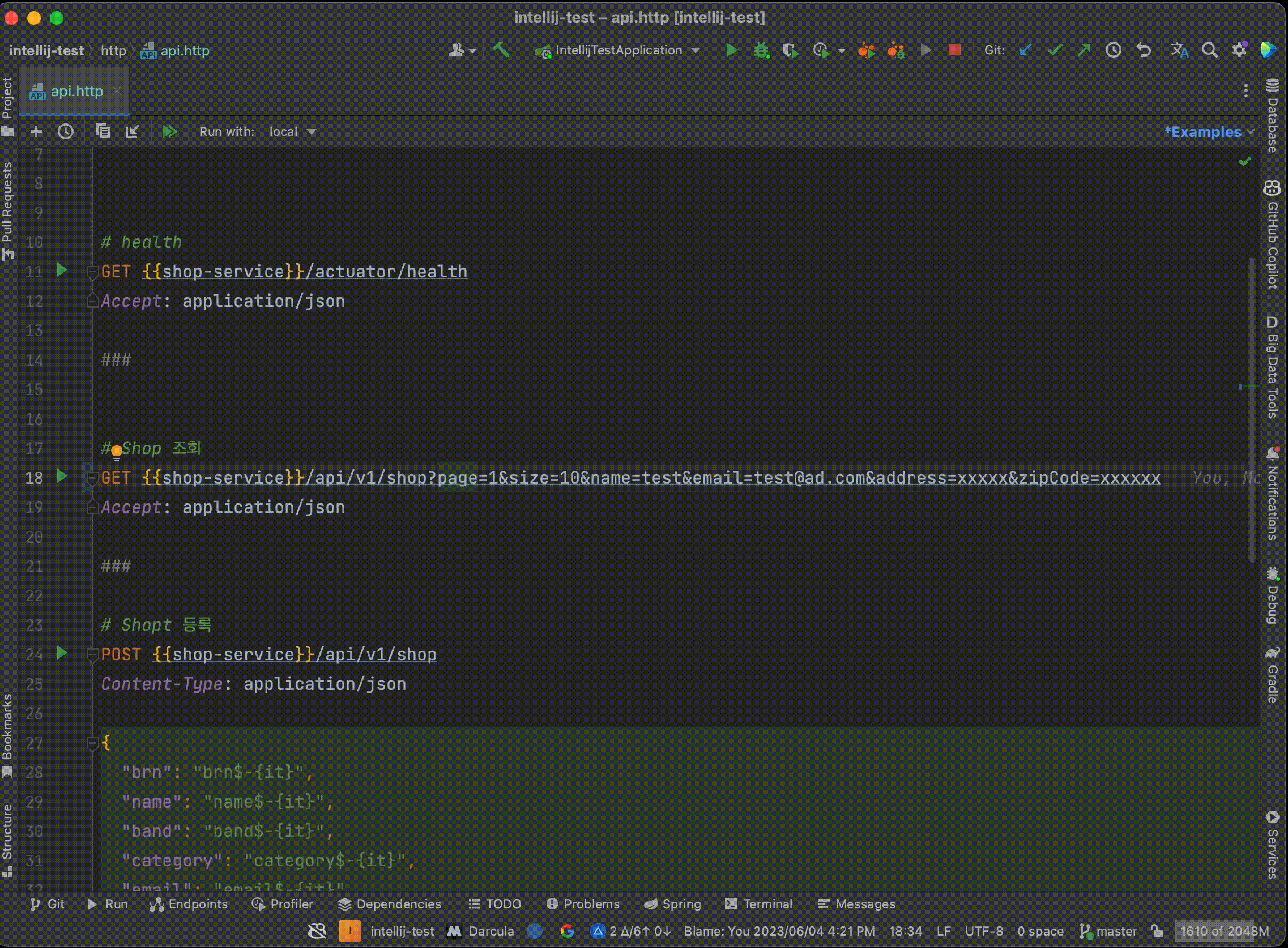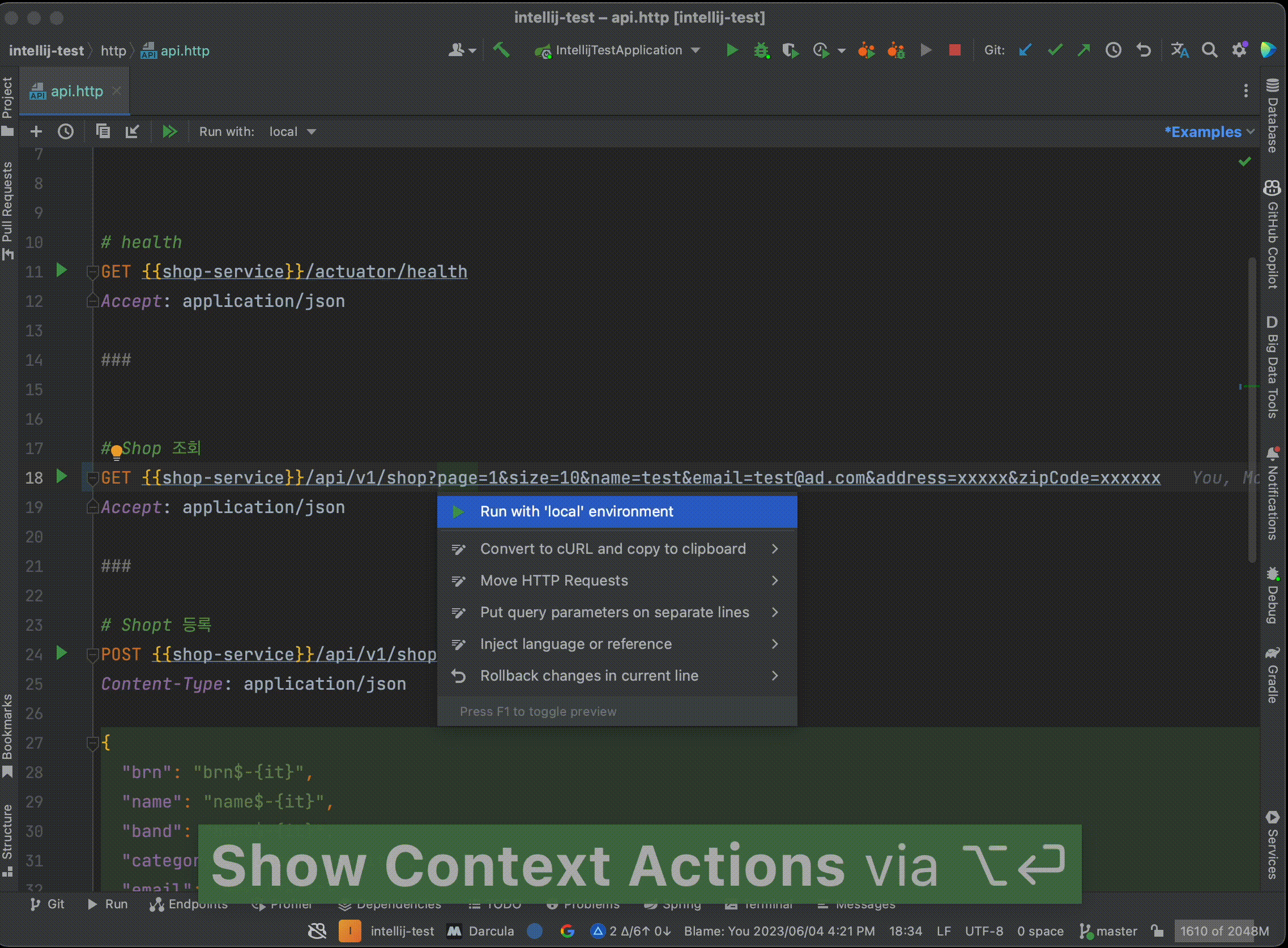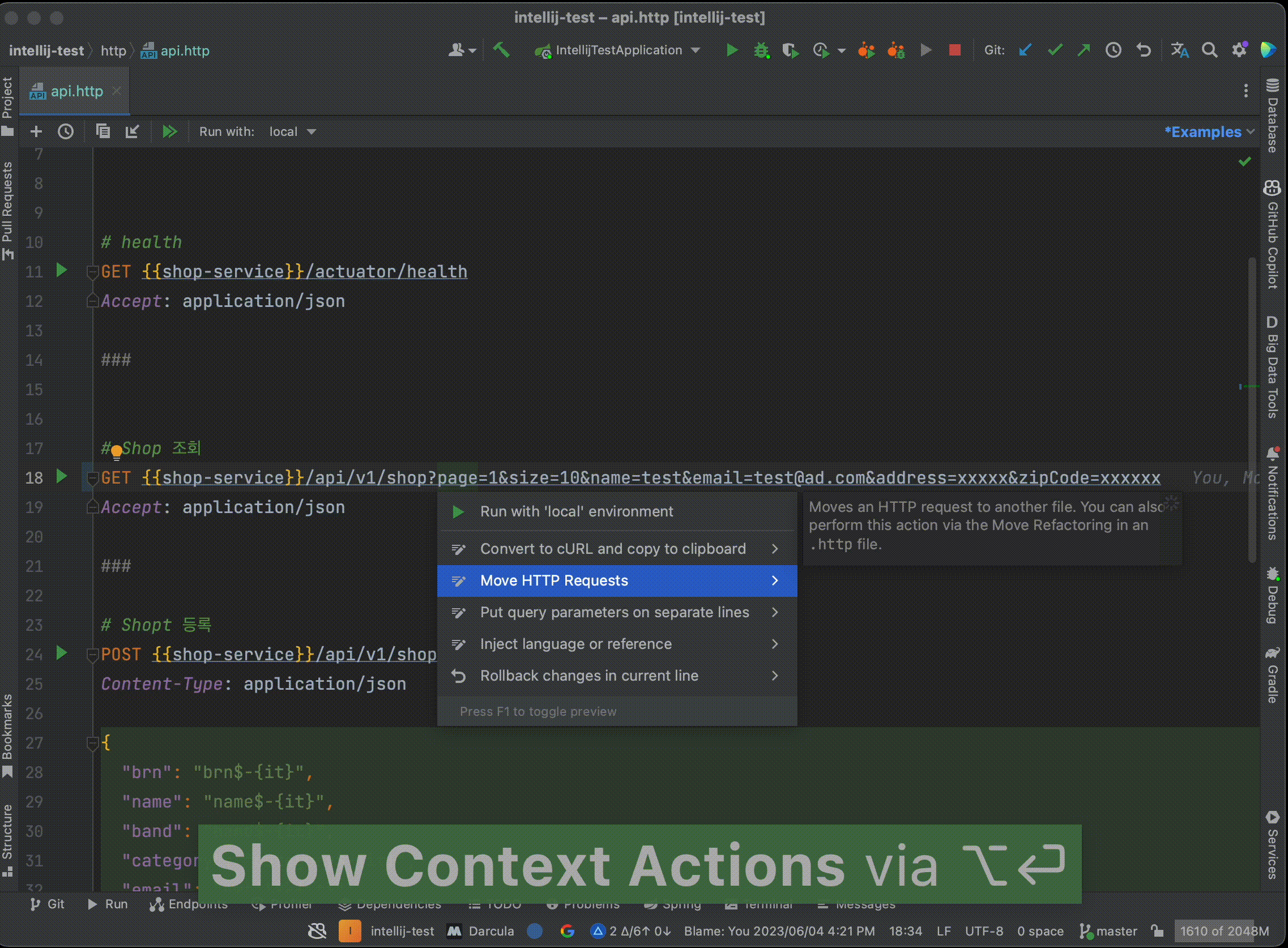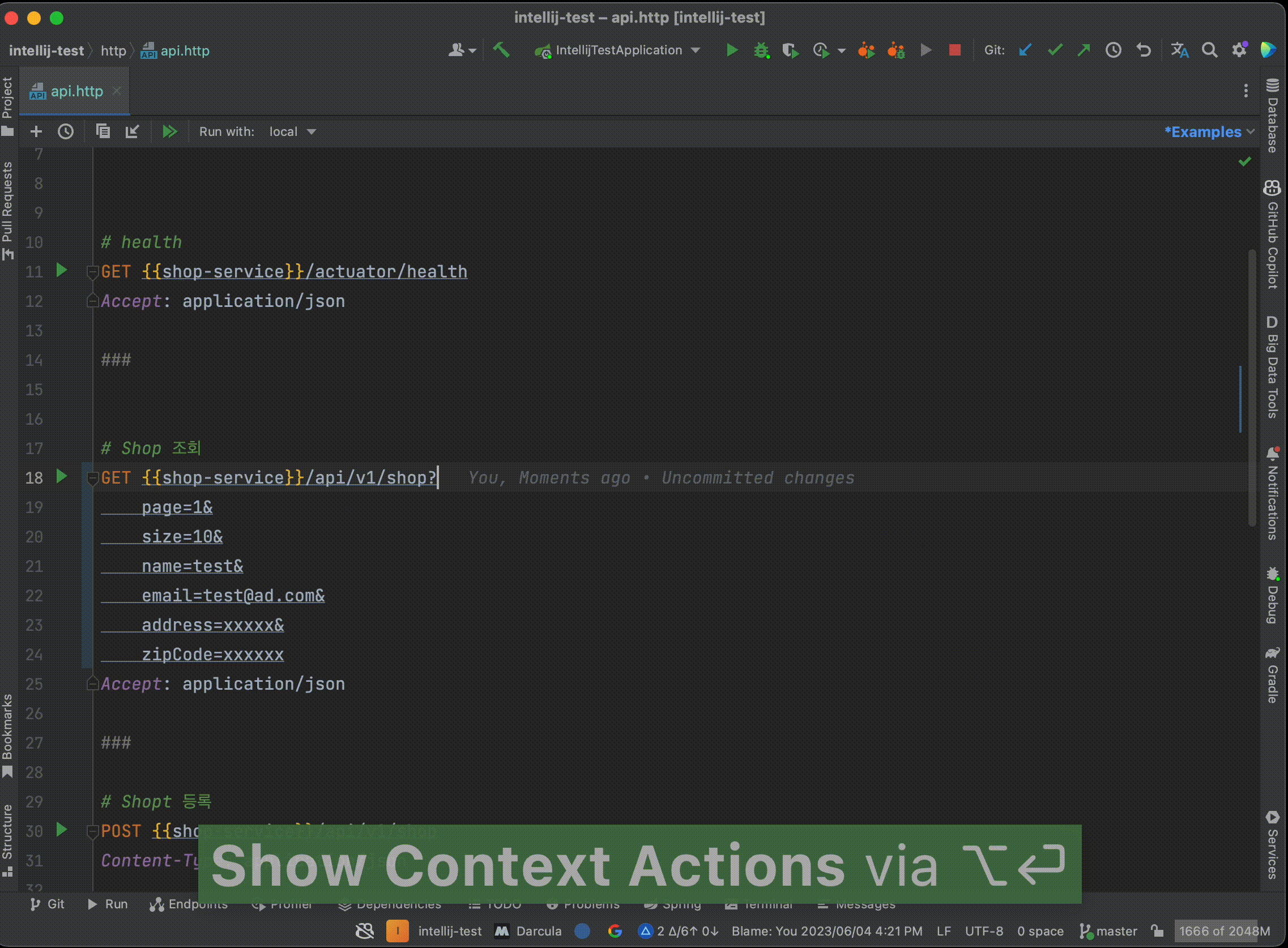
IntelliJ 각종 팁https://cheese10yun.github.io/intellij-tip2/2024-02-25T14:26:36.000Z2024-02-25T14:28:36.037ZDatabase Global
IntelliJ에서는 MySQL, Oracle, PostgreSQL, Redis, Mongo DB 등을 포함한 다양한 데이터베이스에 대한 지원을 제공해주고 있습니다. 이를 통해서 동일한 도구를 이용해서 다양한 데이터베이스에 대한 작업을 수행할 수 있습니다.
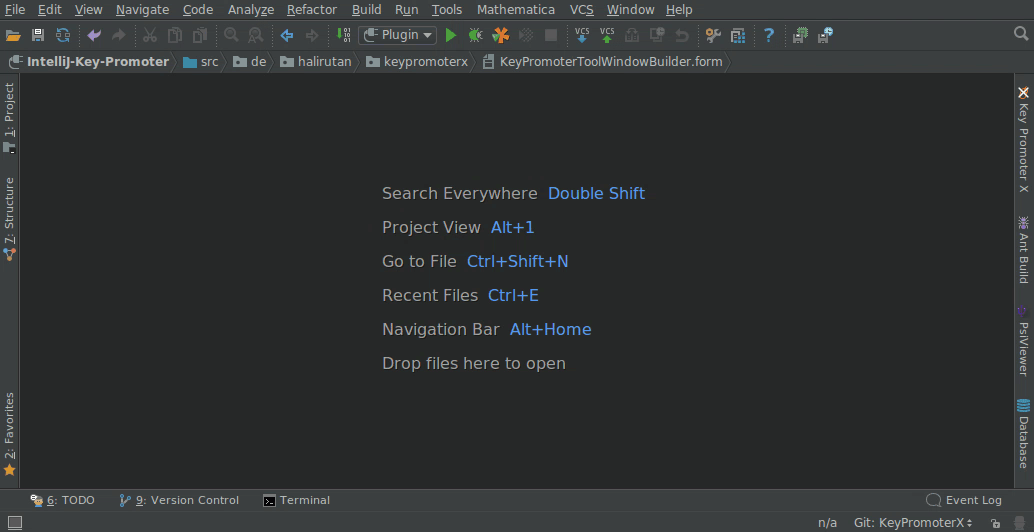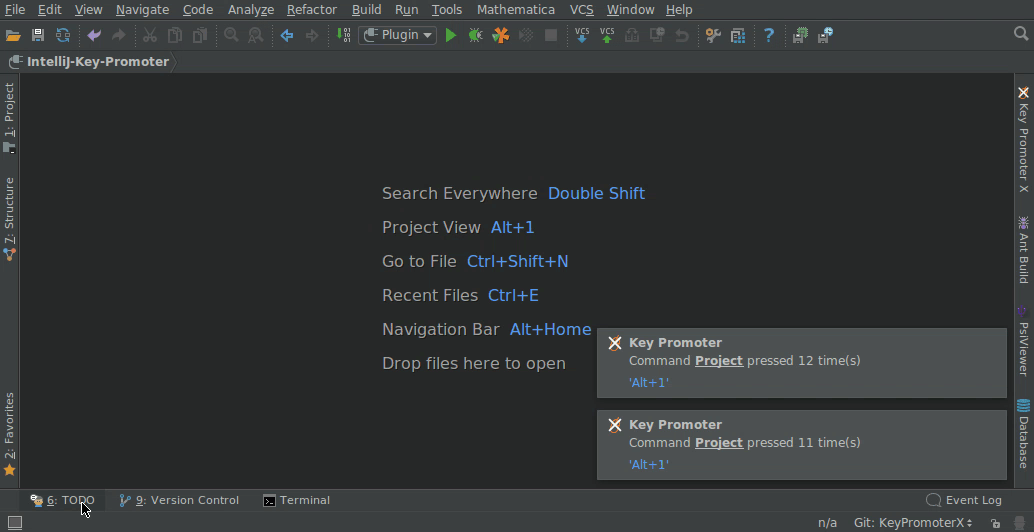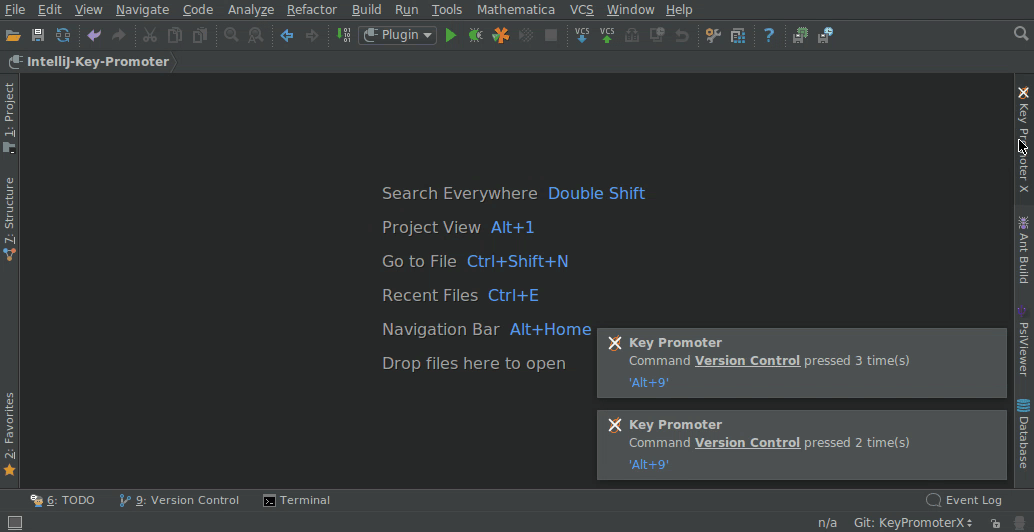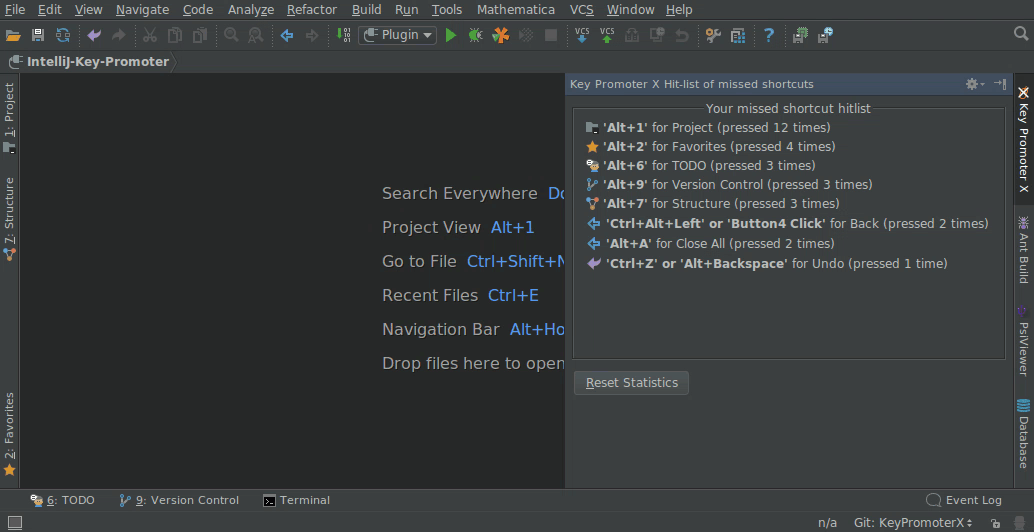
해당 Database 설정은 Project Data Sources을 통해서 프로젝트 단위로 설정할 수 있습니다. 만약 다양한 프로젝트에서 이 설정을 공유해서 사용하고 싶다면 빨간색 박스 버튼을 누르면 Project Data Sources를 Global로 설정할 수 있습니다.
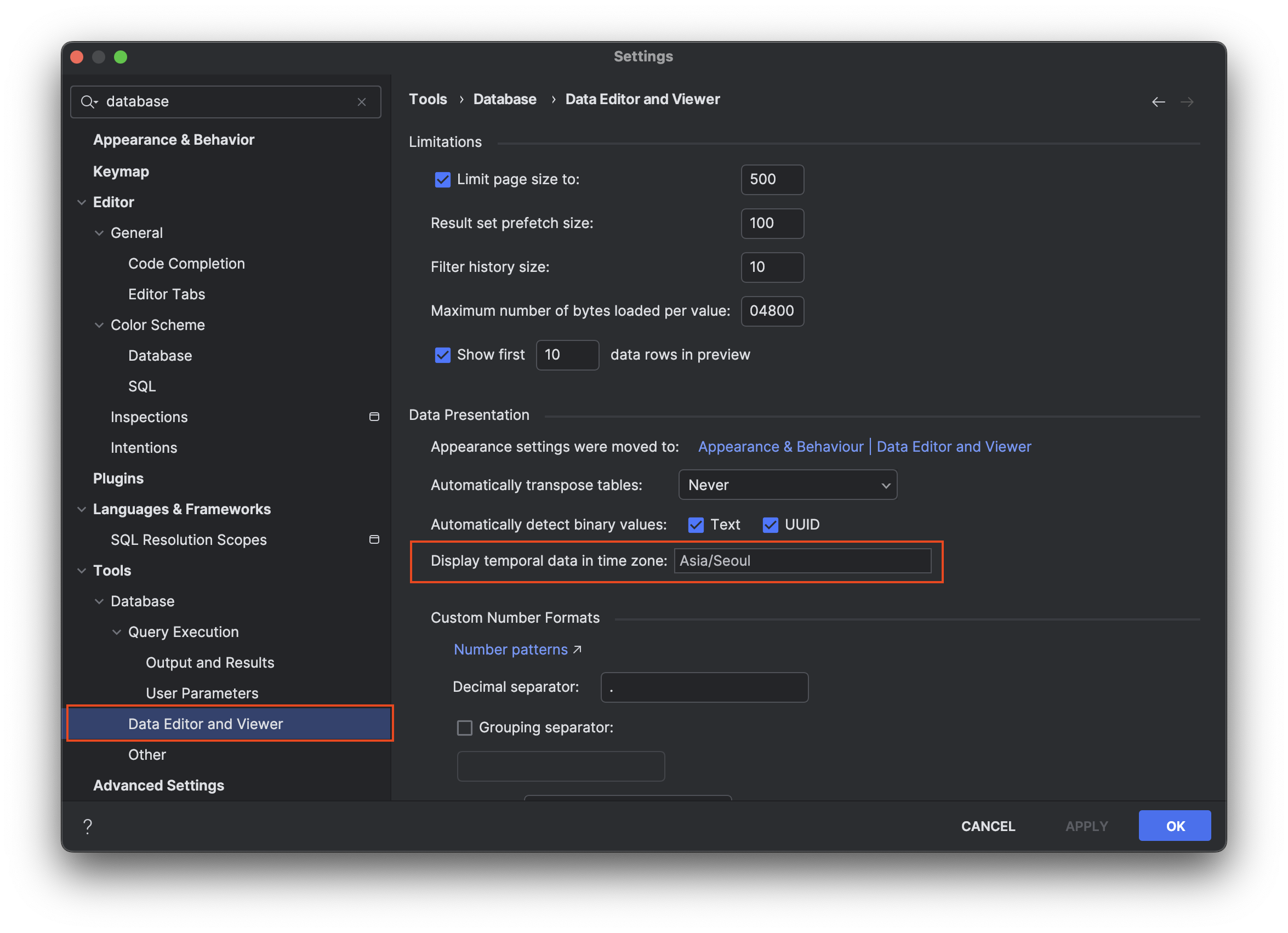
Database DateTime Format
데이터베이스에서 DateTime이 UTC 기준으로 저장되어 있을 때, 특정 지역의 시간대로 설정하여 데이터 조회를 보다 편리하게 할 수 있습니다. 이 설정은 Data Editor and Viewer에서 Display temporal data in time zone 옵션을 통해 원하는 지역의 시간대로 변경할 수 있습니다.
해당 설정을 한 이후 조회 쿼리를 실행하여 결과를 확인 해보면 Asia/Seoul 기준으로 출력되는 것을 확인할 수 있습니다.
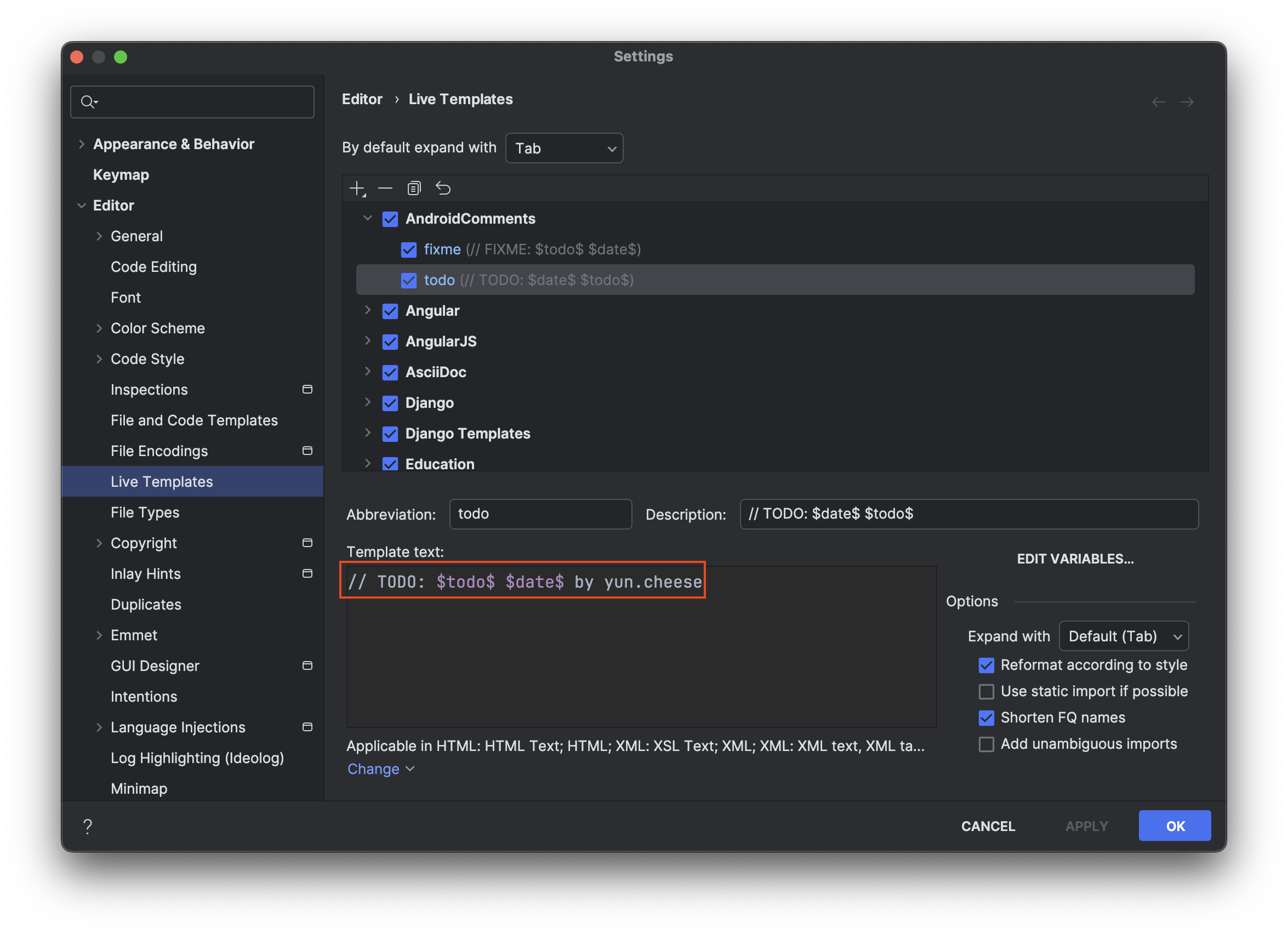
Live Template
1
// TODO: xxxx 2024-11-25 by yun.cheese
Live Template에서 TODO를 설정 하여 코드 작성시 자동으로 주석을 추가할 수 있습니다. 이런 경우 TODO 작성시 $END$를 통해 커서를 이동시킬 수 있습니다. 또한 작성 날짜를 추가하고 싶다면 Edit variables를 통해 Date를 추가할 수 있습니다. Data Formatter을 yyyy-MM-dd와 같이 설정할 수 있습니다.
]]>
<h2><span id="database-global">Database Global</span></h2>
<p><img src="https://raw.githubusercontent.com/cheese10yun/IntelliJ/master/assets
Spring Boot3 Kotlin JPA & Querydsl 적용하기https://cheese10yun.github.io/springboot3-jpa-querydsl/2023-12-23T14:00:00.000Z2023-12-23T13:56:34.355ZSpring Boot 2에서 3으로 업데이트되면서 Spring Data JPA 관련 설정이 변경된 부분들이 있습니다. 프로젝트에서 손쉽게 Spring Boot 3으로 업데이트하면서 Spring Data JPA와 Querydsl 설정을 손쉽게 하는 방법에 대해서 살펴보겠습니다.
사전 설정
1
$ ./gradlew wrapper --gradle-version=8.5
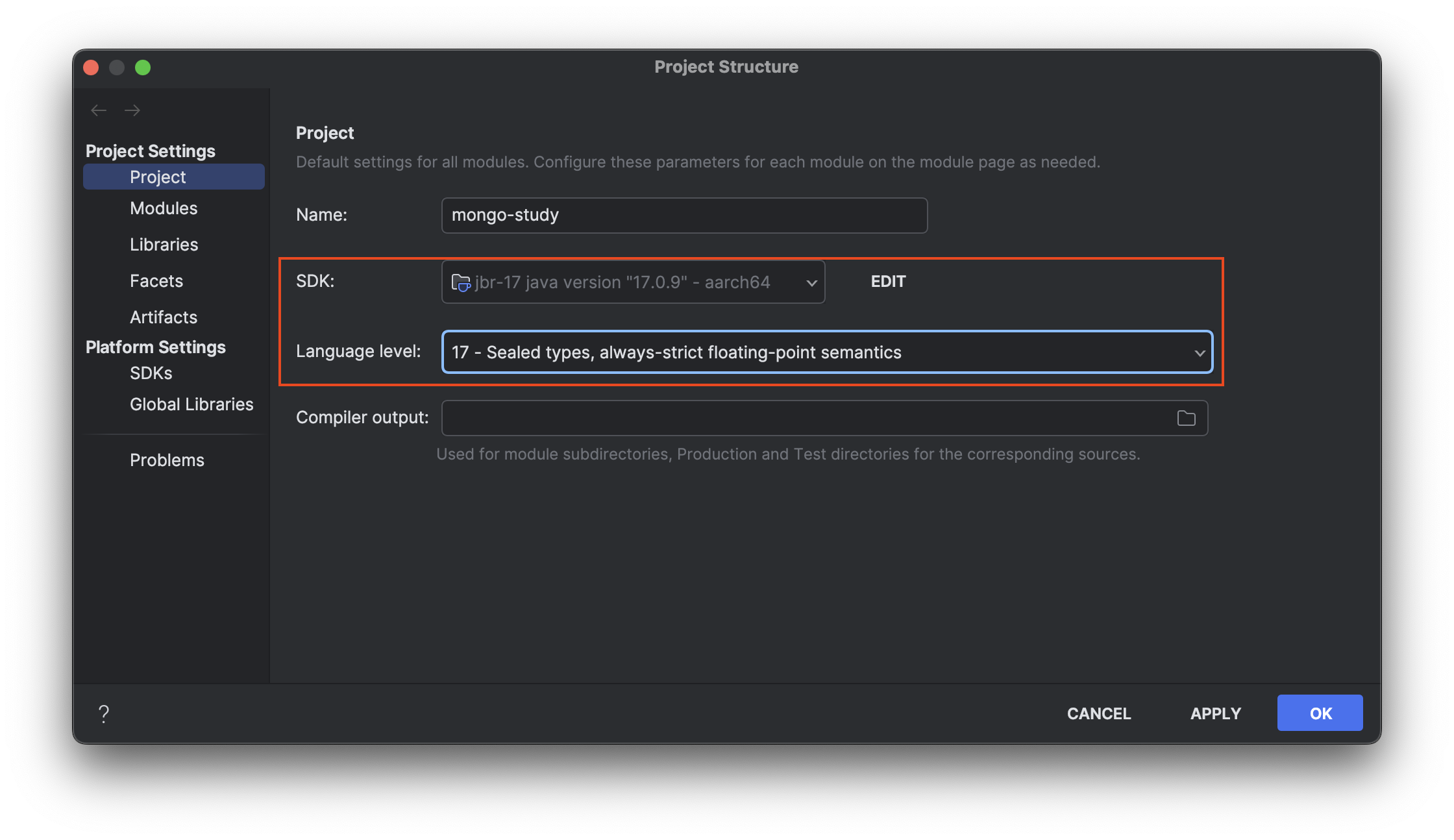
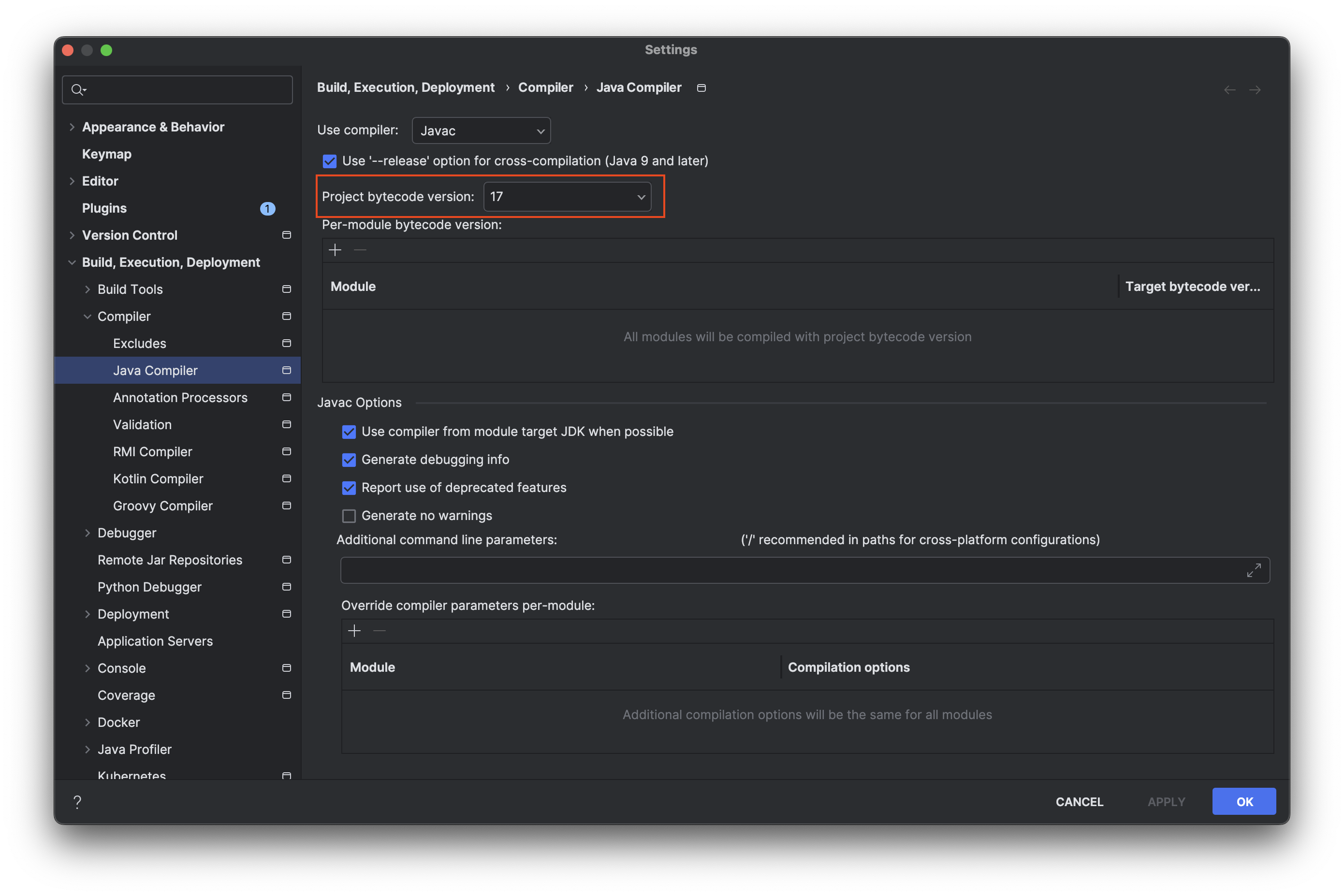
Gradle Wrapper를 사용하는 경우, 사용하고 있는 버전을 8.5 이상으로 업데이트 및 IntelliJ를 사용하는 경우 프로젝트의 SDK 버전을 17 이상으로 설정하는 과정을 진행합니다.
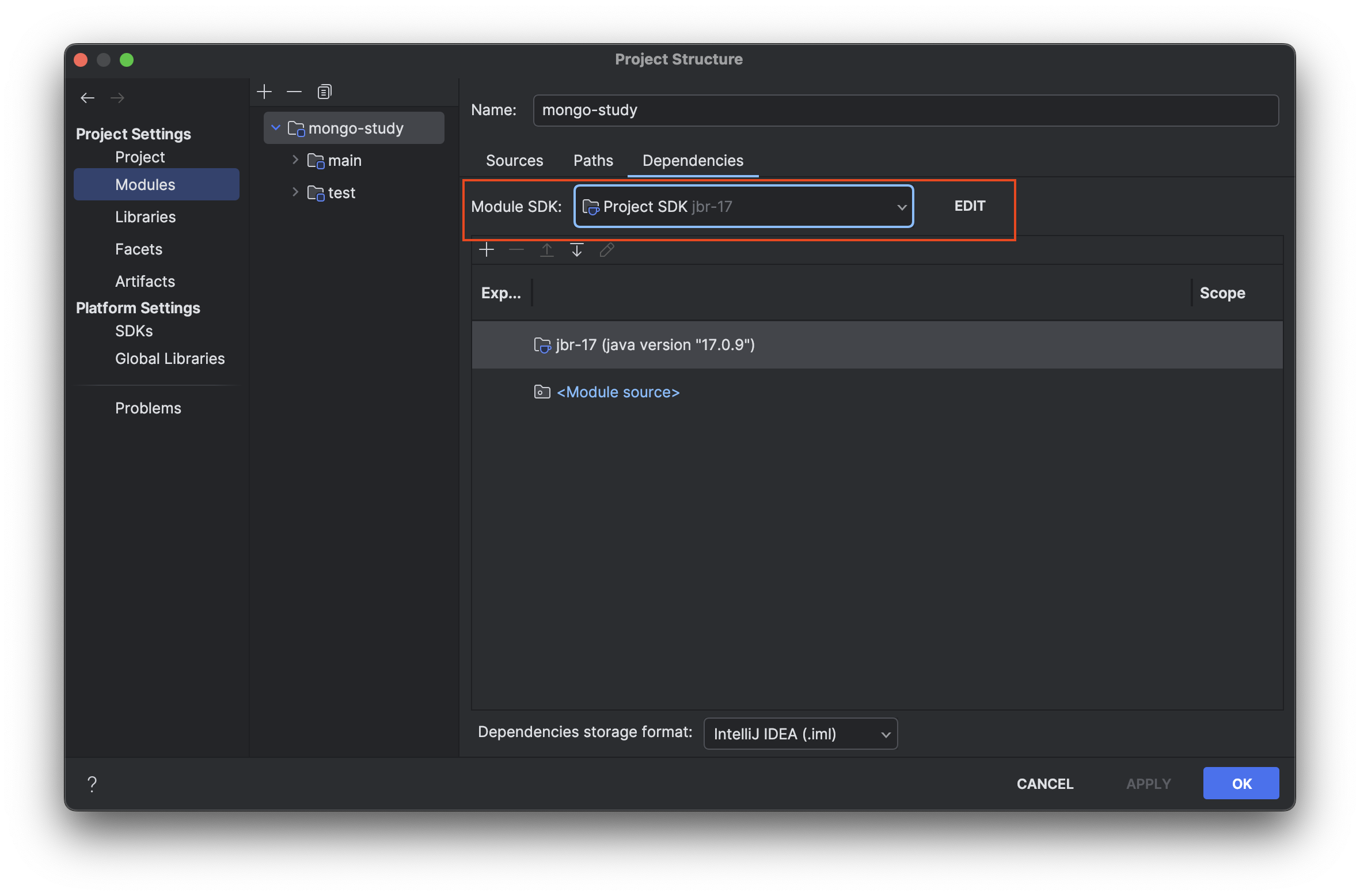
Project Structure 설정에서 SDK, Language Level을 17 버전 이상으로 지정합니다.
Module SDK 버전도 동일한 버전으로 설정합니다.
Gradle 마지막으로 gradle 버전도 동일한 버전으로 설정합니다.
build.gradle.kts
1 2 3 4 5 6 7
plugins { id("org.springframework.boot") version "3.2.1" id("io.spring.dependency-management") version "1.1.4" kotlin("jvm") version "1.9.21" kotlin("plugin.spring") version "1.9.21" kotlin("plugin.jpa") version "1.9.21" }
build.gradle.kts 설정에 각종 java version을 사전 설정과 동일한 버전으로 설정합니다.
Import Replace
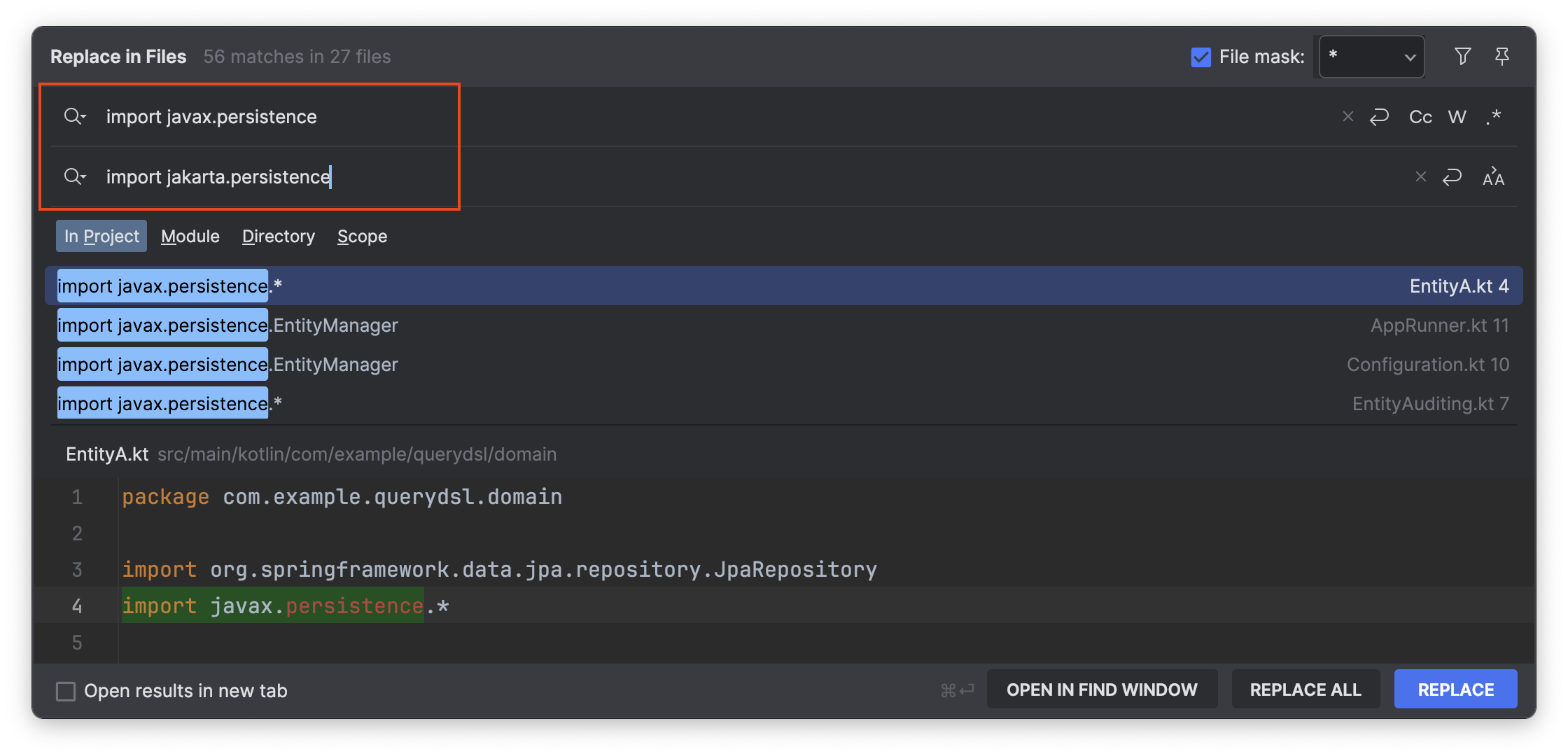
Spring Data JPA에서의 주요 변경사항 중 하나는 패키지 경로의 변경입니다. 이전에 사용되던 javax.persistence가 jakarta.persistence로 업데이트되었습니다. IntelliJ의 Replace 기능을 이용하면 프로젝트 내의 모든 import 경로를 쉽게 변경할 수 있습니다. cmd + shift + r 단축키로 Replace 설정을 할 수 있습니다.
import javax.persistence -> jakarta.persistence 작성한 이후 REPLACE 버튼으로 적용 합니다.
]]>
<p>Spring Boot 2에서 3으로 업데이트되면서 Spring Data JPA 관련 설정이 변경된 부분들이 있습니다. 프로젝트에서 손쉽게 Spring Boot 3으로 업데이트하면서 Spring Data JPA와 Querydsl 설정을 손쉽게 하는
IntelliJ cannot resolve symbol 에러 해결https://cheese10yun.github.io/intellij-cannot-resolve-symbol/2023-12-22T15:00:00.000Z2023-12-22T16:21:27.921Z자바에서 Lombok과 같은 라이브러리로 인한 cannot resolve symbol 오류는 대체로 SDK 버전 문제로 발생합니다. 이를 해결하기 위해서는 프로젝트 내의 SDK 버전을 일관되게 설정해야 합니다. 이 과정에서 여러 설정을 조정해야 하는데, 구체적인 SDK 설정 방법에 대해 안내해 드리겠습니다.
Project Settings 설정
Project 설정
Project Structure 설정에서 SDK, Language Level을 동일한 버전으로 설정합니다.
Modules 설정
Module SDK 버전도 동일한 버전으로 설정합니다.
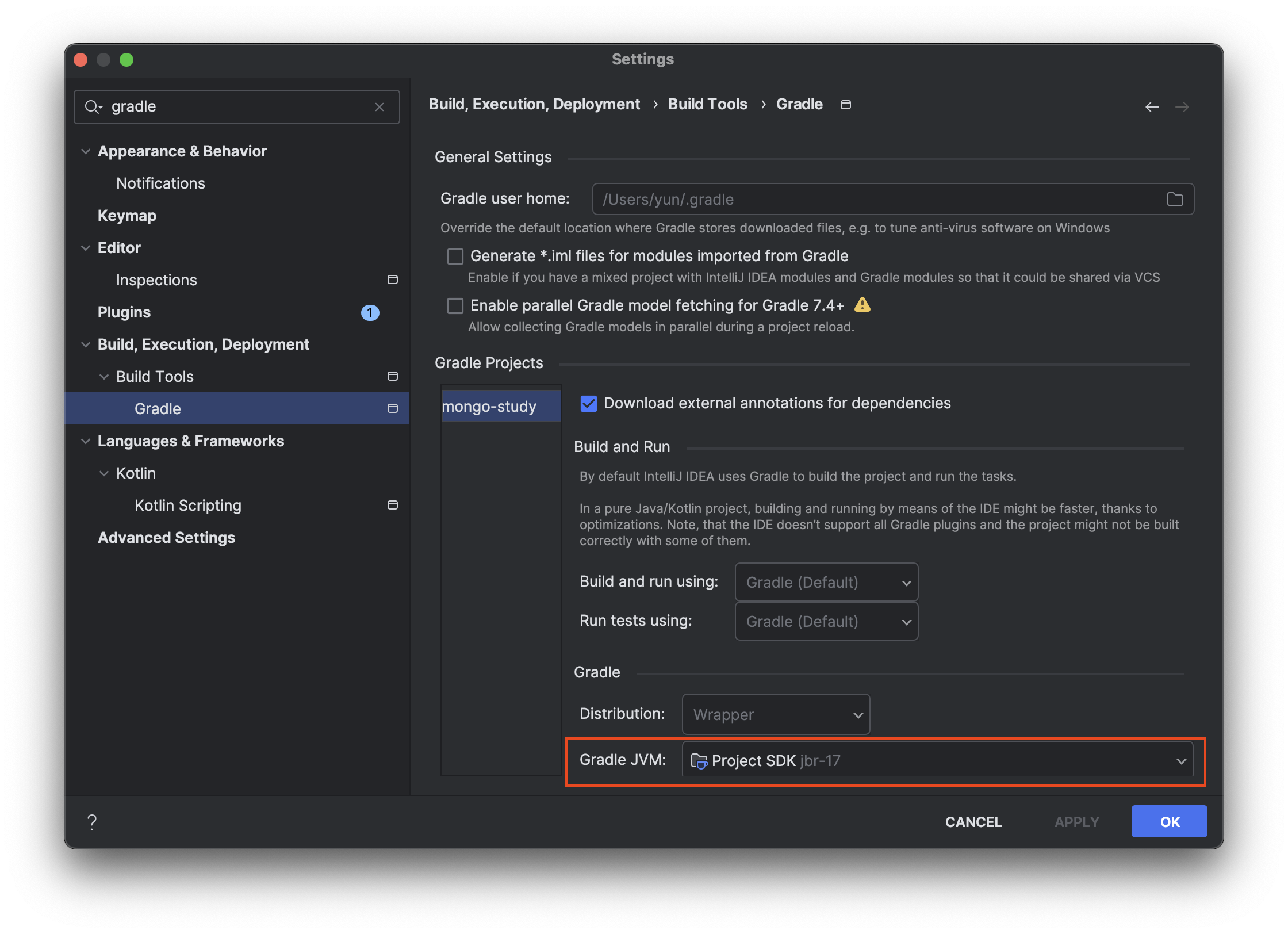
Gradle 설정
Gradle JVM SDK 버전도 동일하게 설정합니다.
Java Compiler 설정
Java Compiler 설정도 동일한 버전으로 설정합니다.
]]>
<p>자바에서 Lombok과 같은 라이브러리로 인한 <code>cannot resolve symbol</code> 오류는 대체로 SDK 버전 문제로 발생합니다. 이를 해결하기 위해서는 프로젝트 내의 SDK 버전을 일관되게 설정해야 합니다. 이 과정에서
MongoDB Update 성능 측정 및 분석https://cheese10yun.github.io/spring-data-mongodb-update-performance/2023-12-16T15:00:00.000Z2023-12-17T11:40:57.537ZMongoDB는 현대 웹 애플리케이션에서 널리 사용되는 NoSQL 데이터베이스입니다. 특히, Spring Data MongoDB는 Java 개발자에게 친숙하고 효율적인 방법으로 MongoDB와의 상호작용을 가능하게 합니다. 이번 포스팅에서는 Spring Data MongoDB를 사용하여 데이터를 업데이트하는 여러 방법의 성능을 비교하고 분석합니다. 특히, saveAll, updateFirst, bulkOps(UNORDERED), bulkOps(ORDERED) 이 네 가지 방법에 대해 깊이 있게 살펴보겠습니다.
이 코드는 Kotlin을 사용하여 MongoDB 문서에 대해 정의된 Member 클래스를 나타냅니다. 이 클래스에는 대략 11개의 필드가 정의되어 있으며, 테스트에 사용될 주요 필드는 name입니다. 이 Member 클래스는 Auditable 추상 클래스를 상속받아, MongoDB 문서의 생성 및 수정 시간을 자동으로 추적합니다. 테스트 과정에서는 name 필드만을 대상으로 업데이트 작업을 수행하고 성능을 평가할 예정입니다. 이를 통해 MongoDB에서 단일 필드 업데이트의 성능을 파악하고자 합니다.
saveAll
1 2 3 4
funupdateSaveAll(members: List<Member>) { // name 필드만 UUID.randomUUID().toString() 으로 업데이트 memberRepository.saveAll(members) }
saveAll 메서드는 Spring Data MongoDB의 CrudRepository 인터페이스에서 제공하는 메서드로, 여러 개의 문서를 데이터베이스에 저장하거나 업데이트하는 데 사용됩니다. 동작 방식은 다음과 같습니다.
ID 존재 여부에 따른 동작: saveAll 메서드는 전달된 Member 객체 리스트를 순회하면서 각 객체의 id 필드를 확인합니다.
ID가 없는 경우 (Insert): Member 객체에 id 필드가 null이거나 존재하지 않으면, 해당 객체는 새로운 문서로 간주되어 데이터베이스에 삽입됩니다.
ID가 있는 경우 (Update): 이미 id 필드가 있는 Member 객체는 해당 id를 가진 기존 문서를 업데이트합니다.
일괄 처리: 여러 객체를 포함하는 리스트를 한 번에 데이터베이스에 저장하거나 업데이트할 수 있는 이점이 있습니다.
이번 테스트에서는 saveAll 메서드를 사용하여 Member 객체의 name 필드를 업데이트하는 데 집중합니다. 테스트에 사용되는 모든 Member 객체는 이미 id를 가지고 있으므로, 이 메서드는 모든 객체를 데이터베이스에 업데이트하는 작업으로 처리합니다. 이를 통해 saveAll 메서드가 대량의 업데이트 작업을 얼마나 효과적으로 처리할 수 있는지 성능을 평가하고자 합니다.
updateFirst 메서드는 Spring Data MongoDB의 MongoTemplate을 사용하여 특정 조건을 만족하는 첫 번째 문서를 업데이트하는 기능을 제공합니다. 이 메서드는 주어진 쿼리에 따라 데이터베이스 내에서 일치하는 첫 번째 문서를 찾아 해당 필드를 업데이트합니다. 동작 방식은 다음과 같습니다.
쿼리 매칭: updateFirst는 Query 객체를 사용하여 업데이트할 문서를 찾습니다. 이 예제에서는 Criteria.where("_id").is(id)를 통해 특정 id 값을 가진 문서를 찾습니다.
업데이트 내용 지정: Update 객체를 사용하여 업데이트할 내용을 지정합니다. 여기서는 name 필드를 새롭게 생성된 무작위 UUID 문자열로 설정합니다.
첫 번째 일치 문서 업데이트: 쿼리에 일치하는 첫 번째 문서만 업데이트됩니다. 만약 일치하는 문서가 없으면 업데이트는 수행되지 않습니다.
결과 반환: 메서드는 UpdateResult를 반환하여 업데이트 작업의 결과를 나타냅니다. 이를 통해 몇 개의 문서가 영향을 받았는지 확인할 수 있습니다.
이번 테스트에서는 updateFirst 메서드를 사용하여 Member 클래스의 name 필드를 업데이트합니다. 테스트는 특정 id를 가진 Member 문서를 대상으로 하며, 이 메서드는 해당 문서의 name 필드를 새로운 값으로 업데이트합니다. 이 방법을 통해 updateFirst 메서드의 단일 문서 업데이트 성능을 평가하고자 합니다.
bulkOps
1 2 3 4 5 6 7 8 9 10 11 12 13
funupdateBulk( ids: List<ObjectId>, bulkMode: BulkOperations.BulkMode = BulkOperations.BulkMode.UNORDERED // or BulkOperations.BulkMode.ORDERED ): BulkWriteResult { val bulkOps = mongoTemplate.bulkOps(bulkMode, Member::class.java) for (id in ids) { bulkOps.updateOne( Query(Criteria.where("_id").`is`(id)), Update().set("name", UUID.randomUUID().toString()) ) } return bulkOps.execute() }
bulkOps 메서드는 Spring Data MongoDB의 MongoTemplate을 사용하여 대량의 업데이트 작업을 효율적으로 처리하는 방법을 제공합니다. bulkOps는 한 번의 연산으로 여러 업데이트 작업을 모아서 실행할 수 있으며, BulkMode에 따라 순서대로(ORDERED) 또는 순서에 구애받지 않고(UNORDERED) 실행할 수 있습니다. 동작 방식은 다음과 같습니다.
Bulk Operations 설정: bulkOps는 주어진 BulkMode와 문서 클래스(Member::class.java)를 기반으로 초기화됩니다.
업데이트 작업 추가: updateOne 메서드를 사용하여 각 id에 대한 업데이트 작업을 추가합니다. 여기서는 name 필드를 새로운 무작위 UUID 문자열로 설정합니다.
Bulk 작업 실행: execute 메서드를 호출하여 누적된 모든 업데이트 작업을 한 번에 실행합니다.
결과 반환: 메서드는 BulkWriteResult를 반환하여 대량 업데이트 작업의 결과를 나타냅니다.
이번 테스트에서는 bulkOps 메서드를 사용하여 Member 클래스의 name 필드를 대량으로 업데이트합니다. 여러 id를 가진 Member 문서에 대해 각각 name 필드를 새로운 값으로 업데이트하는 작업을 모아 한 번에 실행합니다. 이 방법을 통해 bulkOps 메서드의 대량 업데이트 성능과 UNORDERED와 ORDERED 모드 간의 성능 차이를 평가하고자 합니다.
BulkMode 차이점:
BulkOperations.BulkMode.UNORDERED:
작업들이 순서에 구애받지 않고 병렬적으로 처리됩니다.
성능 측면에서 더 효율적일 수 있으나, 하나의 작업 실패가 다른 작업에 영향을 미치지 않습니다.
대량의 독립적인 작업을 빠르게 처리해야 할 때 유용합니다.
BulkOperations.BulkMode.ORDERED:
작업들이 추가된 순서대로 처리됩니다.
하나의 작업이 실패하면 그 이후의 작업은 실행되지 않을 수 있습니다.
작업들 간의 순서가 중요한 경우에 적합합니다.
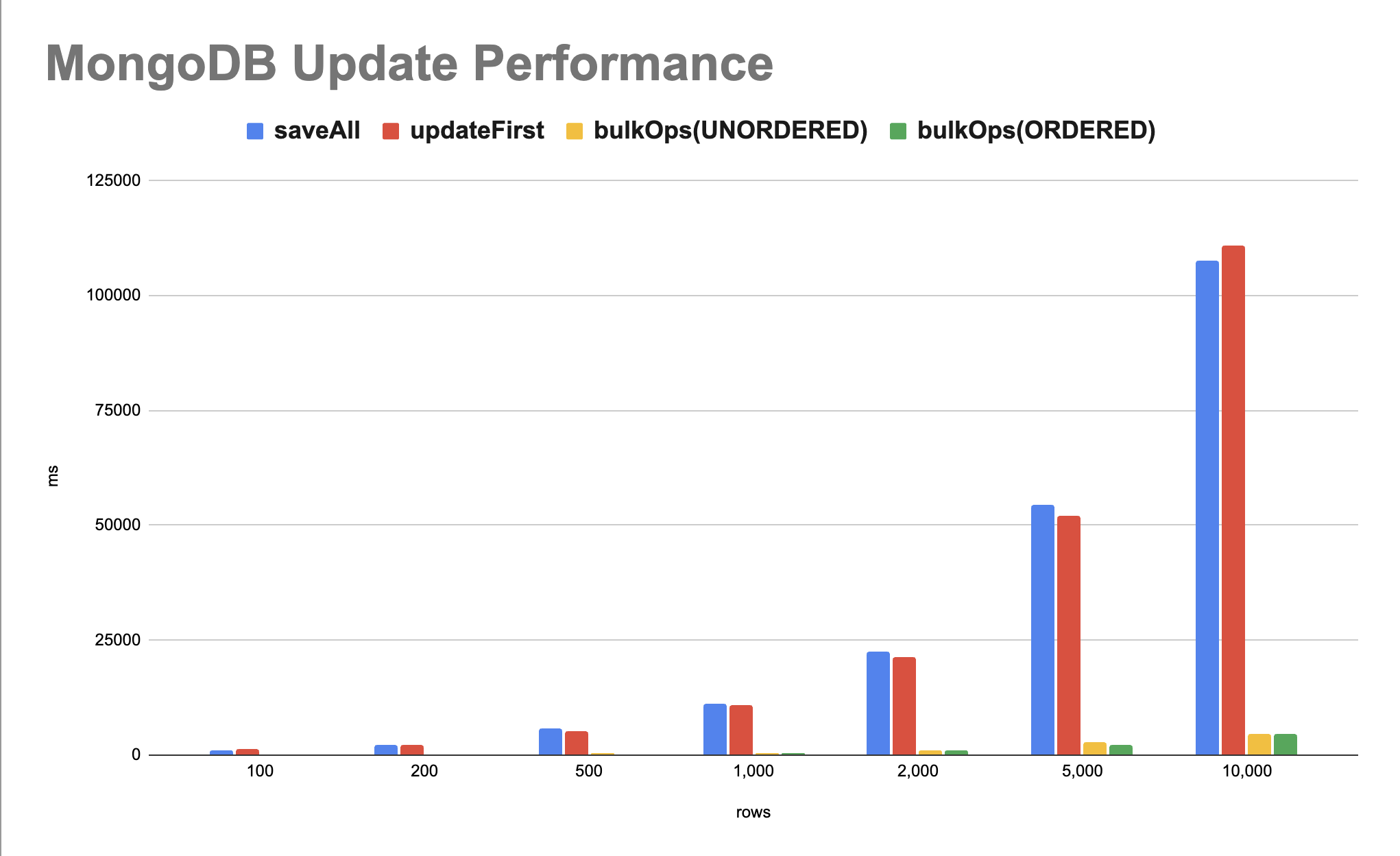
성능 측정 결과
rows
saveAll
updateFirst
bulkOps(UNORDERED)
bulkOps(ORDERED)
100
1,052 ms
1,176 ms
46 ms
79 ms
200
2,304 ms
2,196 ms
103 ms
124 ms
500
5,658 ms
5,250 ms
309 ms
257 ms
1,000
11,106 ms
10,846 ms
418 ms
412 ms
2,000
22,592 ms
21,427 ms
1,060 ms
1,004 ms
5,000
54,407 ms
52,075 ms
2,663 ms
2,292 ms
10,000
107,651 ms
110,884 ms
4,514 ms
4,496 ms
결과는 saveAll, updateFirst, bulkOps(UNORDERED), bulkOps(ORDERED) 네 가지 방법에 대해 다양한 행(rows) 수에 따라 수행 시간(밀리초)을 비교합니다.
분석 결과:
saveAll과updateFirst
이 두 방법은 유사한 성능을 보입니다. 행의 수가 증가함에 따라 수행 시간이 선형적으로 증가하는 경향을 보이며, 대량의 데이터를 처리할 때 상대적으로 높은 지연 시간을 가집니다.
saveAll과 updateFirst 메서드의 성능 차이는 유의미하지 않습니다. 따라서, 상대적으로 데이터 양이 적은 경우에는 upsert 기능을 제공하는 saveAll을 사용하여 로직을 단순화할 수 있습니다.
예제 코드에서는 updateFirst 메서드를 사용하여 기본 키(PK)를 기반으로 업데이트를 수행했습니다. 그러나 다른 키 값으로 조회를 진행할 경우, 조회 속도가 느려져 성능 차이가 발생할 수 있습니다.
saveAll 메서드는 Member 객체의 모든 변경 사항을 반영합니다. 따라서, 특정 필드만을 명확하게 업데이트하고자 할 때는 updateFirst와 같은 메서드를 사용하여 정확한 업데이트 쿼리를 작성하는 것이 좋은 대안이 될 수 있습니다. 이 방법은 업데이트하고자 하는 필드를 직접 지정할 수 있어, 더 세밀한 데이터 업데이트 제어가 가능합니다.
bulkOps(UNORDERED)와 bulkOps(ORDERED)
이 방법들은 saveAll과 updateFirst에 비해 현저히 빠른 성능을 보입니다. 특히 bulkOps(UNORDERED)는 가장 빠른 처리 시간을 나타냅니다.
bulkOps(UNORDERED)는 순서에 구애받지 않고 여러 작업을 동시에 처리할 수 있기 때문에, 대량의 데이터 처리에 더 효율적이며, 개별 작업들이 독립적으로 처리됩니다. 이는 특정 작업이 실패해도 다른 작업들에 영향을 주지 않는다는 것을 의미합니다.
bulkOps(ORDERED)도 비교적 빠른 성능을 보이지만, bulkOps(UNORDERED)에 비해 약간 느린 경향이 있습니다. 이는 작업을 순서대로 처리해야 하는 부가적인 비용 때문 이며, 순차적으로 작업이 진행되기 때문에 한 작업이 실패하면 그 이후의 작업은 실행되지 않을 수 있습니다.
bulkOps(UNORDERED)와 bulkOps(ORDERED) 방식은 10,000개의 데이터 모수까지는 큰 성능 차이가 나타나지 않았습니다. 그러나 데이터가 많은 노드에 분산되어 저장된 경우, 이 두 방식 사이에서 더 유의미한 성능 차이가 발생할 수 있습니다. 분산 환경에서는 데이터의 위치와 네트워크 지연이 성능에 영향을 미칠 수 있으며, 이러한 조건에서는 bulkOps(UNORDERED)와 bulkOps(ORDERED)의 처리 방식 차이가 더 명확하게 드러날 가능성이 있습니다.
결론
소량의 데이터를 업데이트할 때는 saveAll과 updateFirst 메서드가 적합할 수 있습니다. 하지만 데이터 양이 많아질수록 이 두 방법의 성능은 상대적으로 감소합니다. 데이터 모수가 적은 경우, saveAll과 updateFirst 각각의 장단점이 있으므로, 특정 환경과 요구사항에 맞게 적절한 메서드를 선택하는 것이 중요합니다.
대량의 데이터 처리에는 bulkOps 메서드 사용이 효율적입니다. bulkOps(UNORDERED)와 bulkOps(ORDERED) 각각의 장단점이 존재하므로, 이 두 방식 중에서는 특정 환경과 요구사항에 맞게 적절한 옵션을 선택하는 것이 중요합니다.
이러한 결과는 MongoDB 데이터 업데이트 전략을 선택할 때 중요한 고려 사항을 제공합니다. 데이터의 양, 업데이트의 복잡성, 순서의 중요성 등을 고려하여 적절한 방법을 선택할 필요가 있습니다.
bulkOps 편의 기능 제공
이전 포스팅인 Spring Data MongoDB Repository 확장에서는 MongoCustomRepositorySupport를 사용해 MongoRepository에 편의 기능을 추가하고, 보일러플레이트 코드를 줄이는 방법을 소개했습니다. 이 방법은 코드의 재사용성을 높이는 효과가 있습니다. 마찬가지로, bulkOps와 같은 반복적인 코드도 MongoCustomRepositorySupport에 통합함으로써 더 편리하게 기능을 제공할 수 있습니다. 이렇게 하면 bulkOps 관련 코드를 중앙화하여 관리 및 사용의 용이성을 향상시킬 수 있습니다.
fun `updateNmae 사용하는 곳`(pairs: List<Pair<() -> Query, () -> Update>>, bulkMode: BulkOperations.BulkMode) { val pair = listOf( Pair( first = { Query(Criteria.where("_id").`is`(ObjectId("id"))) }, second = { Update().set("name", UUID.randomUUID().toString()) } ) ) memberRepository.updateName(pair, BulkOperations.BulkMode.UNORDERED) }
코드는 외부에서 정의된 쿼리와 업데이트 로직을 사용하여 데이터 업데이트를 수행합니다. 코드는 Pair 리스트를 통해 각 업데이트 작업에 필요한 Query와 Update 객체를 정의하고, 이를 memberRepository의 updateName 메서드에 전달하여 BulkOperations.BulkMode.UNORDERED 모드로 업데이트를 진행합니다. 이 방식은 업데이트 과정을 유연하게 처리할 수 있게 해줍니다.
]]>
<p>MongoDB는 현대 웹 애플리케이션에서 널리 사용되는 NoSQL 데이터베이스입니다. 특히, Spring Data MongoDB는 Java 개발자에게 친숙하고 효율적인 방법으로 MongoDB와의 상호작용을 가능하게 합니다. 이번 포스팅에서는 Sp
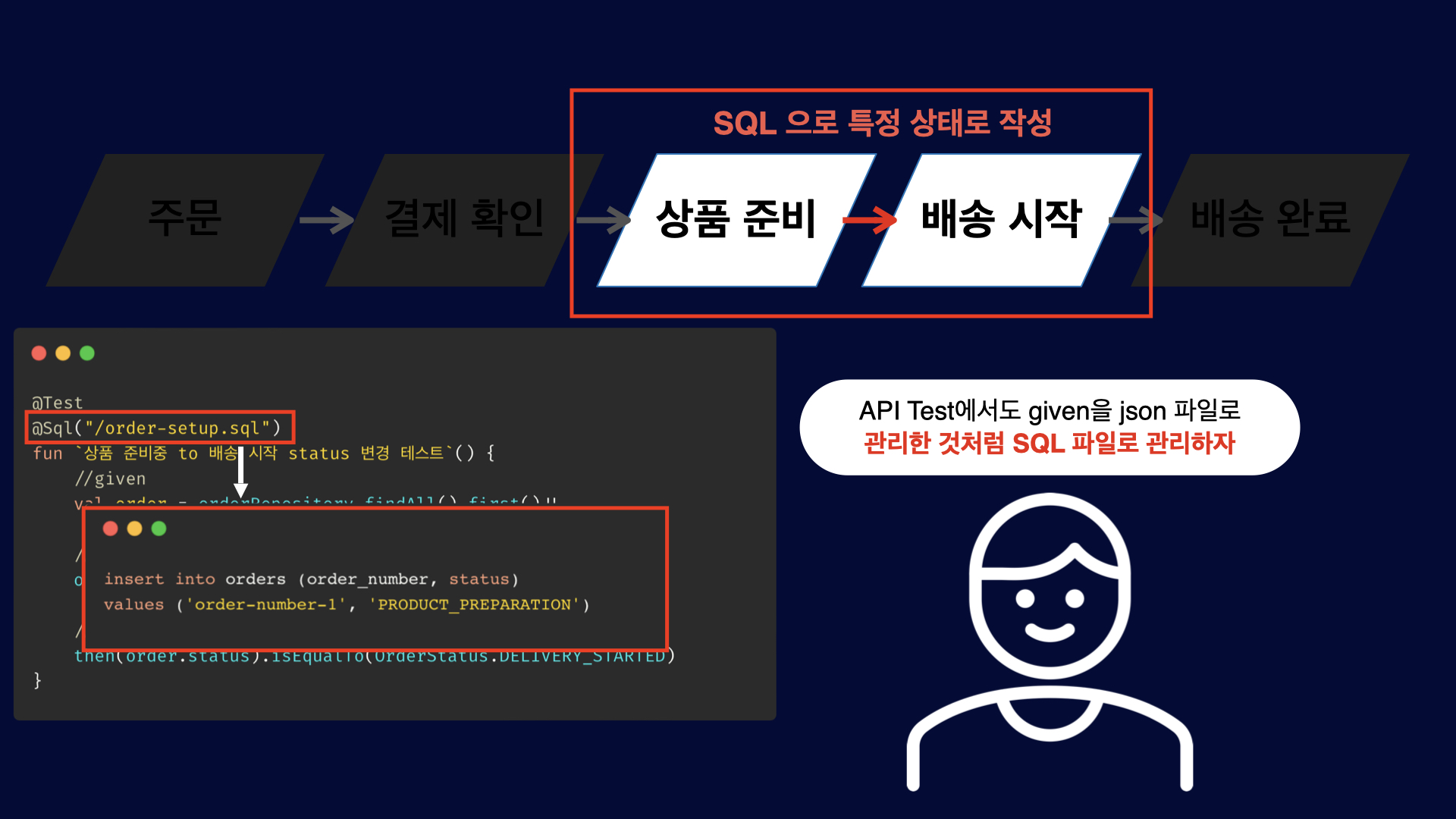
MongoDB 다양한 테스트 케이스를 커버할 수 있는 테스트 데이터 셋업 방법https://cheese10yun.github.io/spring-data-mongo-test-setup/2023-11-11T15:00:00.000Z2023-12-23T13:55:20.892Z테스트 코드의 가치가 널리 인정받으며, 이제 그 필요성을 언급하는 것은 의미가 없어졌습니다. 테스트 코드의 가장 큰 매력은 바로 구현 코드에 대한 실시간 피드백을 제공하고, 이를 바탕으로 구현 코드를 지속적으로 개선해 나갈 수 있다는 점입니다. 이 개념은 "실무에서 적용하는 테스트 코드 작성 방법과 노하우 Part 2: 테스트 코드로부터 피드백 받기"사내 기술 블로그에 이미 다룬 바 있습니다. 폭넓은 테스트를 작성하고 실행하기 위해서는 테스트 코드의 간편한 작성이 필수적입니다. 본 포스팅에서는 Spring Data MongoDB를 사용하여 Given 절의 데이터 셋업을 쉽게 하는 방법을 소개하겠습니다.
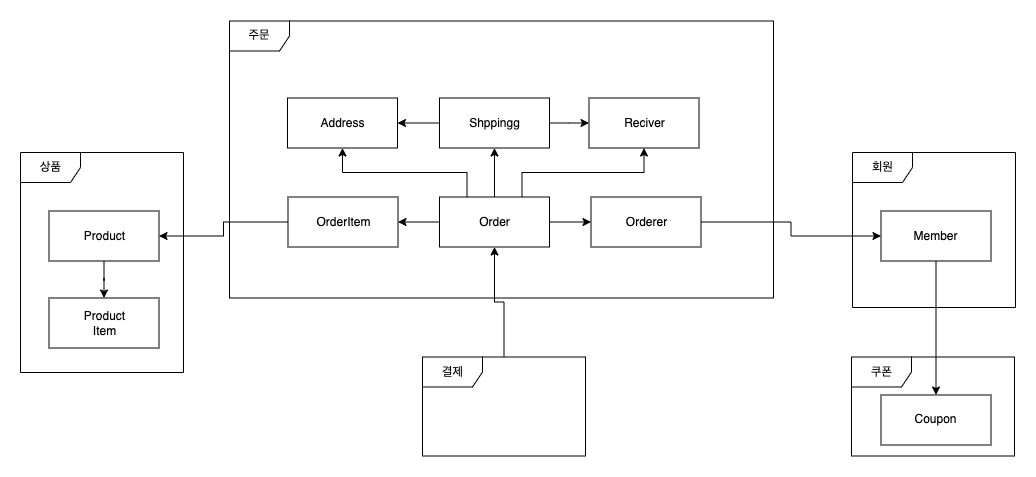
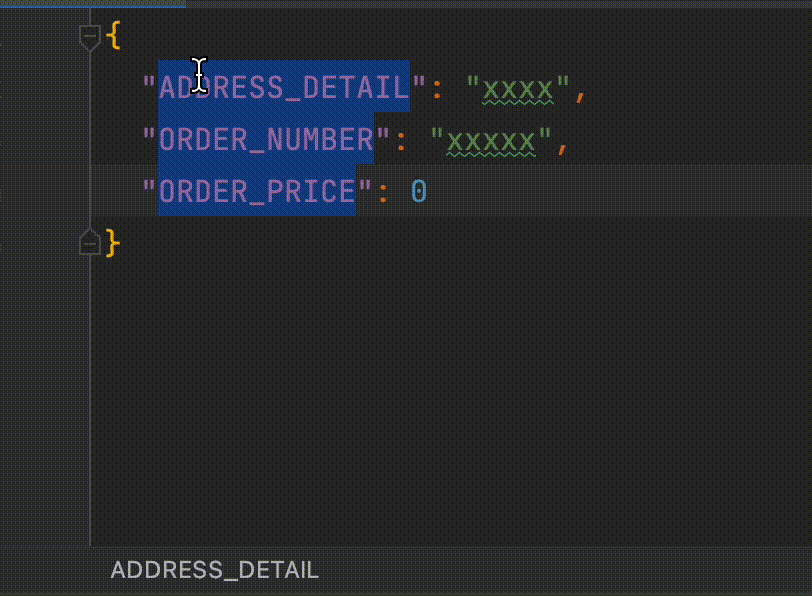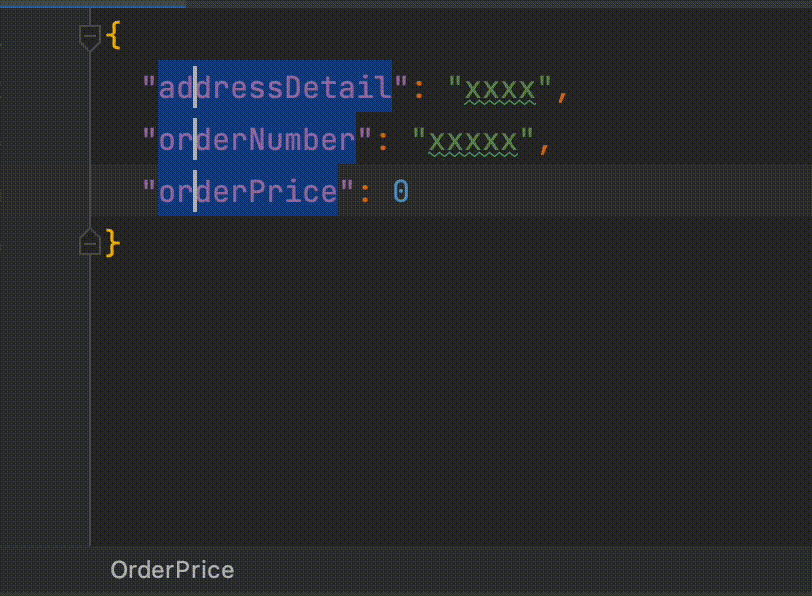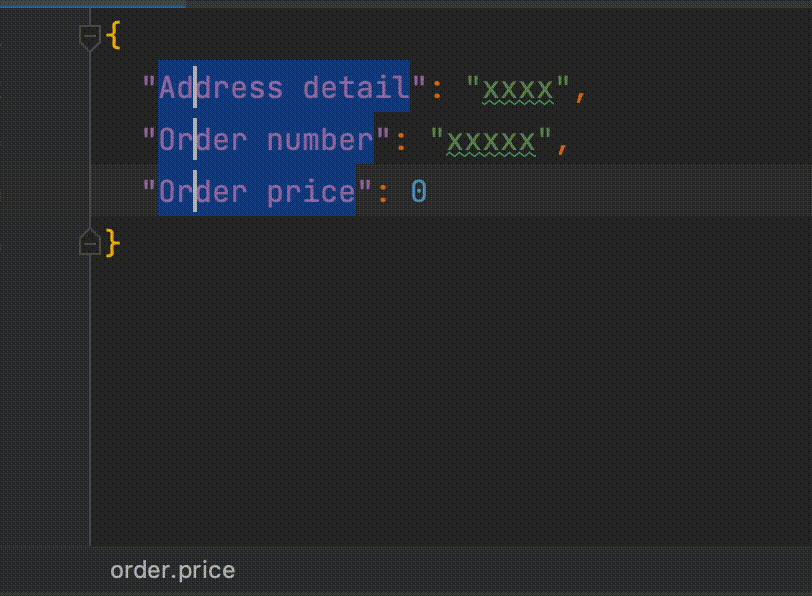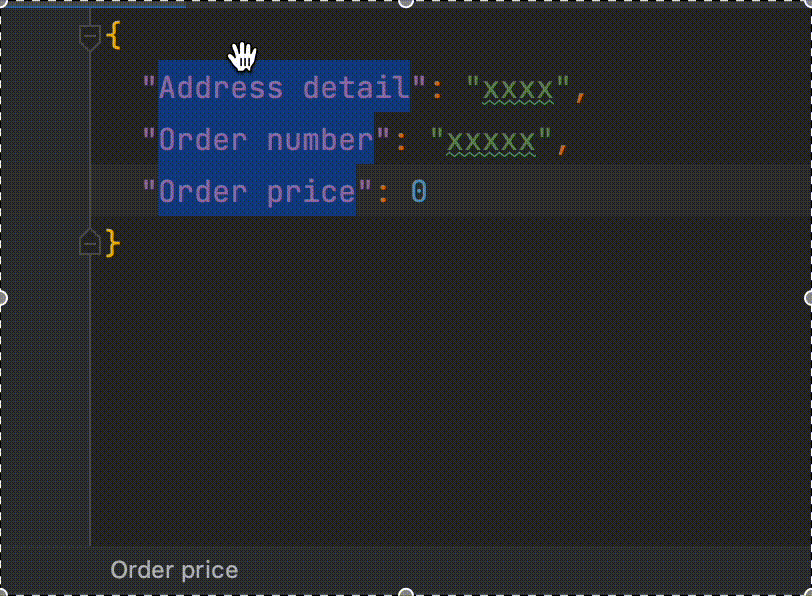
데이터 셋업의 어려움과 중요성
위 이미지처럼 주문 테스트 코드에 대한 다양한 테스트 케이스를 작성하기 위해서는 다양한 데이터를 셋업 하는 것은 필수적입니다. 다양한 테스트 케이스를 작성하지 못하면 테스트 케이스가 커버하는 범위가 좁아지며, 이로 인해 테스트 코드로부터 양질의 피드백을 받을 수 없게 됩니다. 따라서, 테스트 코드를 쉽게 작성하고 다양한 시나리오를 손쉽게 검증할 수 있는 환경을 만드는 것이 중요합니다.
스프링에서는 @Sql 어노테이션을 이용해 테스트 데이터를 간단히 셋업 할 수 있으며, 이를 통해 테스트 케이스를 원활하게 확장할 수 있습니다. 이에 관한 자세한 방법은 Sql을 통해서 테스트 코드를 쉽게 작성하자" 포스팅에서 설명하고 있습니다. 해당 포스팅에서는 Sql을 활용하여 다양한 테스트 데이터를 쉽게 구성하는 방법을 제공합니다.
(1): @MongoTestSupport 설정을 통해서 테스트 실행 리스너로 추가하여 데이터 설정을 자동화합니다.
(2): @MongoDataSetup은 해당 JSON 파일일을 읽어 MongoDB에 삽입합니다.
(3): jsonPath은 test/resources/ 디렉토리에 위치한 JSON 파일의 경로를 지정합니다. 마지막으로,
(4): MongoDB에 삽입할 문서의 클래스를 명시합니다.
@MongoDataSetup 어노테이션을 사용하면, JSON 파일을 통해 MongoDB 테스트 데이터를 간편하게 설정할 수 있으며, 테스트 실행 시 Foo Document 객체가 성공적으로 저장되어 조회되는 것을 확인할 수 있습니다.
테스트 데이터 셋업 코드
MongoDataSetup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** * @param jsonPath json file의 경로를 작성한다. * @param clazz MongoDB에 저장할 Document 객체 * @param collectionName [clazz]와 Document collection 이름이 다른 경우 명시, 명시하지 않는 경우 [clazz]의 Document의 collection 으로 저장 * * @see com.example.mongostudy.MongoDataSetupExecutionListenerTest.mongoDataSetup * @see com.example.mongostudy.MongoDataSetupExecutionListenerTest.mongoDataSetupCollectionName */ @Target(AnnotationTarget.FUNCTION) @Retention(AnnotationRetention.RUNTIME) annotationclassMongoDataSetup( val jsonPath: String, val clazz: KClass<*>, val collectionName: String = "" )
단일 문서 데이터 셋업에 사용됩니다.
1 2 3 4 5 6 7 8 9
/** * 여러 데이터를 셋업이 필요한 경우 * @param mongoDataSetup * * @see com.example.mongostudy.MongoDataSetupExecutionListenerTest.mongoDataSetups */ @Target(AnnotationTarget.FUNCTION, AnnotationTarget.ANNOTATION_CLASS) @Retention(AnnotationRetention.RUNTIME) annotationclassMongoDataSetups(varargval mongoDataSetup: MongoDataSetup)
/** * 테스트 이전에 [MongoDataSetup]기반으로 Document를 생성한다. */ overridefunbeforeTestMethod(testContext: TestContext) { val currentTestMethod = testContext.testMethod val mongoDataSetup = currentTestMethod.getAnnotation(MongoDataSetup::class.java) val mongoDataSetups = currentTestMethod.getAnnotation(MongoDataSetups::class.java) when { mongoDataSetup != null -> insertDocuments(mongoDataSetup, testContext) mongoDataSetups != null -> mongoDataSetups.mongoDataSetup.forEach { document -> insertDocuments(document, testContext) } } }
/** * 테스트가 끝난 이후 모든 모든 데이터를 삭제한다. */ overridefunafterTestMethod(testContext: TestContext) { val mongoTemplate = mongoTemplate(testContext) val currentTestMethod = testContext.testMethod val mongoDataSetup = currentTestMethod.getAnnotation(MongoDataSetup::class.java) val mongoDataSetups = currentTestMethod.getAnnotation(MongoDataSetups::class.java)
MongoDataSetupExecutionListener는 TestExecutionListener를 상속받아 구현되며, 스프링의 테스트 컨텍스트 프레임워크를 사용합니다. 이 리스너는 beforeTestMethod와 afterTestMethod 이벤트를 활용해 테스트 메소드 실행 전에 데이터를 준비하고, 실행 후에 데이터를 정리하는 기능을 수행합니다. 이 리스너는 TestContext에 의존하여 테스트 애플리케이션 컨텍스트에서 Bean을 쉽게 가져올 수 있으며, 예시에서는 MongoTemplate를 추출하는 데 사용되며 테스트 환경을 설정하거나, 테스트 데이터를 초기화하거나, 테스트 결과를 정리하는 등의 작업을 자동화하는 데 유용합니다.TestExecutionListener 인터페이스를 구현하고, 스프링의 테스트에 @TestExecutionListeners 어노테이션을 사용하여 리스너를 등록함으로써 활용할 수 있습니다.
MongoDataSetupExecutionListener는 테스트에 필요한 리스너로, TestExecutionListeners 어노테이션을 통해 등록합니다. 이 과정을 단순화하기 위해 MongoTestSupport 어노테이션을 생성하여, TestExecutionListeners 설정을 손쉽게 적용할 수 있도록 합니다.
dataclassFooProjection( @Field("address_detail") var addressDetail: String, @Field("created_at") val createdAt: LocalDateTime, @Field("updated_at") val updatedAt: LocalDateTime )
@MongoDataSetup( jsonPath = "/mongo-document-foo-projection.json", clazz = FooProjection::class, collectionName = "foo" ) @Test @DisplayName("collectionName 기반으로 테스트") funmongoDataSetupCollectionName() { // when val fooDocuments = mongoTemplate.findAll<Foo>()
@SpringBootTest 어노테이션을 사용하는 테스트 클래스에 @MongoTestSupport를 추가함으로써, 개별 테스트 클래스에서 어노테이션을 중복하여 작성할 필요 없이 모든 테스트에 적용될 수 있으며, 이를 통해 Application Context를 효율적으로 재사용할 수 있습니다. 이러한 방식은 공통적인 설정을 일관되게 관리하는 데에도 도움이 됩니다.
@MongoDataSetup 적절한 사용
@Sql 방식과 마찬가지로, JSON 파일 기반의 데이터 셋업에는 단점이 있습니다. 코드 내에서 객체를 생성하면 변수명과 주석을 통해 명확한 컨텍스트를 제공할 수 있는 반면, JSON 방식은 이러한 세부 사항을 전달하기 어렵습니다. 또한, Document 클래스의 코드 변경 시 관련 JSON 파일을 수동으로 업데이트해야 하는 번거로움이 있습니다.
@MongoDataSetup을 사용한 데이터 셋업은 주로 대량의 데이터나 복잡한 데이터 조합이 필요한 로직을 테스트할 때 추천됩니다. 이런 케이스에서는 코드로 직접 작성할 경우 유지보수 비용이 증가하고, 변수명과 주석을 통한 컨텍스트 전달에 한계가 있기 때문에, 이러한 상황에서 @MongoDataSetup의 사용이 효과적입니다.
마무리
이 포스팅에서는 MongoDB 데이터를 쉽게 설정하는 방법을 소개했지만, 강조하고 싶은 주요 메시지는 테스트 코드의 중요성과 함께 테스트 환경 구성의 중요성입니다.다양한 테스트 케이스를 작성할 수 있는 환경이 준비되어야만, 테스트 코드를 통해 유의미한 피드백을 얻고, 이를 통해 로직을 검증하고 코드 품질을 향상시킬 수 있습니다.
]]>
<p>테스트 코드의 가치가 널리 인정받으며, 이제 그 필요성을 언급하는 것은 의미가 없어졌습니다. 테스트 코드의 가장 큰 매력은 바로 구현 코드에 대한 실시간 피드백을 제공하고, 이를 바탕으로 구현 코드를 지속적으로 개선해 나갈 수 있다는 점입니다.
Spring Data MongoDB Repository 확장https://cheese10yun.github.io/spring-data-mongo-repository/2023-11-04T09:04:32.144Z2023-11-11T01:08:40.023ZSpring Data JPA에서 흔히 사용하는 Repository 확장 패턴을 Spring Data MongoDB에도 적용할 수 있습니다. 이 패턴은 'CustomRepository’와 'CustomRepositoryImpl’의 조합으로 구성되며, Spring-JPA Best Practices step-15에서 이전에 포스팅한적 있습니다. 이 방법을 사용하면 복잡한 조회 작업을 'CustomRepositoryImpl’에서 처리할 수 있게 됩니다. 이 구조를 사용하면, 사용자는 Repository 인터페이스만을 이용하여 데이터를 조회할 수 있게 되어 코드의 간결성과 유지보수성이 향상됩니다. 예를 들어, CustomRepositoryImpl에서 복잡한 쿼리 로직을 구현하면, 상위 레벨에서는 이러한 구현 디테일을 신경 쓰지 않고 데이터 접근 로직을 단순화할 수 있습니다. Spring Data MongoDB에서 동일하게 적용하는 방법을 살펴보겠습니다.
Custom Repository
Custom Repository 구성
1 2 3 4 5 6 7 8 9 10 11 12 13 14
@Document(collection = "members") classMember( @Field(name = "name") val name: String,
@Field(name = "email") val email: String ) : Auditable()
코드의 각 부분은 MongoDB를 사용하는 스프링 애플리케이션에서 도메인 객체를 정의하고, 저장소를 구성하는 데 필요한 요소들을 포함하고 있습니다. 아래는 코드 구조를 기반으로 한 정리입니다:
Member - MongoDB의 members 컬렉션에 매핑되는 도메인 객체입니다. name과 email 필드를 가지고 있으며, 각 필드는 MongoDB의 문서 필드에 맞추어 @Field 애노테이션을 사용하여 지정되어 있습니다.
MemberRepository - MongoDB의 기본 CRUD 작업을 위한 MongoRepository와 사용자 정의 쿼리를 위한 MemberCustomRepository, Querydsl 지원을 위한 QuerydslPredicateExecutor를 확장하는 저장소 인터페이스입니다. 이로 인해 Member 객체에 대한 표준 데이터 접근 패턴과 함께 복잡한 쿼리 기능을 제공합니다.
MemberCustomRepository - 사용자 정의 쿼리를 위한 인터페이스로, 실제 사용자 정의 로직을 위한 메소드의 시그니처를 포함할 수 있습니다.
MemberCustomRepositoryImpl - MemberCustomRepository의 구현체로, 실제 사용자 정의 쿼리 로직을 실행하는 메소드를 포함합니다. MongoTemplate을 주입받아 MongoDB의 복잡한 작업을 처리하는 데 사용됩니다.
이 구성을 통해, 애플리케이션은 MongoDB에 대한 데이터 액세스를 추상화하고 효율적으로 관리할 수 있으며, MemberRepository를 통해 비즈니스 로직에 맞는 복잡한 데이터 접근 패턴을 구현할 수 있어 애플리케이션의 유연성을 증가시키고 코드의 관리를 간소화합니다.
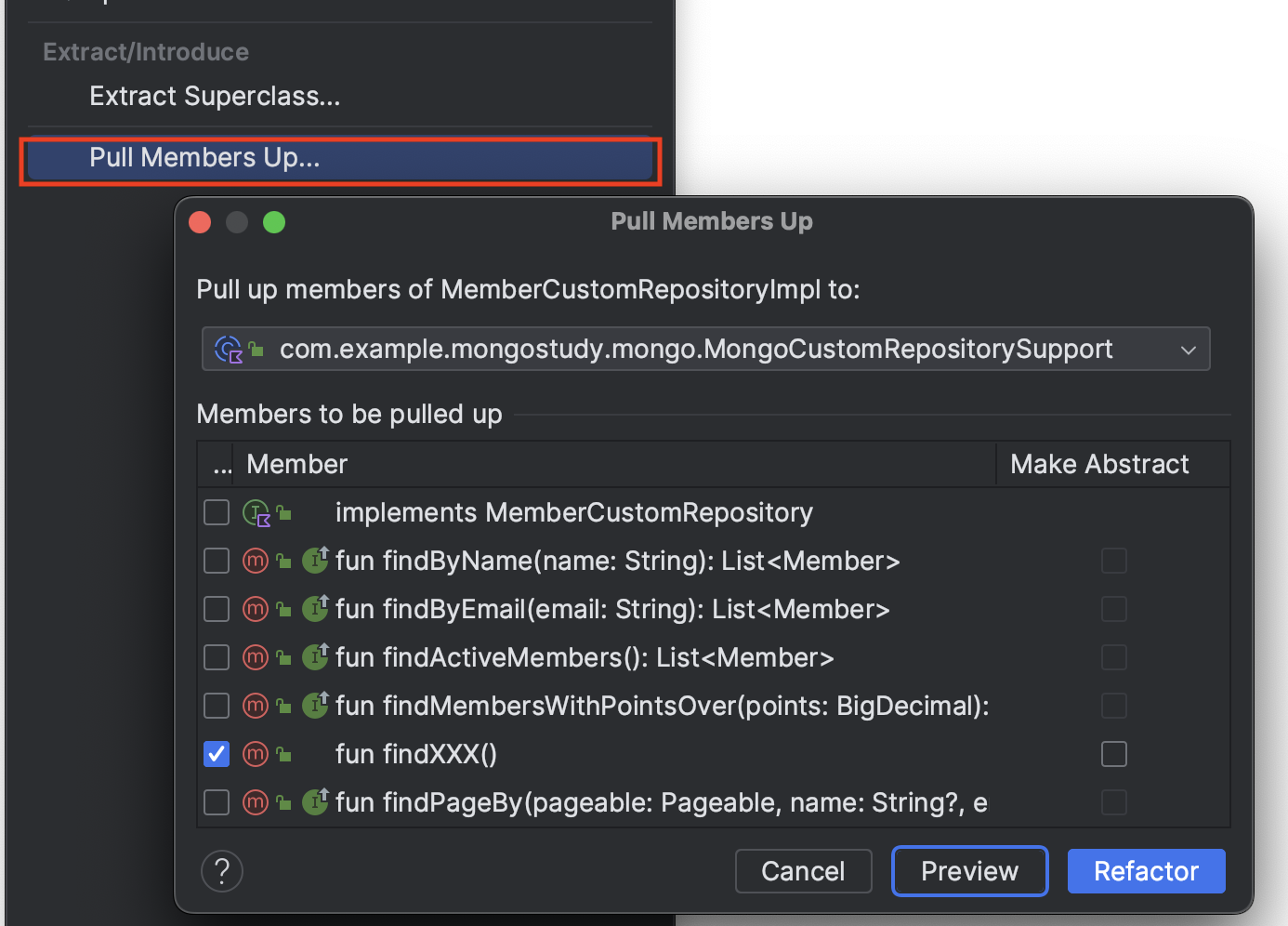
MemberCustomRepositoryImpl 클래스에서는 MemberCustomRepository 인터페이스에 선언된 메소드의 구체적인 구현이 이루어집니다. 처음에는 override 키워드 없이 구현을 시작할 수 있습니다. 구현을 완료한 후, IntelliJ의 Refactoring 메뉴에서 Pull Members Up... 옵션을 선택함으로써 해당 메소드를 상위 인터페이스로 이동시킬 수 있습니다.
인터페이스의 메서드 시그니처를 처음부터 명확히 정의하지 않고, 구현 클래스에서 메서드의 세부 구현을 확정한 후에 이를 상위 인터페이스로 옮기는 방식을 개인적으로 선호합니다.
Querydsl Repository Support 활용 포스팅에서는 QuerydslRepositorySupport를 사용해 CustomRepositoryImpl의 반복적이고 복잡한 쿼리 로직을 단순화한 방법을 소개했습니다. 이와 유사하게, MongoCustomRepositorySupport를 생성하여 CustomRepositoryImpl에 공통 메서드를 중앙화시키면, 코드 중복을 줄이고 재사용성을 높일 수 있습니다. 이러한 방식은 Mongo DB 환경에서도 Querydsl의 장점을 활용하게 해주며, 코드 관리 및 유지보수의 효율성을 향상시킵니다. 대표적으로 페이징 처리 관련된 기능들을 통합해서 제공해줄 수 있습니다.
JPA 페이징 성능을 향상시키는 방법으로, 내용을 담은 콘텐츠 쿼리와 개수를 세는 카운트 쿼리를 분리하여 구현하는 것이 유익하다는 내용을 JPA 페이징 Performance 향상 방법에서 다루었습니다. 이 두 쿼리는 상호 의존적이지 않아 병렬 처리를 함으로써 성능을 높일 수 있습니다. 또한, 슬라이스 쿼리의 경우, '다음 페이지가 있는지’를 확인하는 hasNext 메서드를 포함한 공통된 로직을 사용함으로써 코드 중복을 방지하고 재사용성을 극대화합니다. MongoCustomRepositorySupport 클래스는 이러한 공통 기능을 제공하여 효율적인 데이터 조회와 페이지 처리를 가능하게 합니다."
MemberCustomRepositoryImpl 클래스는 MongoCustomRepositorySupport 추상 클래스를 상속받아, MongoDB와의 데이터 교환을 더 효율적으로 관리하는 특수한 저장소 구현을 제공합니다. MongoCustomRepositorySupport는 몽고디비의 mongoTemplate와 작업할 클래스 타입을 받아 초기화합니다. 이는 MemberRepository 구현에 필수적인 기반 구조를 제공하여 보일러플레이트 코드를 줄이고 코드의 재사용성을 향상시킵니다.
]]>
<p>Spring Data JPA에서 흔히 사용하는 Repository 확장 패턴을 Spring Data MongoDB에도 적용할 수 있습니다. 이 패턴은 'CustomRepository’와 'CustomRepositoryImpl’의 조합으로 구성되며
JPA 페이징 Performance 향상 방법https://cheese10yun.github.io/page-performance/2023-09-04T15:00:00.000Z2023-09-10T15:15:36.719Z일반적으로 어드민 페이지와 같이 데이터를 테이블 뷰 형식으로 제공할 때, 페이징 기법을 사용하여 현재 페이지의 내용과 페이지 정보를 표시합니다. JPA를 활용하면 이러한 반복적인 코드 작성을 보다 쉽게 처리할 수 있습니다.
데이터 모수가 적고 단순한 구조로 데이터를 보여주는 경우라면 JPA에서 제공해 주는 방식으로 처리하는 것이 효율적일 수 있으나 데이터 모수가 많고 여러 테이블을 조인해서 표현해야 하는 데이터 구조라면 성능적인 이슈가 발생할 수 있습니다. 이러한 이슈와 성능 개선 방법에 대해 알아보겠습니다.
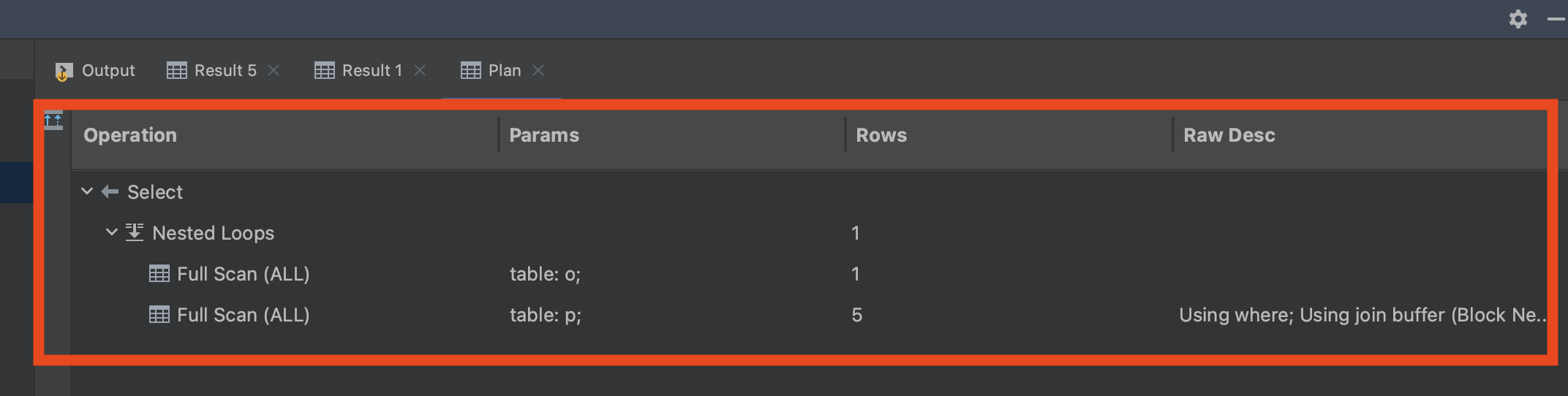
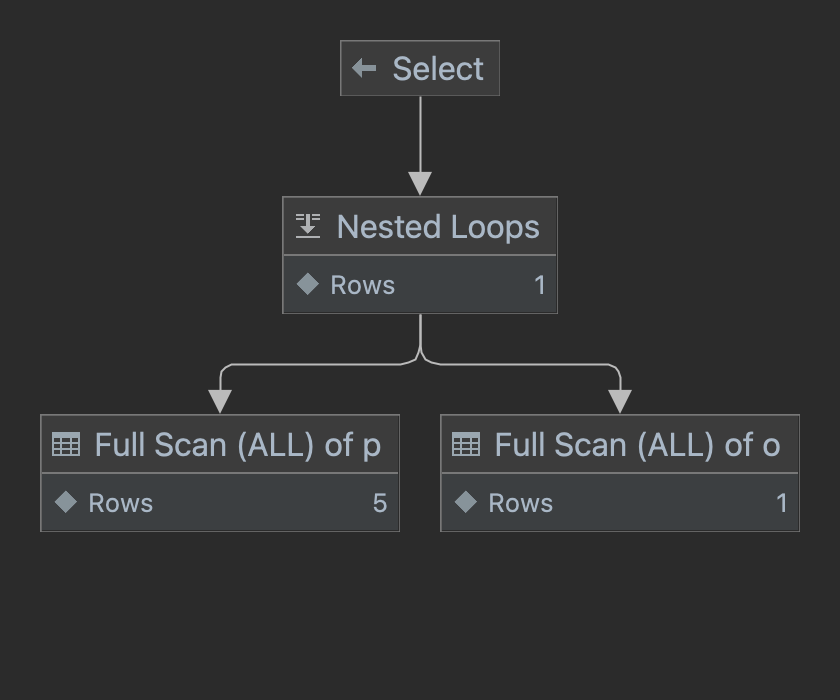
Querydsl 페이징 처리 방식
데이터 모수가 적고 간단한 조회 구조를 가질 때, Querydsl의 applyPagination 메서드를 활용하면 페이징 로직을 더 쉽게 작성할 수 있습니다.
세부 구현체에서는 조회 로직을 살펴보겠습니다. 이 과정에서 Querydsl를 기반으로 JPAQuery를 생성하며 필요한 조회 조건을 작성합니다. 그런 다음 해당 쿼리 객체를 이용하여 Content 조회와 전체 레코드 수 조회를 수행합니다. 마지막으로 각각의 실제 쿼리를 확인하게 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12
select order0_.id as id1_4_, ... order0_.address as address4_4_, order0_.created_at as created_2_4_, order0_.updated_at as updated_3_4_, from orders order0_ where order0_.address = ? limit ?, ?
selectcount(order0_.id) as col_0_0_ from orders order0_ where order0_.address = ?
Content 조회에 필요하 조회 쿼리와, 전체 레코드 조회에 필요한 쿼리를 JPAQuery를 통해 동일하게 사용이 가능하며, Querydsl의 applyPagination 메서드를 활용하여 offset 및 limit 관련 페이징 로직을 간단하게 구현할 수 있다는 큰 장점이 있습니다.
Querydsl의 applyPagination을 활용하면 페이징 조회 관련 로직을 간단하게 구현할 수 있어서 개발 생산성 측면에서 큰 이점이 있습니다. 그러나 모든 개발 결정 과정에서는 트레이드오프가 발생합니다. 편리한 기능을 즉시 활용할 수 있지만, 나중에는 추가 비용을 지불해야 하며 이 비용은 이자를 포함하여 청구될 수 있습니다.
어떤 문제가 발생하는지 살펴보겠습니다.
Count 쿼리의 성능 문제
Count 쿼리는 특정 조건에 해당하는 전체 레코드 수를 조회하는 구조로, 데이터 총량이 증가하면 성능 저하가 발생할 수 있습니다. Content를 조회하는 limit 및 offset 쿼리는 빠르게 처리되는(offset 비교적 크지 않은 초반 구간) 반면 Count 쿼리는 시간이 오래 걸려 병목 현상이 발생할 수 있습니다. 또한, 여러 테이블을 조인하여 데이터를 조회하는 경우에는 조회 조건이 복잡해져 정확한 인덱스를 타겟팅하기 어려운 이슈가 발생할 수 있습니다. 이는 조회 조건에 부합하는 전체 레코드를 Count 하는 구조에서 필연적으로 발생할 수밖에 없는 문제입니다.
Count 쿼리의 최적화 문제
이러한 문제 외에도 다른 문제가 있습니다. JPAQuery를 사용하여 Content 조회 쿼리와 레코드 Count 조회 쿼리를 동일하게 처리하면 성능적인 손해가 발생할 수 있습니다. 특히 여러 테이블을 조인하여 데이터를 조회하는 경우에 이 문제가 더 두드러집니다.
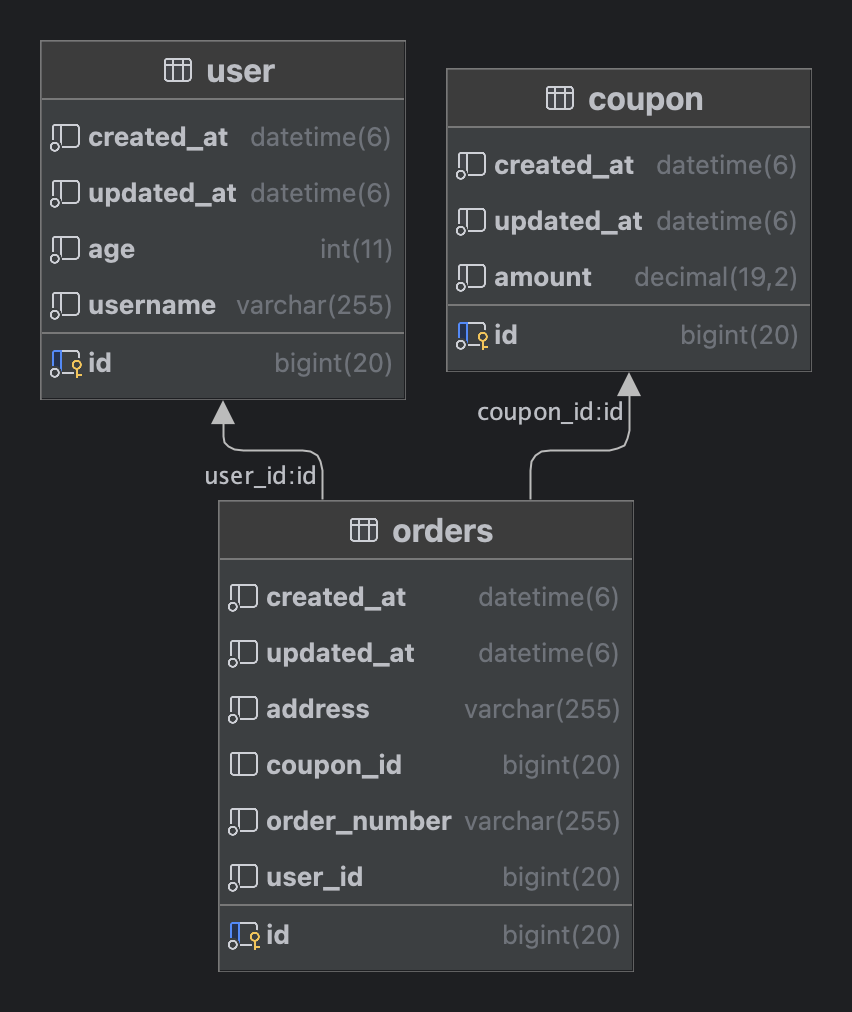
주문 조회 시에 사용자 및 쿠폰 정보와 함께 내려줘야 하는 경우, 조회 필터에 주문 정보만 있는 상황에서 Count 쿼리를 실행할 때, 다른 테이블의 조인 없이 주문에 대한 Count 쿼리를 작성하는 것이 효율적입니다.
-- Content 조회 쿼리 select o.*, u.*, c.* from orders o leftjoin coupon c on o.coupon_id = c.id innerjoinuser u on o.user_id = u.id where o.address = ? limit ?, ? ;
-- Content 조회 쿼리를 그대로 사용하는 경우 selectcount(o.id) from orders o leftjoin coupon c on o.coupon_id = c.id innerjoinuser u on o.user_id = u.id where o.address = ? ;
-- Content 쿼리를 사용하지 않고 별도의 Count 조회 쿼리 selectcount(o.id) ascount from orders o where o.address = ? ;
주문 조회에서 address 필드만 조회 조건에 해당된다면, 사용자 및 쿠폰 테이블과의 조인은 필요하지 않습니다. 이 경우, Count 쿼리를 간단하게 주문 테이블만을 대상으로 작성하는 것이 효율적입니다. 조회 조건이 복잡해질 때, Count 쿼리를 별도로 작성하는 것은 성능적으로 장점을 가질 수 있습니다.
Querydsl 페이징 성능 최적화 방법
Slice 기반으로 Count 쿼리를 사용하지 않는 방법
JPA Slice 방식은 Page 방식과는 다르게 Total Count를 조회하는 count 쿼리를 실행하지 않는 방식입니다. 따라서 Total Count를 조회하는데 드는 시간을 절약하여 성능적인 이점을 얻을 수 있습니다. 페이지네이션 된 데이터를 불러올 때, 전체 데이터의 총개수를 파악하지 않고도 일부 데이터를 가져올 수 있기 때문에, Total Count가 필요 없는 상황에서 사용하면 성능을 향상시킬 수 있습니다. Slice 방식은 특히 대용량 데이터의 페이징 처리에 유용합니다. 이렇게 Slice 방식은 Total Count를 구하지 않고도 효율적인 페이징 처리를 가능하게 합니다. Total Count가 꼭 필요한 데이터인지 비즈니스 적으로 확인해 보고 꼭 필요한 데이터가 아니라면 사용하지 않는 것을 권장 드립니다.
Slice 페이징 처리 방법
Spring Data에서는 Slice를 통해 Total Count를 조회하지 않는 형태의 페이징 처리를 지원하고 있습니다.
Total Count가 필요 없기 때문에 생략 가능하며, 페이징 로직은 동일하게 applyPagination으로 진행하며 중요한 부분은 hasNext로 앞으로 더 읽을 데이터가 남아 있는지를 결정하는 변수입니다.
Order 데이터가 총 22개 있다고 가정하고 Page 0 ~ 4까지 Size 5개를 기준으로 조회한다고 가정해 보겠습니다.
Page
Size
Content
Last
0
5
5
F
1
5
5
F
2
5
5
F
3
5
5
F
4
5
3
T
Page 3까지는 Content가 설정한 크기만큼 반환되어 Last가 False 상태입니다. 그러나 Page 4에서는 남은 Content가 3개만 남아 있기 때문에 3개의 Content를 반환하고 Last가 True 상태로 변경됩니다. 이 방식은 코드로 작성하면 content.size >= pageable.pageSize로 표현됩니다.
이 방식은 Total Count를 알 수 없기 때문에 Last 여부를 확인하기 위해서는 끝까지 데이터를 읽어봐야 정확히 판단할 수 있습니다. 반면에 Slice가 아닌 Page 방식에서는 Total Count를 알고 있어 다음 페이지를 읽지 않아도 Last 여부를 정확히 판단할 수 있습니다.
Order 데이터가 총 22개 있다고 가정하고 동일한 Size를 가지는 Page 방식과 Slice 방식을 비교해 보겠습니다.
방식
Page
Size
Content
Total Count
Last
Page 방식
0
22
22
22
T
Slice 방식
0
22
22
알 수 없음
F
Slice 방식
0
23
22
알 수 없음
T
Page 방식에서는 Total Count를 알고 있기 때문에 Content Size가 동일하다면 Last가 True로 판단할 수 있습니다. 반면에 Total Count을 모르는 Slice 방식에서는 다음 페이지까지 읽어보고 Content Size가 0인 것을 확인해야 Last가 True로 판단할 수 있습니다. Size를 23으로 조회하면 응답하는 Content는 22개로, 요청한 Size보다 Content가 작게 응답되므로 Last를 True로 판단할 수 있습니다.
이로 인해 발생하는 성능적인 차이를 언급하는 것은 아니며, Page 방식과 Slice 방식 간의 구조적인 차이를 설명하기 위해 이를 언급한 것입니다.
Slice 사용이 용이한 구간
테이블 뷰 형식으로 페이징 처리를 할 때, Total Count가 반드시 필요하지 않은 경우에는 대부분 Slice 방식을 활용하는 것이 효율적입니다. 예를 들어, 최근 주문 정보를 기반으로 회원 등급을 업데이트하는 배치 기능을 개발한다고 가정해 보겠습니다. 이 경우에는 Count 쿼리를 사용할 필요가 없습니다. 단순히 필요한 데이터를 offset과 limit 방식으로 읽고 처리하기 때문에 Count 쿼리를 수행하지 않아도 됩니다. 더불어 Count 쿼리는 데이터양에 상관없이 일정 시간이 걸리는데, 데이터양이 많은 경우 Content 조회 쿼리보다 더 많은 시간이 소요됩니다. 그러므로 이 Count 쿼리를 계속 사용하는 것은 성능상의 부담을 가중시킬 수 있습니다.
Total Count가 반드시 필요한 경우에는 Slice 방식을 사용할 수 없으므로 Page 방식을 사용해야 합니다. 또한, 위에서 언급한 대로 여러 테이블을 조인해서 복잡한 데이터를 조회하는 경우에는 Count 쿼리를 별도로 구현하는 것이 성능적인 이점을 가져올 수 있습니다.
이는 AbstractJPAQuery의 fetchCount()가 Deprecated된 이유 중 하나입니다. 조인이 많거나 복잡한 쿼리에서 fetchCount를 사용하면 성능 저하가 발생할 수 있기 때문에 다른 방식으로 count 쿼리를 실행하도록 권장하고 있습니다.
PageImpl을 사용하여 Page 객체를 생성할 때, totalCount를 Content 쿼리와 별도로 구현하여 작성합니다. totalCount를 구할 때 SimpleExpression의 count()를 사용하여 질의합니다. 이러한 최종 쿼리를 살펴보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
-- Content 쿼리 select order0_.id as id1_4_, order0_.created_at as created_2_4_, order0_.updated_at as updated_3_4_, order0_.address as address4_4_, order0_.coupon_id as coupon_i5_4_, order0_.order_number as order_nu6_4_, order0_.user_id as user_id7_4_ from orders order0_ innerjoinuser user1_ on (order0_.user_id = user1_.id) leftouterjoin coupon coupon2_ on (order0_.coupon_id = coupon2_.id) where order0_.address = ? limit ?, ? ;
-- Count 쿼리 selectcount(order0_.id) as col_0_0_ from orders order0_ where order0_.address = ? limit ? ;
Content 쿼리는 Content에 필요한 정보를 여러 테이블의 조인을 통해 가져오며, Count 쿼리는 조회 조건에 필요한 정보만 가져옵니다. 이때 fetchCount()가 Deprecated 되었기 때문에 fetchFirst()로 대체합니다. 이렇게 Count 쿼리를 따로 구현하면 Count 조건에 맞는 방식으로 최적화하여 성능적인 이점을 얻을 수 있습니다.
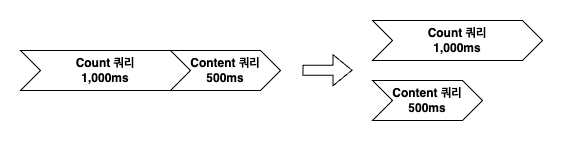
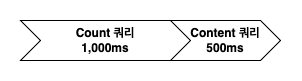
Count 쿼리와 Content 쿼리 병렬 처리하여 개선 방법
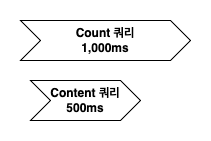
Count 쿼리가 1,000ms가 소요되고, 이후 Content 쿼리가 500ms 소요된다고 가정하면 총 1,500ms가 소요됩니다. 이 작업을 전체 데이터를 읽을 때마다 반복하면 성능상 문제가 발생할 수 있습니다. 그러나 이 두 작업은 서로 의존성이 없기 때문에 병렬로 처리할 수 있습니다.
Count 쿼리와 Content 쿼리를 병렬로 처리하면 Count 쿼리가 소요 시간이 더 길더라도 1,000ms에 작업을 완료할 수 있습니다. 병렬 처리를 코루틴을 활용하여 구현해 보겠습니다.
코루틴의 async와 await를 활용하여 Content 쿼리와 Count 쿼리를 병렬로 처리하였습니다. 이 과정에서 스레드 정보를 확인하기 위해 Thread.currentThread()를 사용하여 현재 스레드 정보를 출력합니다.
1 2 3 4
INFO [nio-8080-exec-1] repository.order.OrderApi : thread api : Thread[http-nio-8080-exec-1,5,main] INFO [-1 @coroutine#1] OrderCustomRepositoryImpl : findPagingBy thread : Thread[http-nio-8080-exec-1 @coroutine#1,5,main] INFO [-1 @coroutine#2] OrderCustomRepositoryImpl : content thread : Thread[http-nio-8080-exec-1 @coroutine#2,5,main] INFO [-1 @coroutine#3] OrderCustomRepositoryImpl : count thread : Thread[http-nio-8080-exec-1 @coroutine#3,5,main]
OrderApi의 exec-1 요청 스레드를 기준으로 findPagingBy, content, count 스레드가 동일한 스레드를 사용하는 것을 확인할 수 있습니다. 이것은 @coroutine# 주석에서 볼 수 있듯이 한 스레드 내에서 여러 코루틴을 실행할 수 있는 구조를 의미합니다.
VM Option에 -Dkotlinx.coroutines.debug을 추가하면 실행 중인 코루틴이 어떤 스레드에서 실행되는지를 확인할 수 있습니다.
코루틴을 이용한 Count 쿼리와 Content 쿼리 병렬 처리 테스트
Count 쿼리에는 delay(1_000)을 지정하여 1초 동안 대기하고, Content 쿼리에는 delay(500)을 지정하여 0.5초 동안 대기하며 테스트를 진행합니다.
1 2 3 4 5 6 7 8 9 10
@Test fun `count 1,000ms, content 500ms delay test`() = runBlocking { val time = measureTimeMillis { orderRepository.findPagingBy( pageable = PageRequest.of(0, 10), address = "address" ) } println("${time}ms") // 1,037ms }
소요 시간은 1,037ms으로 정상적으로 병렬 처리가 되는 것을 확인할 수 있습니다.
Support 객체를 통한 Querydsl 페이징 로직 개선
Slice, Page 등과 같은 페이징 처리를 위한 중복 로직을 피하고 편리하게 사용하기 위해 해당 기능을 Support 객체에 관련 로직을 위임 시키겠습니다. Querydsl Repository Support 활용에서 소개한 QuerydslRepositorySupport를 기반으로 해당 기능을 한 번 더 감싸는 QuerydslCustomRepositorySupport 클래스에서 페이징 로직을 작성하겠습니다.
QuerydslCustomRepositorySupport 객체를 상속받아 applyPagination과 applySlicePagination 로직을 작성합니다. 페이징 로직에 대한 처리는 모두 QuerydslCustomRepositorySupport로 위임되며, 각 Repository에서는 해당하는 쿼리만 작성하면 되는 구조로 코드가 훨씬 더 간결해졌습니다.
]]>
<p>일반적으로 어드민 페이지와 같이 데이터를 테이블 뷰 형식으로 제공할 때, 페이징 기법을 사용하여 현재 페이지의 내용과 페이지 정보를 표시합니다. JPA를 활용하면 이러한 반복적인 코드 작성을 보다 쉽게 처리할 수 있습니다.</p>
<p>데이터 모
Kotlin 기반 경량 ORM Exposed 추가 정리 part 3https://cheese10yun.github.io/exposed-3/2023-07-01T15:00:00.000Z2023-08-19T17:55:08.933ZExposed 포스팅
데이터 저장소에 값을 저장하는 경우, 저장된 데이터를 가져오는 경우 적절하게 컨버팅이 필요한 경우 JPA에서는 @Converter를 사용하면 손쉽게 제어할 수 있습니다. Exposed에서는 VarCharColumnType를 확장하는 방식으로 해당 기능을 사용할 수 있습니다.
1 2 3 4 5 6
object Writers : LongIdTable("writer") { val name = varchar("name", 150).nullable() val email = varchar("email", 150) val createdAt = datetime("created_at").clientDefault { LocalDateTime.now() } val updatedAt = datetime("updated_at").clientDefault { LocalDateTime.now() } }
title 필드에 불필요한 공백을 제거하고 싶은 Converter를 사용하고 싶은 경우에는 VarCharColumnType를 확장하여 구현이 가능합니다.
overridefunvalueFromDB(value: Any): String { returnwhen (value) { is String -> value.trim() else -> throw IllegalArgumentException("${value::class.java.typeName} 타입은 Exposed 기반 컨버터에서 지원하지 않습니다.") } } }
title 칼럼은 varchar 타입이므로 VarCharColumnType을 통해서 구현합니다. valueToDB에는 데이터 저장소에 들어가는 컨버팅 로직을, valueFromDB에는 반대로 데이터베이스에서 가져온 데이터에 대한 컨버팅 로직을 작성합니다. 해당 로직은 공백을 제거하는 로직이므로 trim()을 사용해서 동일하게 구현합니다. 해당 코드는 String 자료형에만 동작하게 구성했으며 필요에 따라 추가적인 자료형을 추가하면 됩니다.
1 2 3 4 5 6 7 8 9
object Writers : LongIdTable("writer") { val name = registerColumn<String>( name = "name", type = TrimmingWhitespaceConverterColumnType(length = 150) ).nullable() val email = varchar("email", 150) val createdAt = datetime("created_at").clientDefault { LocalDateTime.now() } val updatedAt = datetime("updated_at").clientDefault { LocalDateTime.now() } }
registerColumn을 활용해서 Converter 코드 TrimmingWhitespaceConverterColumnType을 적용시킵니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
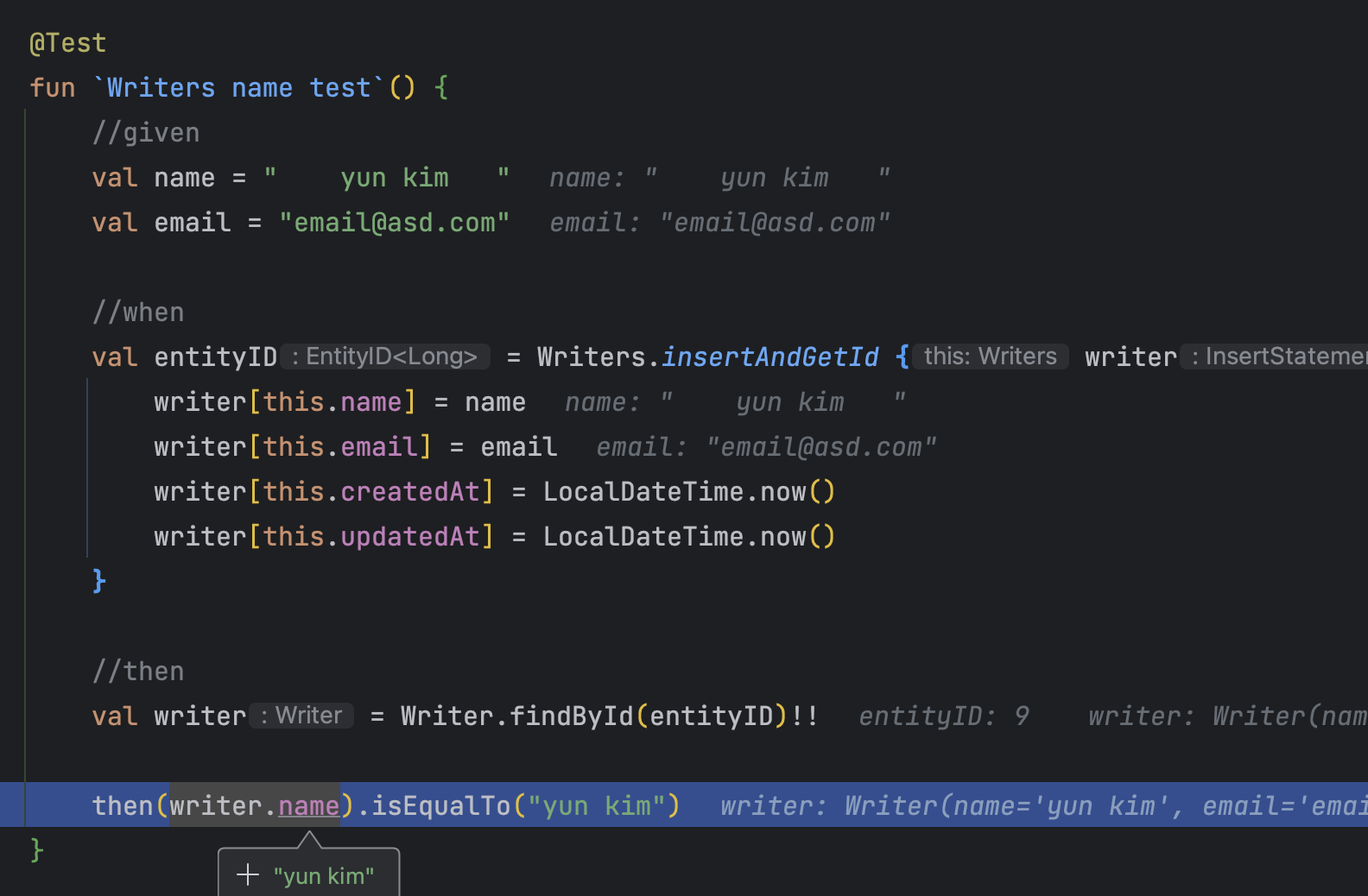
@Test fun `Writers name test`() { //given val name = " yun kim " val email = "email@asd.com"
//when val entityID = Writers.insertAndGetId { writer -> writer[this.name] = name writer[this.email] = email writer[this.createdAt] = LocalDateTime.now() writer[this.updatedAt] = LocalDateTime.now() } //then val writer = Writer.findById(entityID)!!
then(writer.name).isEqualTo("yun kim") }
앞뒤 공백이 있는 문자열에 대해서 실제 데이터베이스에 정상적으로 Converter 로직이 동작하는지 테스트를 진행해 보겠습니다. 실제 디버깅으로 확인해 보겠습니다.
앞뒤 공백이 제거된 yun kim으로 출력되는 것을 확인할 수 있습니다.
Function
SQL Function 중 자주 사용되는 기능들에 대해서는 이미 구현하여 기능을 제공하고 있습니다. 집계 함수 Books.price.sum(), 문자열 함수 Books.title.lowerCase() 등이 있습니다. 예제 코드로 groupConcat을 살펴보겠습니다.
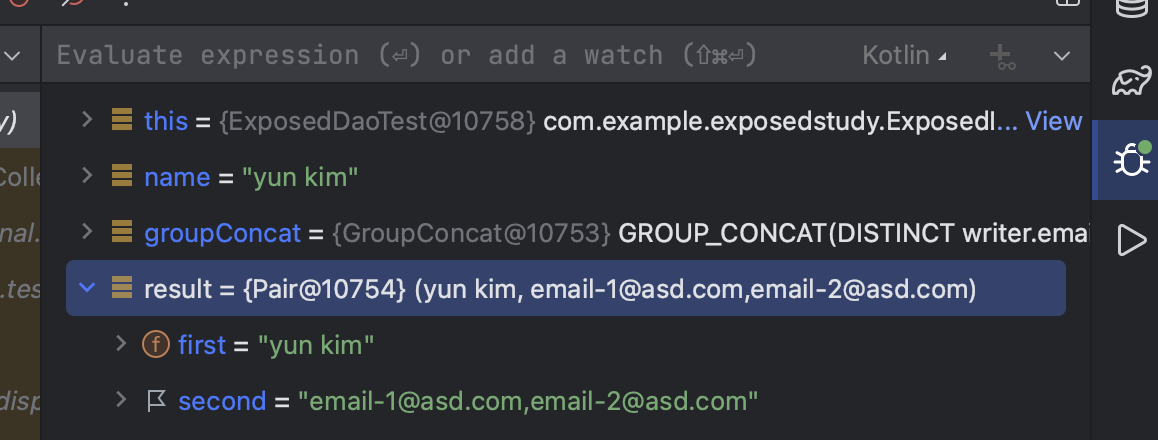
@Test fun `groupConcat`() { //given val name = "yun kim" Writers.batchInsert((1..2)) { this[Writers.name] = name this[Writers.email] = "email-${it}@asd.com" }
//when val groupConcat = Writers.email.groupConcat(distinct = true) val result = Writers .slice( groupConcat, Writers.name, ) .select { Writers.name eq name } .map { Pair( it[Writers.name], it[groupConcat] ) } .first()
Expression 타입이기 때문에 groupConcat 확장 함수를 그대로 사용할 수 있습니다. 최종 SQL을 살펴보겠습니다.
1 2 3
SELECTGROUP_CONCAT(DISTINCT writer.email), writer.`name` FROM writer WHERE writer.`name` = 'yun kim'
의도한 대로 GROUP_CONCAT(DISTINCT writer.email) SQL Function이 정상적으로 출력되었습니다. 그러면 조회한 데이터를 확인해 보겠습니다.
최종 결과로 문자열 email-1@asd.com, email-2@asd.com을 응답받은 것을 확인할 수 있습니다.
]]>
<h2><span id="exposed-포스팅">Exposed 포스팅</span></h2>
<ul>
<li><a href="https://cheese10yun.github.io/exposed/">Kotlin 기반 경량 ORM Exposed</a></l
좋은 코드 설계를 위한 답없는 고민들https://cheese10yun.github.io/code-design/2023-06-11T15:00:00.000Z2023-08-18T03:00:21.038Z좋은 코드 설계를 위한 고민들을 평소에 많이 해왔고, 그에 관련한 학습들도 진행했었다. OOP, DDD, Clean Code, Clean Architecture 등등을 통해서 나름의 주관이 생겼으며 경력 초반에는 이런 것들을 지키기 위해 많이 노력해왔다. 현재는 이런 개념들을 선택적으로 적용하며 또 어떠한 의미에서는 이런 것들을 지키는 것에 대해서 가성비가 좋지 않다고까지 생각한다. 해당 포스팅에서 작성한 내용은 개발하면서 코드 설계적인 부분에 대해서 아직까지 고민을 하고 있는 부분들에 대해서 정리한 것들이다. 만약 Spring, JPA, Kotlin을 통해서 프로젝트를 진행하고 있다면 공감이 될 수 있다.
복잡도를 어디서 제어(책임)할 것인가?
요구사항이 복잡하면 코드 또한 복잡해진다. 결국 이러한 복잡도를 어느 코드에서는 해결해야 하는데 이 부분에 대한 고민이다.
1 2 3 4 5 6 7 8
enumclassMemberStatus( desc: String ) { NORMAL("정상"), // 이메일 받는 회원 UNVERIFIED("미인증"), // 이메일 받는 회원 LOCK("계정 일지 정지"), // 이메일 제외 회원 BAN("계정 영구정지"); // 이메일 제외 회원 }
예를 들어 특정 성별 중 현재 활성화된 회원 전체에게 이메일을 보내는 로직에서 활성화 회원들을 조회하는 코드가 있다고 가정해 보자.
조회 코드에서 복잡도 제어
1 2 3 4 5 6 7 8 9 10 11
classMemberRepositoryImpl( privateval query: JPAQueryFactory, ) : MemberRepositoryCustom { overridefunfindBy(gender: String): List<Member> = query .selectFrom(member) // 정상적인 회원 상태를 직접 명시 .where(member.genter.eq(gender)) .where(member.status.`in`(setOf(MemberStatus.NORMAL, MemberStatus.UNVERIFIED))) .fetch() }
조회 코드에서 회원 상태의 복잡도를 직접 제어하면 외부 객체에서 현재 활성화 상태에 대한 복잡도에 대해서 자유로워진다. 즉 호출하는 객체에서는 회원의 상태에 대해서 알바가 없어진다는 장점이 있다. 하지만 단점 또한 있다. 회원 상태가 다른 조회 로직이 있다면 거의 유사한 코드가 중복해서 나온다는 것이다.
조회를 호출하는 코드에서 복잡도 제어를 하면 회원 상태에 대한 세부적인 규칙을 해당 객체를 호출하는 곳에 복잡도가 위임된다. 즉 호출하는 쪽에서 회원 상태에 대해서 명확하게 알고 있어야 한다. 물론 이 정도 상태 정도야 복잡도가 높다고 할 수 없지만 여러 필드들의 조합을 분석해서 조회해야 하는 경우는 복잡도가 높아진다. 또 요구사항이 바뀌어서 코드를 변경했다면 호출하는 코드들을 모두 찾아가서 변경해야 한다. 그 복잡도를 외부에서 제어했기 때문에 당연한 결과이다.
정리
단순 파라미터로 받을 것인가 아닌가에 대한 단순한 고민이 아니라 복잡도를 어디에서 제어할 것인가? 그에 따른 장단점이 있고 어떠한 근거로 어떠한 방법을 택할 것인가 또 그 근거는 무엇인가에 대한 고민을 해봤으면 한다. 나름의 결론이 있다면(또 어떻게 바뀔지 모르겠지만) 네이밍을 통해서 그 의도를 드러나게 하는 것이 좋다고 생각한다.
// 활성화 상태인 유저 성별로 조회, 명확하게 해당 의도 전달 funfindActivityMemberBy(gender: String): List<Member> { return memberRepository.findBy(gender, setOf(MemberStatus.NORMAL, MemberStatus.UNVERIFIED)) } }
MemberQueryService 같은 서비스 계층을 두고 해당 객체에서 네이밍으로 명확하게 그 의도를 표현하고, Repository 계층에서는 제너럴 하게 파라미터로 받아 처리한다. 이렇게 하면 서비스 계층에서는 명확하게 현재 활성화 상태의 유저를 조회하게 되며, 인프라 계층에서는 제너럴 하게 조회 로직을 작성함으로써 중복 코드 및 유사 코드를 방지할 수 있다. 인프라스트럭처에 직접적인 의존성을 갖게 하는 것보다 MemberQueryService처럼 서비스 계층을 통해 인프라스트럭처를 간접적으로 의존하는 것이 여러모로 좋다고 생각한다. 관련 포스팅은 Spring Guide - Service 가이드에 정리되어 있다.
유효성 검사는 어디서 어떻게 해야할까?
일반적으로 Presentation 계층에서 다양한 유효성 검사를 하고 문제가 없다면 서비스 계층으로 넘어가서 비즈니스 로직을 수행하는 것이 일반적이다. 간단하게 코드로 표현하면 다음과 같다.
@PostMapping funregister( @RequestBody@Valid dto: MemberRegistrationRequest ) { // ... // (1) 간단한 validation 외에 각종 검증... memberRegistrationService.register(dto) } }
spring-boot-starter-validation 의존성으로 필드에 대한 유효성 검증을 쉽게 진행할 수 있다. 하지만 상호 베타적인 값 검증, 외부 인프라를 의존하는 유효성 검사는 진행하기가 어렵다. 그래서 ConstraintValidator을 이용해서 효과적인 검증에 대해서 포스팅한 적이 있다. 추가적인 검증을 컨트롤러에서 진행해도 무방하지만 Error Response 관련해서 더 효율적으로 관리하기 위해서는 ConstraintValidator을 통해서 진행하는 것이 좋다. 예를 들어 요청 필드가 5개고 해당 요청 필드 5개가 모두 문제라면 Error Response을 응답할 때 모든 문제에 대해서 구체적으로 응답해 주는 것이 좋다. 개별적으로 응답을 하면 최악의 경우 5번 요청을 하고 나서야 모든 필드들에 대해서 유효성 확보가 되기 때문이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// 한 요청에 대해서 모든 문제를 한 번에 내려주는 것이 좋다 { "message": " Invalid Input Value", "status": 400, "code": "C001", "errors": [ { "field": "lastName", "value": "", "reason": "비어 있을 수 없습니다" }, { "field": "email", "value": "asd", "reason": "올바른 형식의 이메일 주소여야 합니다" } ], "timestamp": "2023-06-11T23:41:38.557228" }
사전 유효성 검증의 문제
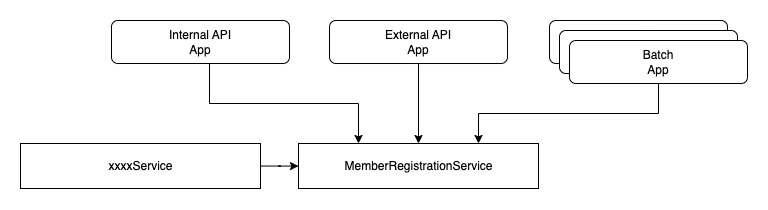
사전에 검증하게 되면 문제가 있다. 위 그림처럼 여러 개의 애플리케이션, 혹은 다른 서비스에서 MemberRegistrationService의존하여 회원가입을 진행할 수 있는 경우 어느 한 구간에서 유효성 검사를 하지 않거나, 유효성 검증 항목의 변경 사항이 제대로 반영되지 않거나 하는 문제가 발생할 수 있다. 결국 여러 애플리케이션, 외부 객체에서 의존하려면 유효성 검사를 모두 MemberRegistrationService에서 진행 시키는 것이 이런 문제를 해결할 수 있는 방법으로 보일 수 있다.
// ValidatorService에서 모든 예외를 담당한다. @Service classMemberRegistrationValidatorService( privateval memberQueryService: MemberQueryService ) { // 내부 로직을 기반으로 오류 검사를 진행하며, 유효성 검사 실패시 Excpetion 발생 funcheckEmailDuplication(email: String) { var inValidCount = 0 val errorMessage = StringBuilder()
isExistedEmail(email) .also { isExistedEmail -> if (isExistedEmail) { inValidCount++ errorMessage.append("${email}은 이미 등록된 이메일 입니다.\n") } } // 기타 문제... // 한 가지 필드를 여러 검증을 진행... if (...) { inValidCount++ errorMessage.append("${email}은 xxx 문제가 있습니다. \n") }
// 실제 유효성 검사를 단순히 boolean 으로 표현 funisExistedEmail(email: String) = memberQueryService.existedEmail(email) }
// Presentation 계층에서 유효성 검사 진행, 실제 검증에 대한 로직은 ValidatorService을 통해 진행 하며 오류 메시지 전달 역할 담당 @Service classMemberRegistrationFormValidator( privateval memberRegistrationValidatorService: MemberRegistrationValidatorService ) : ConstraintValidator<MemberRegistrationForm, MemberRegistrationRequest> { overridefunisValid(dto: MemberRegistrationRequest, context: ConstraintValidatorContext): Boolean { var inValidCount = 0 val existedEmail = memberRegistrationValidatorService.isExistedEmail(dto.email)
if (existedEmail) { inValidCount++ addConstraintViolation(context, "${dto.email}은 이미 등록된 이메일 입니다.", "email") }
// 기타 문제... // 한 가지 필드를 여러 검증을 진행... if (...) { inValidCount++ addConstraintViolation(context, "${dto.email}은 xxx 문제가 있습니다.", "email") }
return inValidCount == 0 } }
MemberRegistrationValidatorService를 보면 isExistedEmail는 유효성 검사에 대한 결과를 Boolean 타입으로 응답하며, checkEmailDuplication에서 isExistedEmail을 이용하여 Exception 발생 여부를 결정한다. 또 isExistedEmail은 단순 Boolean 타입이기 때문에 사용하는 서비스 및 애플리케이션 Presentation 계층에서 해당 메서드로 유효성 검사를 진행하며 그에 따른 핸들링을 진행한다. 예를 들어 External API에서는 Presentation 계층에서 Error Response 핸들링, Batch Application에서는 Exception을 발생시켜 핸들링을 진행한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
@Service classMemberRegistrationService( privateval memberRegistrationValidatorService: MemberRegistrationValidatorService ) { /** * @param isAlreadyCompletedValidation true 경우 이미 유효성 검사를 진행 한것으로 간주하고 추가적으로 유효성 검사를 진행하지 않는다. */ funregister( dto: MemberRegistrationRequest, isAlreadyCompletedValidation: Boolean = false// 이미 유효성 검사를 진행 했다면 추가적은 검증을 진행하지 않는다.. ) { if (isAlreadyCompletedValidation.not()){ memberRegistrationValidatorService.checkEmailDuplication(dto.email) } // ... 등록 로직 } }
MemberRegistrationService 계층에서는 isAlreadyCompletedValidation을 기준으로 추가적으로 유효성 검사를 진행할지 여부를 결정한다. 만약 Presentation 계층에서 동일한 유효성 검사를 진행했다면 더 이상 검증을 하지 않고 등록 로직을 수행한다. 물론 성능상의 큰 차이가 없다면 이런 플래그를 두지 않고 두 번 검사해도 무방하다. 이렇게 진행하면 장점으로는 유효성 검사 로직이 한곳에 모이게 되기 때문에 코드의 응집력이 높아지며, 사전 검증 여부를 확인하고 검증을 진행하지 않았다면 유효성 검사를 담당하는 객체를 통해서 진행하면 된다. 물론 단점으로는 단순 플래그 처리이기 때문에 호출하는 곳에서 이것을 무시하고 유효성 검증을 진행하지 않았음에도 진행을 완료했다고 요청하면 되기 때문에 단점으로 볼 수 있다. 최소한의 방어 로직으로 해당 플래그 default value를 false으로 설정하자. 꼭 이렇게 사용하지 않더라도 유효성을 검증하는 코드를 한 객체에 위임하여 관리하는 것은 좋은 패턴이라고 생각한다.
Setter 없애기
개인적으로 Setter 사용을 지양한다. 관련 내용은 Spring-Jpa Best Practices Step-06 - Setter 사용하지 않기에서 진행한 적 있다. 최근 대부분의 프로젝트는 Kotlin을 기반으로 코딩하고 있으며, JPA도 많이 사용하고 있다. OOP 설계를 지향하기 위해서는 단순 setter를 지양하는 것은 매우 동의하지만 Kotlin + JPA 조합을 사용하는 프로젝트에서는 적용하는 것이 많이 불편하다.
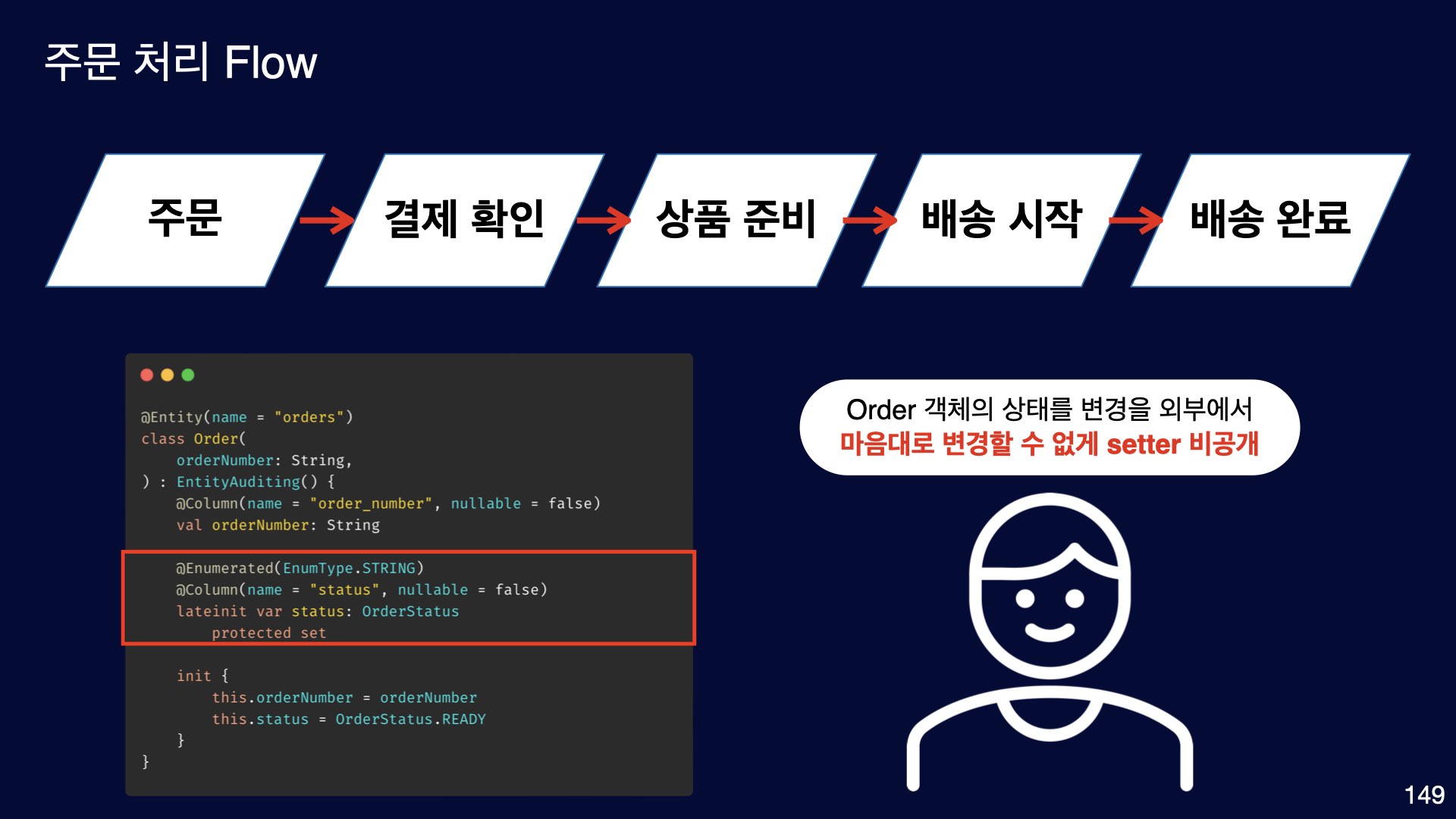
@Enumerated(EnumType.STRING) var status: MemberStatus = status protectedset
init { // 필요하다면 유효성 체크, 기타 로직 수행 등등 진행 } }
단순히 생성자로 받아서 처리하는 방식 보다 코드가 간결하지 않다. 만약 이메일을 변경을 제공하지 않는다면 val으로 선언하고 updatable = false까지 설정하는 것을 권장한다. 생각 보다 필드를 변경하지 않아야 하는 값들이 있다. 예를 들어 주문번호, 거래 번호 등등 고유한 번호로 지정받는 값들은 가능하면 val으로 지정해서 이 필드가 변경이 되지 않는다는 것을 명확하게 표현하는 것이 좋다. 또 @Column을 반드시 작성하는 것을 권장한다. @Column을 사용하면 자연적으로 nullable, updatable 등등을 한 번 더 고민하게 되고 그 고민이 코드적으로 자연스럽게 표현될 확률이 높아진다고 생각한다.
그렇다면 setter를 사용하지 않는 것이 정말 효율적인가?
개인적으로 단순 setter를 지양한다. 하지만 팀 내 컨벤션으로 가져가야 할 정도로 가치가 있을지는 회의적이다. 회의적인 이유는 효율성이다. setter를 지양하는 다양한 이유가 있겠지만 개인적인 생각으로는 복잡도를 제어하기 위함이라고 생각한다. 결국 서비스가 커지고, 관련 개발자들도 많아지면 복잡도를 제어하기가 더욱더 힘들어진다는 것이다. 즉 그렇게 복잡하지 않은 서비스 및 서비스 초기 경우는 setter를 지양해야 할 필요성이 상대적으로 낮다고 본다.
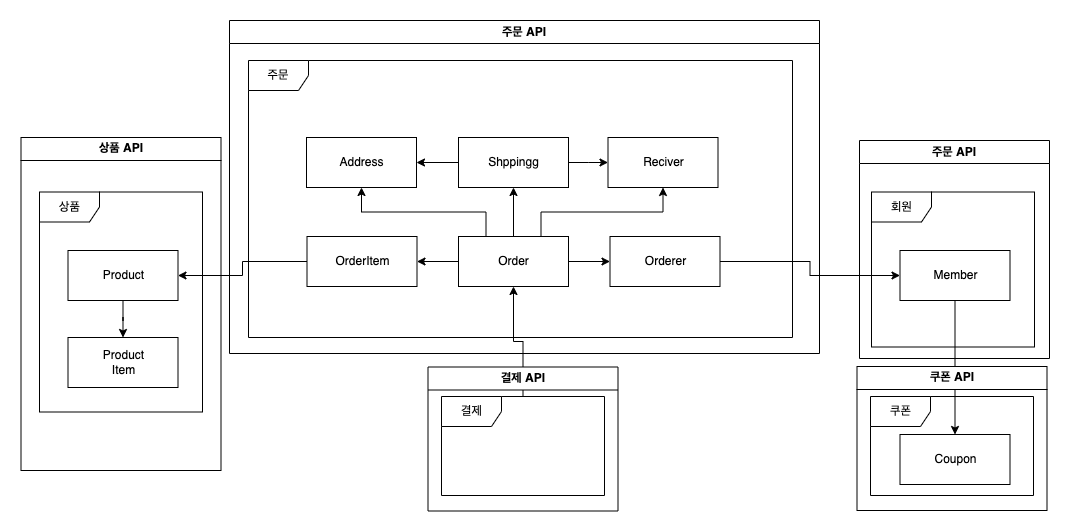
위 구조처럼 상품, 주문, 결제, 회원, 쿠폰 등등 모든 서비스들이 단일 서비스 즉 모놀리식 으로 구성돼 있다고 가정해 보자. 서비스 초기에는 2 ~ 3명의 개발자가 모든 도메인에 대해서 거의 같은 수준으로 도메인을 이해하고 있다. 하지만 서비스가 커지고, 개발자를 채용하면 문제들이 발생한다. 초기에 있던 2 ~ 3명의 개발자들도 프로젝트가 복잡해지면 도메인의 이해 수준이 달라지게 되며 새롭게 합류한 개발자들은 더더욱 그 이해도가 차이 날 수밖에 없다.
예를 들어 초장기에는 쿠폰을 사용하면 쿠폰 미사용에서 사용으로, 사용한 날짜 정도만 업데이트를 하면 됐지만 여러 업체들이 들어오고 업체와의 쿠폰 비용에 대한 처리 비용, 또 다양한 이벤트 쿠폰 등등 단순했던 쿠폰 사용 로직이 이제는 이제는 고려해야 할 사항들이 쿠폰 외부 상황까지 늘어난 셈이다. 이런 경우 단순히 setter로 각각의 필드를 변경하면 사이드 이펙트가 발생할 가능 성이 높아진다. 결국 이렇게 복잡도가 높아지면 객체지향적인 관점으로 책임과 역할을 부여하고 그 범주에서 기능들을 수행해야 하게 된다.
결국은 트레이드오프
그렇다면 이렇게 복잡해졌으니 단순 setter를 지양하는 방식으로 프로젝트를 리팩토링할 것인가?라는 의견에는 회의적이다. 단순 setter를 지양하는 코드로 리팩토링할 시관과 리소스로 차리를 서비스를 상품, 주문, 결제, 회원, 쿠폰을 독립적인 애플리케이션으로 분리 시키고 그 복잡도를 애플리케이션 내부에서 해결하게 하는 것이 훨씬 더 효율성이 높다.
위 이미지처럼 적당한 서비스의 크기로 애플리케이션을 나누어 도메인적인 복잡도를 해결하는 것이 더 좋은 방법이라고 생각한다. 물론 이렇게 분산 환경을 구축하면 기술적인 높은 복잡도가 요구된다. 또 이런 부분들은 단순 기술적인 부분뿐만 아니라 정무적인 영략도 함께 필요하다. 이러한 정무적인 부분에 대한 역량은 없기 때문에 기술적인 측면만 본다면 모놀리식 구조에서 setter를 지양하는 것보다는 서비스의 크기를 작게 나누는 것에 대해서 더 리소스를 투자하는 게 효율적이라고 생각한다.
서비스의 크기를 적당하게 분리 한 이후에는 ?
그렇다면 서비스의 크기를 적절한 수준으로 분리한 이후에는 단순 setter를 지양해아할 것인가?라는 생각이 든다. 결론부터 정리하면 개인적으로는 단순 setter를 지양하나 팀 내 컨벤션까지는 작용까지는 아직 확신이 없다는 견해이다. 결국 개발은 협업이며 팀 내 프로덕트를 만들어 가는 사람들과 같은 청사진을 공유하고 얼라인 하는 것이 매우 중요하다. 본인이 setter를 지양한다면 그에 따른 타당한 이유로 팀원들을 설득해야 하며, 결국 입증의 책임은 주장하는 사람이 하는 것이다. 이런 측면에서는 서비스의 크기가 적당하게(적당히 작게) 유지되고 있다고 전제하에는 모두를 설득 시킬만한 타당한 근거는 지금의 나에게는 없다.
주문 Flow는 주문 -> 결제 확인 -> 상품 준비 -> 배송 시작 -> 배송 완료 순서로 진행되며 반드시 순차적으로만 진행되며 각 Step에 맞게 유효성 체크로직이 꼼꼼하게 작성되어 있다.
Order라는 엔티티 객체를 테스트 코드를 작성하려면 특정 Snapshot 상태로 만들어야 한다. 테스트 코드를 작성하는 구간은 상품 준비 -> 배송시작 임으로 해당 객체를 상품 준비 상태로 만들어야 한다. 하지만 단순 setter가 없기 때문에 상품 준비 중 객체로 직접 만드는 것이 어려운 부분이 있다.
가장 쉬운 해결 책으로는 Order 객체를 하나 만들고 주문 -> 결제 확인 -> 상품 준비의 로직을 각각 호출해서 상품 준비 중 상태로 만들면 된다. 하지만 이 방법도 좋은 방법이 아니다. 해당 테스트 코드의 주요 관심사는 상품 준비 -> 배송 시작에 대한 테스트 코드를 작성하는 것이지 주문 상태부터 결제 확인, 상품 준비까지 객체를 만드는 것이 주요 관심사가 아니다. 이렇게 테스트 코드를 작성하면 주문 -> 결제 확인, 결제 확인 -> 상품 준비 등의 Flow가 변경이 있다면 이 테스트 코드까지 영향 범위가 확대된다. 즉 테스트 코드는 중요 관심사의 변경에만 반영하는 것이 좋다.
확신 없는 결론…
이러한 문제로 단순 setter를 없애는 게 다양한 부작용들이 있다. 물론 이런 부작용들은 Given 절에 데이터 셋업의 어려움이기 때문에 필요한 데이터를 sql 파일, json 파일로 데이터를 임의로 만들어서 테스트를 진행하는 방식으로 대체하고 있다. sql 파일 기반으로 테스트하는 방식에 대해서 설명하면 다음과 같다.
스프링 테스트에서 지원해 주는 @Sql 어노테이션 기반으로 Given 절에 해당하는 데이터를 sql 파일 기반으로 만들어서 테스트하는 방식으로, 관련 포스팅은 Sql을 통해서 테스트 코드를 쉽게 작성하자에 정리되어 있다.
sql 파일로 관리하면 비즈니스 로직에 상관없이 특정 시점으로 자유롭게 데이터를 셋업 할 수 있으며 그 결과 폭넓은 테스트 코드를 보다 쉽게 작성할 수 있게 되며, 외부 의존성 없는 순수한 POJO 엔티티 객체를 테스트하고 싶은 경우 이와 비슷하게 json 파일 기반으로 테스트할 수 있다. 이러한 방법이 다양한 테스트 대역폭을 확보하기 위한 좋은 전략이라고 생각은 하지만 이 또한 단점들이 있어서 이 방법을 택할 정도로 압도적인 장점이 크지 않기 때문에 확신은 없고 계속 고민하고 있는 주제이다. 이러한 이유 등등으로 프로젝트를 크기를 적절하게 분리해서 분산 환경으로 관리하고 setter는 그 해당 팀의 정책적으로 선택하는 것이 좋다고 생각한다.
성인 Member를 조회했지만 실제 Member 객체를 리턴하기 때문에 주민등록 필드에 대한 notnull 관련 작업을 진행할 때는 member.residentRegistrationNumber!!을 사용해야 한다. 이런 경우 Projection을 사용하면 이런 문제를 쉽게 해결할 수 있다.
1 2 3 4 5
dataclassAdultMember( // notnull을 보장 val residentRegistrationNumber: String, var status: MemberStatus, )
자세한 Projection 방법은 Querydsl Projection 방법 소개 및 선호하는 패턴 정리에서 다룬 적 있다. Projection을 사용하면 영속성 컨텍스트가 없기 때문에 JPA에서 제공해 주는 다양한 기능들을 사용하지 못한다. 그 밖에 단점들도 있지만 이것은 조금 더 이후에 살펴보고 Projection을 활용하면 얻을 수 있는 장점들을 살펴보자.
위 데이터 구조처럼 주문에 대한 Refund(환불) 객체가 있고, 신용카드 결제라면 credit_card 정보가 있고, 무통장 입금의 경우에는 account 정보가 있다고 가정해 보자. credit_card, account 정보는 상호 베타적인 정보이기 때문에 두 객체는 nullable 설정할 수밖에 없다. Refund(환불) 엔티티 객체를 그대로 사용한다면 내가 조회한 데이터와 상관없이 계속 null 안정성에 대한 고민을 할 수밖에 없고 !!의 불편한 동행이 계속된다. 문제는 그것뿐만이 아니다 환불이라는 컨텍스트의 모호함이 있다. 카드 환불인지, 무통장입금의 환불인지를 명확하게 표시하면 그 컨텍스트를 이해하는 것에 도움이 된다. 물론 변수명으로 표현이 하지만 Projection을 사용해서 CardRefund 타입으로 표현하는 것도 더 명확하며 안전하다고 생각한다.
Projection의 치명적인 단점
Projection을 사용하면 영속성 컨텍스트를 사용하지 못하는 단점 말고도 다른 큰 단점이 있다. 리턴되는 타입이 엔티티 객체가 아니기 때문에 엔티티 객체에 있는 로직을 사용할 수 없다는 것이다. 이를 해결하기 위해서 Interface로 묶고 공통적인 로직은 Interface에서 구현하는 것으로 쉽게 해결이 가능해 보인다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
interfaceGeneralMember{ // ... val email: String val firstName: String val lastName: String // 공통 로직을 작성 funfullName(): String { return"$firstName$lastName" } }
dataclassAdultMember( // ... overrideval email: String, overrideval firstName: String, overrideval lastName: String, val status: MemberStatus, ) : GeneralMember // 인터페이스를 상속해서 공통 로직 사용 가능
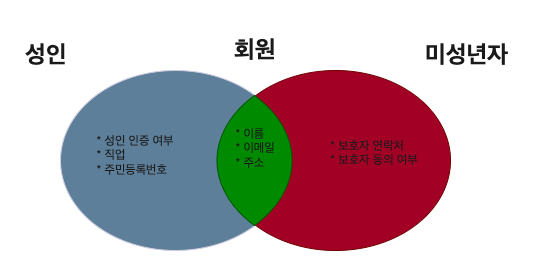
GeneralMember 인터페이스를 만들고 필요한 공통 로직을 작성한다. 그리고 Member 엔티티 객체, AdultMember Projection 객체에서 해당 인터페이스를 구현하면 공통 로직을 사용할 수 있다. 하지만 이렇게 인터페이스를 설계하려면 책임과 역할을 명확한 단위(작은 단위)로 구성해야 한다. 그저 엔티티와 일대일로 매핑되는 인터페이스를 두는 행위는 지양해야 한다.
Member라는 교집합에는 이름, 이메일, 주소 세 가지 필드가 있다. GeneralMember가 보호자 연락처, 보호자 동의 여부 필드를 가지고 있다면 어떻게 될까? 정상적으로 override을 할 수 없다. 즉 위 그림처럼 회원이라는 인터페이스는 세 가지 일반(공통), 성인, 미성년자 인터페이스로 구성해야 하며 단순히 인터페이스를 공통 로직으로만 보고 설계하면 안 되고 많은 것들을 고려해야 한다.
그렇다면 일반(공통), 성인, 미성년자 세 가지 타입이면 충분할까? 남성, 여성 등이 나올 수 있으며, 또 어떤 타입들이 나올 수 있는지 확신할 수 없다. 충분히 깊은 고민 없이 단순히 중복 코드를 만들기 위해서 억지로 추상화를 진행하면 결국 파국뿐이다.
이런식의 인터페이스는 올바른가?
위 문제처럼 각 책임에 맞게 적절하게 인터페이스를 두었다고 가정해 보자. 그렇다면 그것이 좋은 설계라고 볼 수 있을까? 나는 그렇지 않다고 생각한다. 결국 인터페이스를 두는 이유는 세부 구현체를 숨기 기고 인터페이스를 바라보게 함으로써 클래스 간의 의존관계를 줄이는 것, 다형성을 사용하여 역할을 대체할 수 있는 것이 중요한 핵심이라고 생각한다. 위 예제처럼 인터페이스는 그저 코드의 중복을 막기 위해 억지로 끼워 맞추는 것에 지나지 않는다고 생각한다.
상속보다는 조합(Composition)
캡슐화를 쉽게 깨트리고, 상위 클래스에 지나치게 의존하게 돼서 변화에 유연하게 대응하지 못하는 경우 상속보다는 조합(Composition)을 사용해서 이러한 문제를 해결하라고 한다. 또 Kotlin에서는 객체에 있는 모든 public 함수를 이 객체를 담고 있는 컨테이너를 통해 노출할 수 있는 기능을 by 키워드를 통해 제공해 주고 있다. 이런 것으로 해결은 가능하나 JPA와 사용했을 때 궁합이 좋지 않고 이러한 문제를 해결할 내공이 부족하여 이 방법에 대한 확신은 아직 없다.
마무리
복잡도를 제어하고 유지 보수하기 좋은 코드 디자인을 갖기 위해 학습했던 것들을 실제 적용하면서 만났던 현실적인 문제들을 정리해 보았다. 이런 것들을 학습할 때는 모든 문제를 해결해 줄 것처럼 느껴지지만 은탄환은 없으며 개발이라는 것은 트레이드오프이며 무언가를 얻으면 반드시 무언가를 어느 정도는 손해 볼 수밖에 없다. 하지만 그 손해 정도를 줄이는 것이 경험이고 실력이라고 생각한다. 만약 위에 언급한 부분을 철저히 지키고 있다면 얻은 것은 무엇이며 그 선택으로 인해 필연적으로 잃어버린 것은 무엇인지, 반대로 이것들을 지키지 않고 있다면 그로 인해 얻은 것과 잃은 것은 무엇인지 많은 개발자들이 고민해 보고 토론해 봤으면 한다.
]]>
<p>좋은 코드 설계를 위한 고민들을 평소에 많이 해왔고, 그에 관련한 학습들도 진행했었다. OOP, DDD, Clean Code, Clean Architecture 등등을 통해서 나름의 주관이 생겼으며 경력 초반에는 이런 것들을 지키기 위해 많이 노
IntelliJ 자주 사용하는 기능 및 추천 플러그인 정리https://cheese10yun.github.io/intellij-tip/2023-06-03T15:00:00.000Z2023-07-12T01:18:47.151ZTab
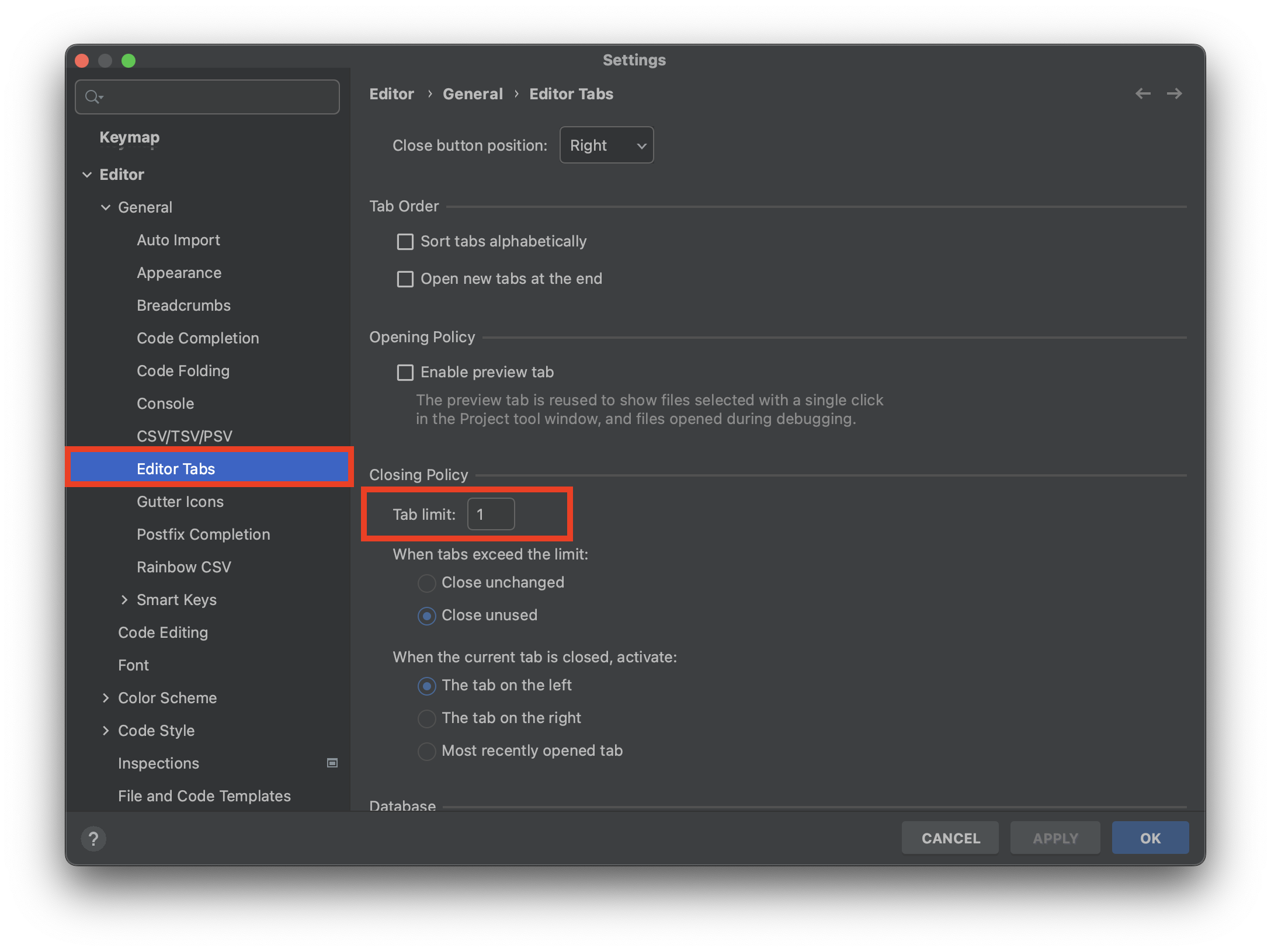
Tab Limit
settings -> editor tabs -> Tab Limit으로 Tab limit 설정 가능
여러 Tab을 켜도 Limit 한 설정값으로 유지, Limit 1을 추천
자주 사용하는 Tab 이동
Name
Hot Key
Desc
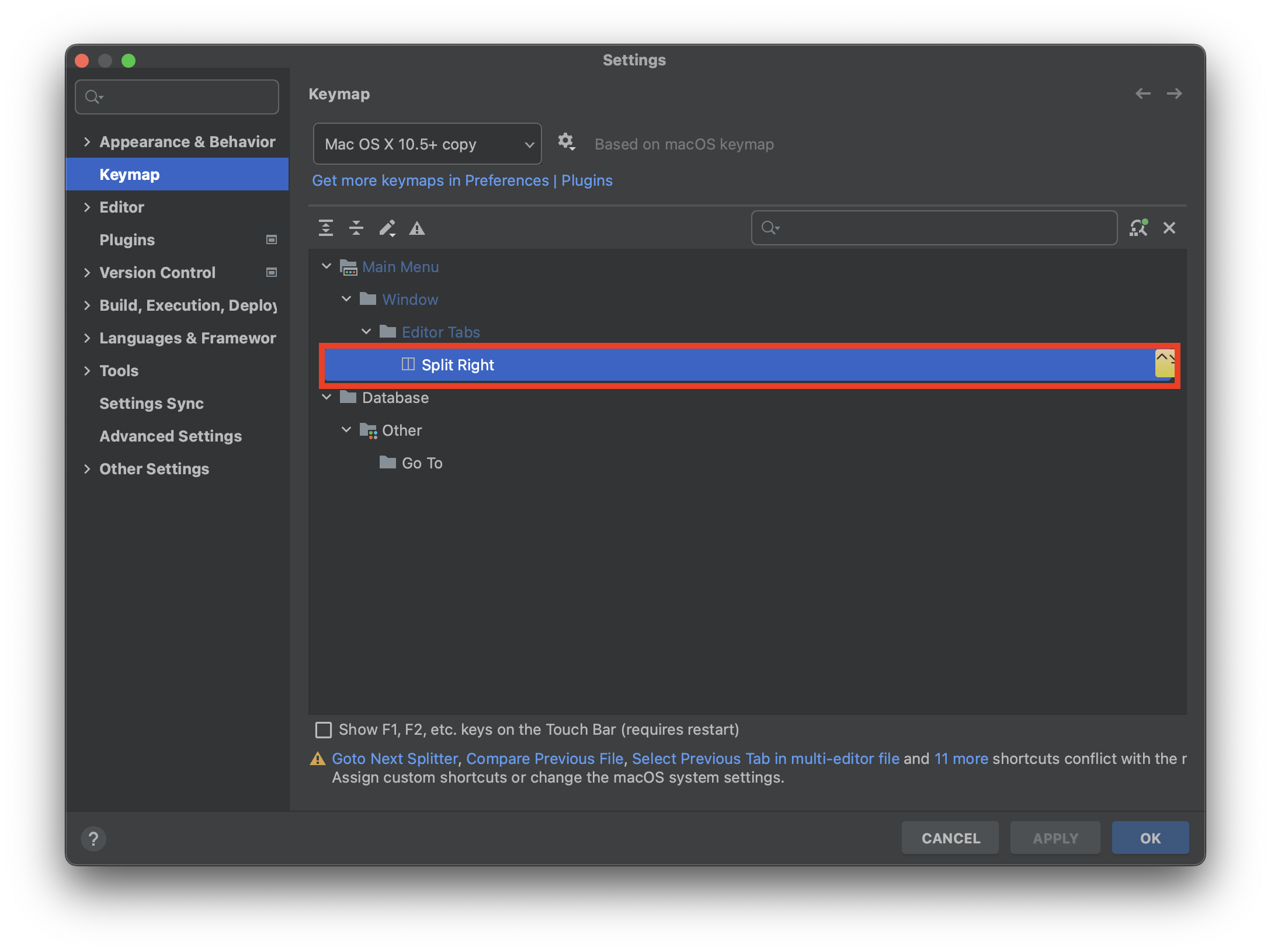
Split Right
fn + ctr + ➡️
현재 화면 오른 쪽으로 분활
Split Down
fn + ctr + ⬇️
현재 화면 아래 쪽으로 분할
Goto Next Splitter
shift + cmd ➡️
현재 포커싱 화면애서 다음 Tab으로 이동
Goto Previous Splitter
shift + cmd ⬅️
현재 포커싱 화면애서 이전 다음 Tab으로 이동
<- Back
cmd + [
현재 Tab의 이전 Tab, tab limit 1 지정시 유용
-> Forword
cmd + ]
현재 Tab의 다음 Tab, tab limit 1 지정시 유용
Recent Files
cmd + e
최근 Open 파일 리스트
Recent Locations
shift + cmd + e
최근 Open 파일 커서 위치
Bookmarks 지정
cmd + F3
북마크 지정
Bookmarks
F3
지정한 북마크 리스트
Go to file
shift + cmd + o
파일 열기
간단 팁
Find Action
특정한 기능을 찾고 싶은 경우 단축키 shift + cmd + a Find Action으로 해당 기능을 찾을 수 있음
대충 이런 기능이 있지 않을까 하는 기능을 검색을 통해서 해당 기능의 유무를 빠르게 파악 가능 ex) git stash
Key map
Key map 통해서 Hot Key 조회 및 등록 가능
키워드를 통해 검색 or 단축키를 통한 검색도 지원
Live Template
코드 템플릿을 미리 지정해서 편하게 코드를 작성할 수 있는 기능입니다.
sout, psvm 등이 여기에 해당합니다.
ss, tdd, jobc, jobcode, comment-formattersf 등등을 커스텀 해서 사용
등록 방법
Settings -> Live Templates
formatter 코드 정렬 제외
1 2 3 4 5 6 7 8 9 10
funasd(): Unit { //@formatter:off val a = 10 val b = 10// 코드 정렬에서 제외 val c = 10 val d = 10 val e = 10 val f = 10 //@formatter:on }
특정한 이유로 코드 정렬을 제외하고 싶을 때 @formatter:off ~ @formatter:on을 활용하여 제외할 수 있다.
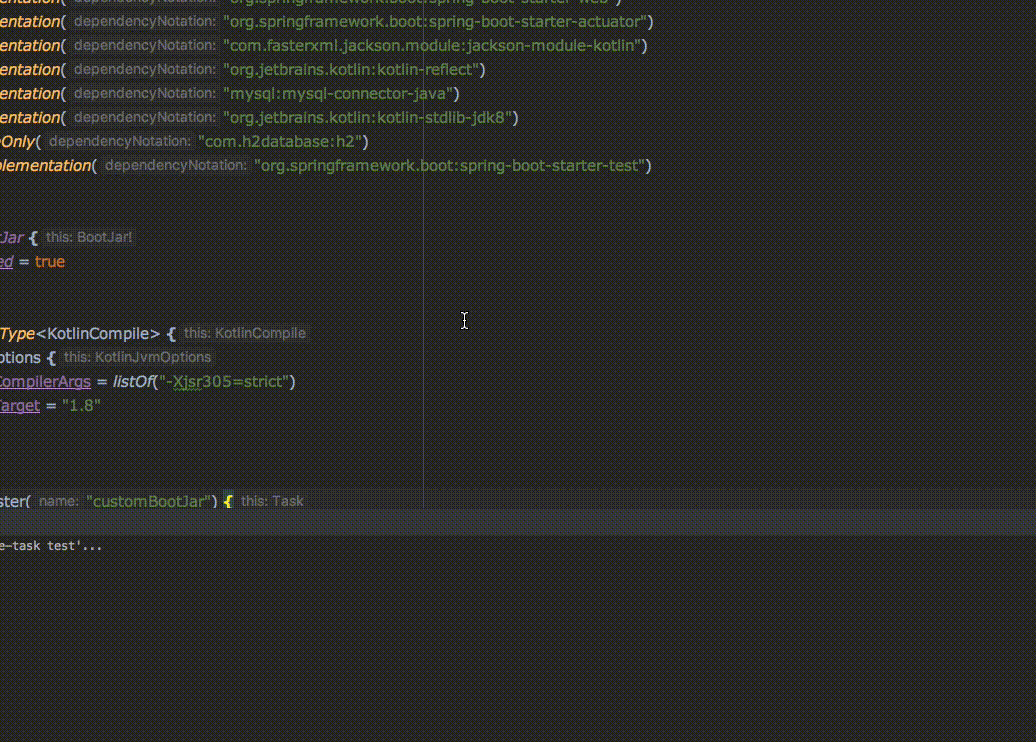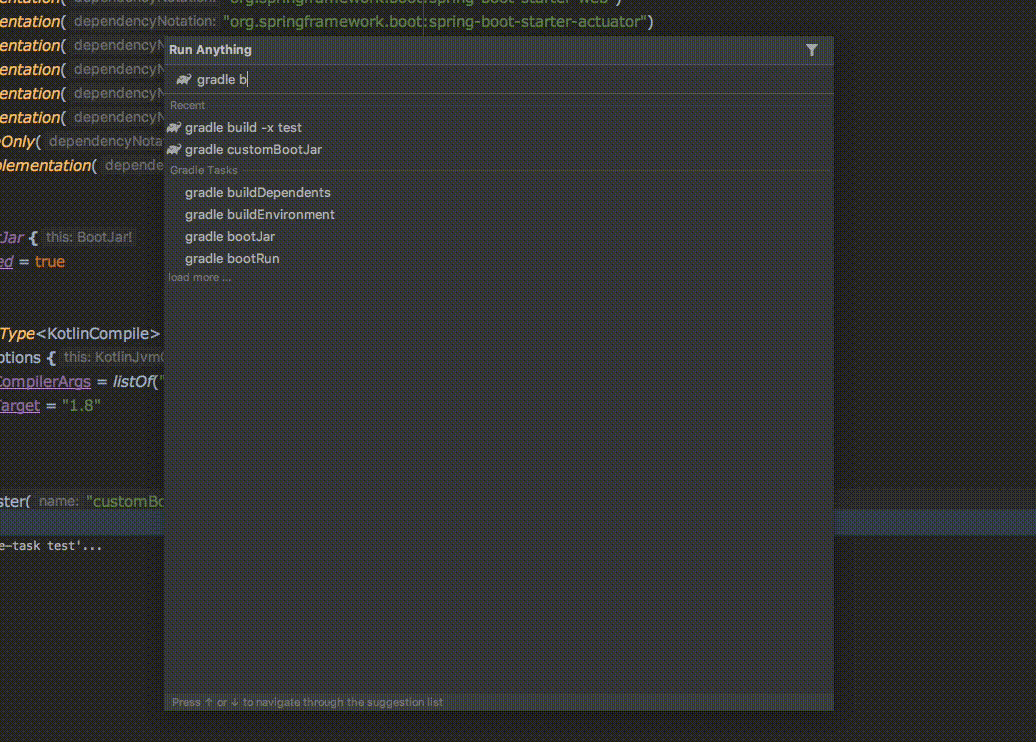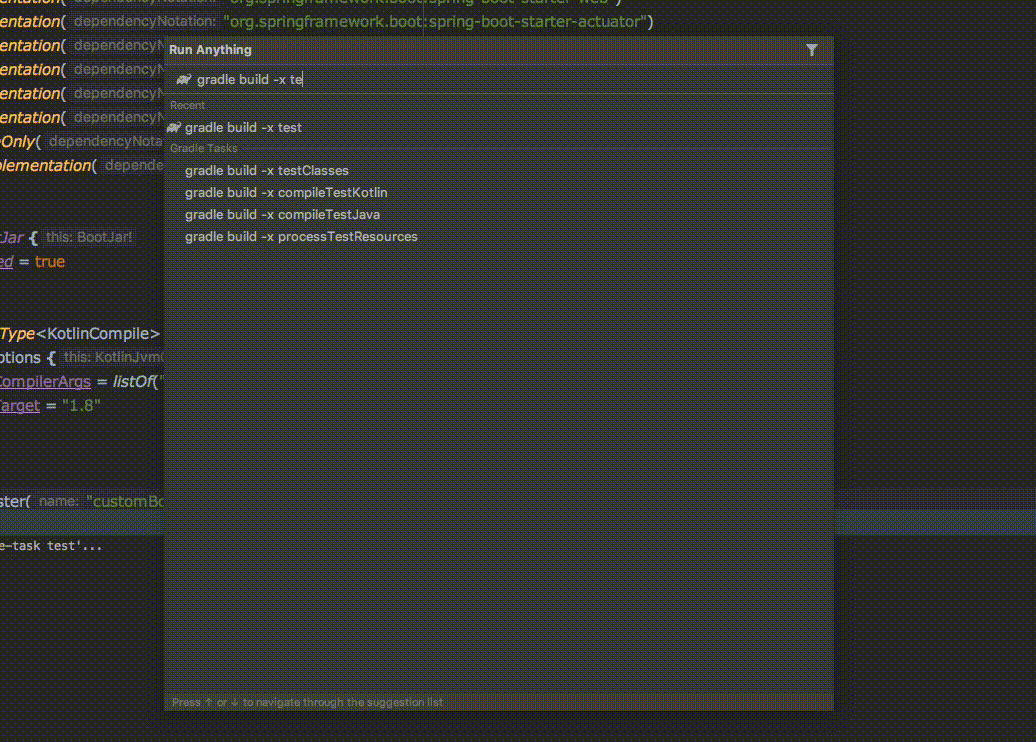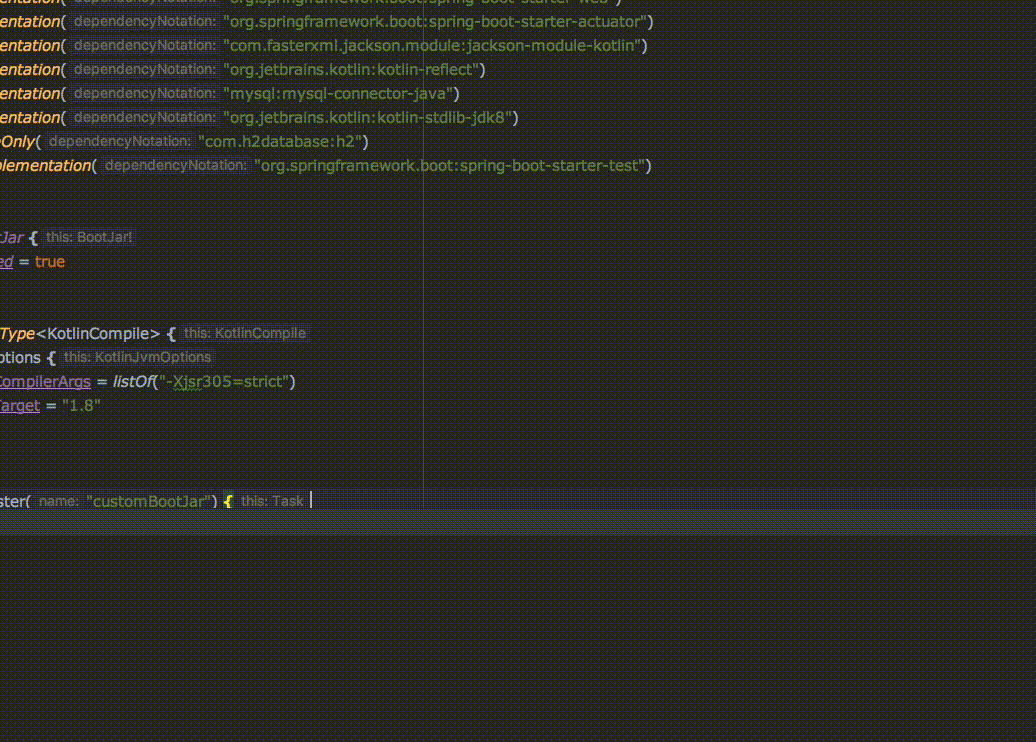
Gradle Task
Gradle Task 자동 완성 기능을 통해서 보다 쉽게 Gradle 명령어를 사용할 수 있습니다.
build.gradle.kts에 직접 작성한 TASK도 동작 가능
문자열
동일 문자열 ⌘ + ⌃ + g
동일 위치열 ⌥ + drag or ⌥⌥
복사 히스토리 command + shift + v
활용 방법
특정 Entity를 응답 객체로 만들어야 하는 경우 동일 문자열을 복사해서 보다 쉽게 Response 객체를 만들 수 있습니다.
// (1) val groupingBy = orders .groupingBy { it.status }
// (2) val aggregate = groupingBy .aggregate { key, accumulator: OrderPrice?, element, first -> when { first -> OrderPrice(orderStatus = key, price = element.price) else -> OrderPrice(orderStatus = key, price = accumulator!!.price + element.price) } }
val totalPrice1 = aggregate[OrderStatus.COMPLETE_ORDER] val totalPrice2 = aggregate[OrderStatus.COMPLETE_PAYMENT]
// (3) val eachCount = groupingBy.eachCount() val count1 = eachCount[OrderStatus.COMPLETE_ORDER] val count2 = eachCount[OrderStatus.COMPLETE_PAYMENT] } }
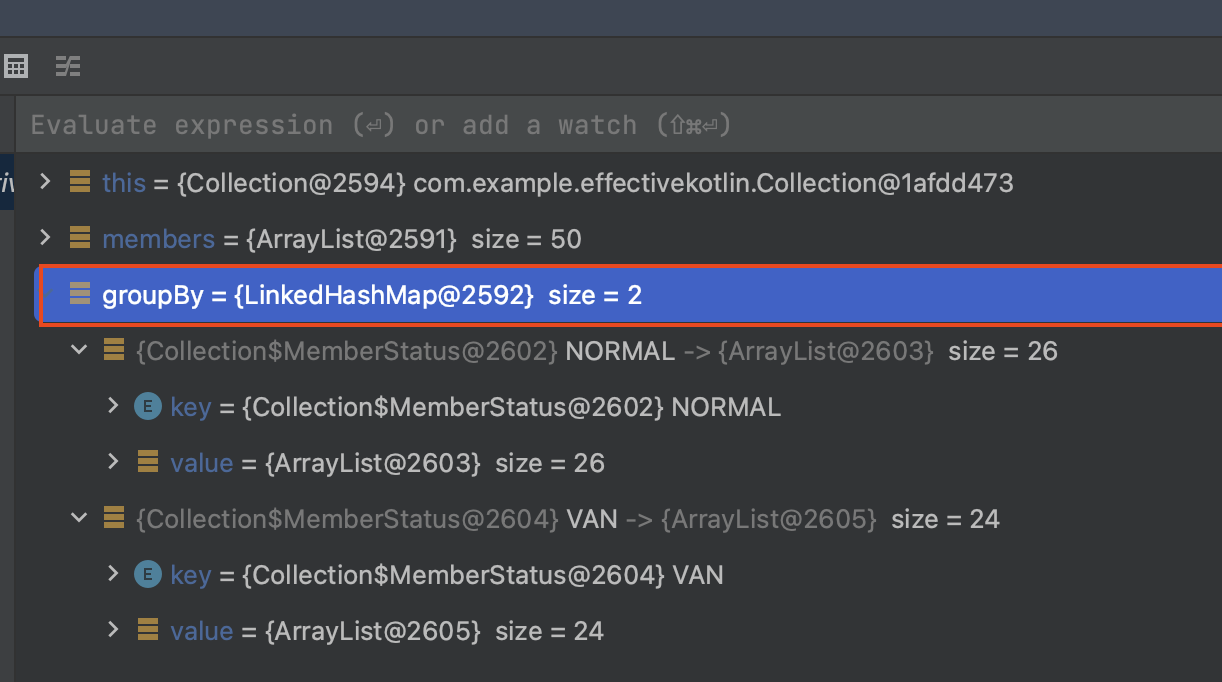
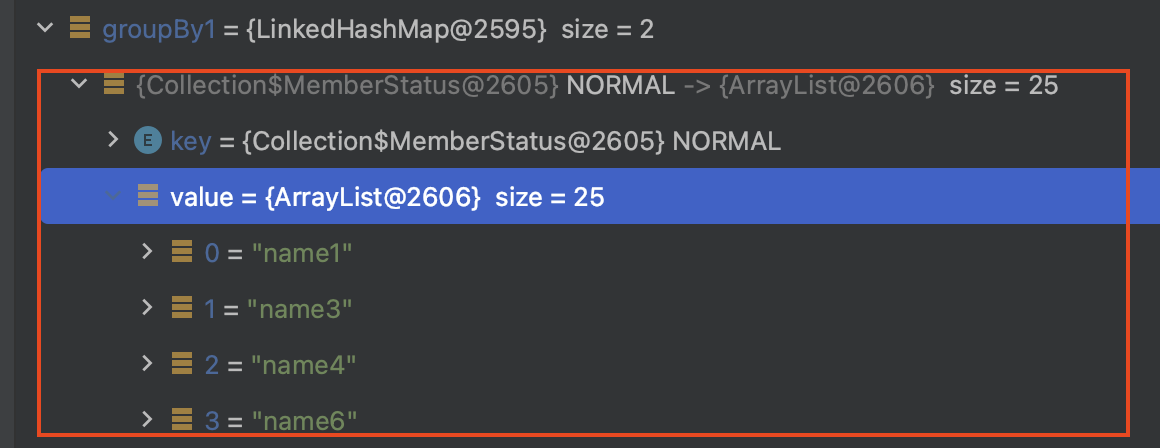
groupingBy는 컬렉션에 대해서 그룹화하여 이후 다양한 연산을 편리한 제공할 수 있는 Grouping 객체로 리턴해줍니다.
(1) groupingBy으로 Grouping 객체로 응답받고 해당 확장함 수로 다양한 연산 작업이 가능합니다. (2) aggregate으로 groupingBy된 값 기반으로 가격에 대한 sum 작업, (3) eachCount으로 groupingBy된 카운트를 조회 가능합니다.
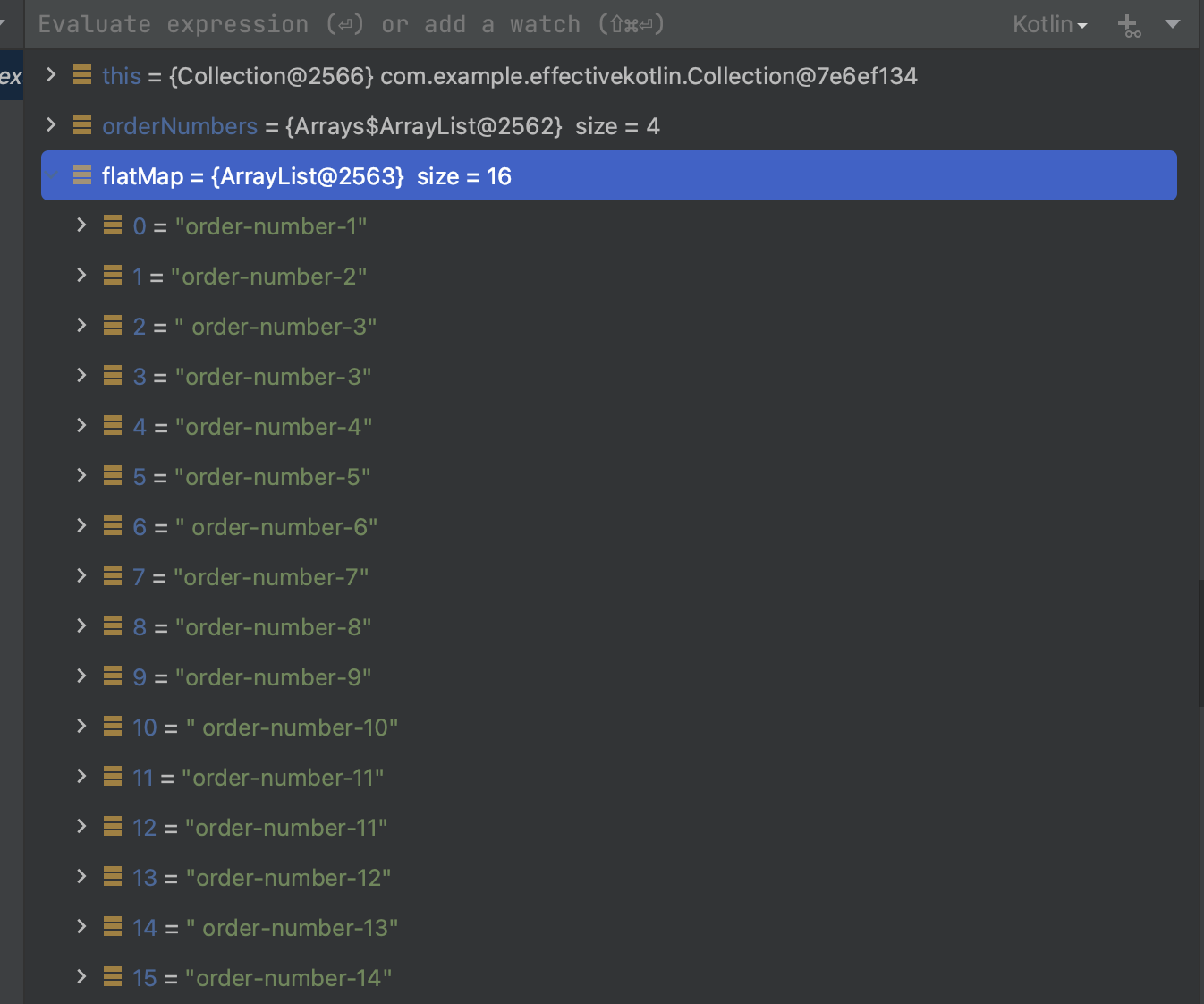
val flatMap = orderNumbers.flatMap { it.orderNumbers } } }
flatMap은 여러 컬렉션을 합쳐서 하나의 컬렉션으로 합쳐줍니다. 위처럼 여러 컬렉션 객체 안의 컬렉션 객체가 있는 경우 하나의 컬렉션으로 flatMap을 통해서 합칠 수 있습니다.
orderNumbers로 각 객체에 있던 값들을 한 컬렉션으로 합쳐진 것을 확인할 수 있습니다.
]]>
<h2><span id="groupby">groupBy</span></h2>
<figure class="highlight kotlin"><table><tr><td class="gutter"><pre><span class="line">1</span><b
Spring Batch 업데이트 성능 최적화 및 분석https://cheese10yun.github.io/spring-batch-update-performance/2022-11-12T14:41:19.000Z2023-09-05T14:57:09.590Z아래와 같은 시나리오의 경우 배치 애플리케이션 성능을 높이기 위한 방법에 대한 내용을 정리했습니다.
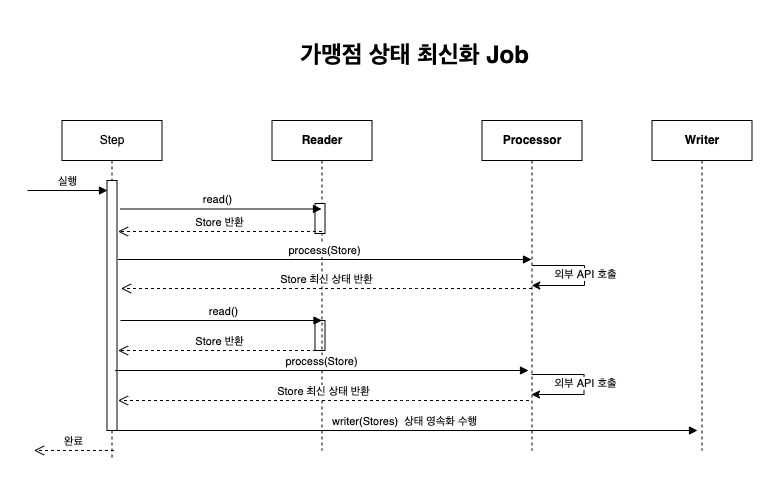
시나리오
해당 배치 애플리케이션은 등록되어 있는 가맹점(Store)에 대한 상태를 외부 API를 단건으로 조회하여(단건 API만 존재) 가맹점 상태를 OPEN("오픈"),, CLOSE("폐업"), 업데이트하는 애플리케이션입니다.
Reader에서 Store(Item)을 ChunkSize 만큼 읽어 옵니다.
읽어온 Store(Item)을 한 건씩 Processor에서 외부 API를 호출하여 최신 가맹점 상태를 응답받아 가공 처리합니다.
가공된 데이터를 Chunk 단위만큼 쌓이면 Writer에 전달하고 Writer는 업데이트 작업을 진행합니다.
위와 같은 Step의 Job이 있는 경우 단일 스레드 기반의 가장 직관적인 JpaWriter 방법, RxKotlin을 이용한 멀티 스레드 방식의 RxWriter, 마지막으로 RxKotlin과 BulkUpdate를 진행하는 RxAndBulkWriter 방식에 대한 Step 코드 샘플과, 실제 성능 측정 정리 하였습니다.
@Bean @StepScope funupdatePerformanceReader( entityManagerFactory: EntityManagerFactory ) = JpaCursorItemReaderBuilder<StoreProjection>() .name("updatePerformanceReader") .entityManagerFactory(entityManagerFactory) .queryString("SELECT NEW com.batch.payment.domain.store.StoreProjection(s.id, s.status) FROM Store s where s.createdAt >= :createdAt ORDER BY s.id DESC") .parameterValues(mapOf("createdAt" to localDateTime)) .build() }
JpaCursorItemReader 기반으로 성능 측정에서 모드 동일한 리더를 사용했습니다. JPA를 사용한다면 배치 애플리케이션에는 대량 처리 시 Entity 객체를 리턴하는 것이 아니라 Projections 객체를 리턴하는 것을 권장합니다. JPA에서 지원해 주는 Dirty Checking 기반으로 업데이트를 진행할 이는 거의 없으며, 있더라도 merger 기능이 동작할 때 select 쿼리가 한 번 더 발생할 위험도 있으며 Lazy Loading으로 추가 조회를 하는 경우도 거의 없습니다. 무엇보다도 처리할 데이터 rows가 많고 해당 테이블에 칼럼이 맞은 경우 JPA에서 이전에 언급한 기능들 및 다른 기타 기능들을 사용하기 위해서 더 많은 메모리를 사용하게 되기 때문에 성능적인 측면에 유의미한 차이가 있어 가능하면 Projections 객체를 리턴하는 것이 좋습니다.
// Query DSL 기반 업데이트 overridefunupdateStatus(id: Long, status: StoreStatus) = update(qStore) .set(qStore.status, status) .where(qStore.id.eq(id)) .execute() }
가장 일반적이고 직관적인 배치 흐름입니다. Processor에서 단건 조회 API를 조회하여 데이터를 가공하고 Writer에서 Query DSL 기반으로 업데이트를 진행합니다. 이렇게 처리하면 total rows * 150ms만큼 소요 시 간이 발생하게 되기 때문에 데이터 모수에 큰 영향을 받습니다.
Rx 기반 멀티 스레드 Writer 처리
total rows * 150ms만큼 소요되기 때문에 처리할 수 있는 스레드 수만큼 작업 시간이 줄어들며 이론 상 rows 1,000 * 150ms / 10 Thread(Parallel(10)) 만큼 처리 시간을 단축시킬 수 있습니다. 해당 포스팅은 RxKotlin 기반으로 스레드 처리를 진행합니다.
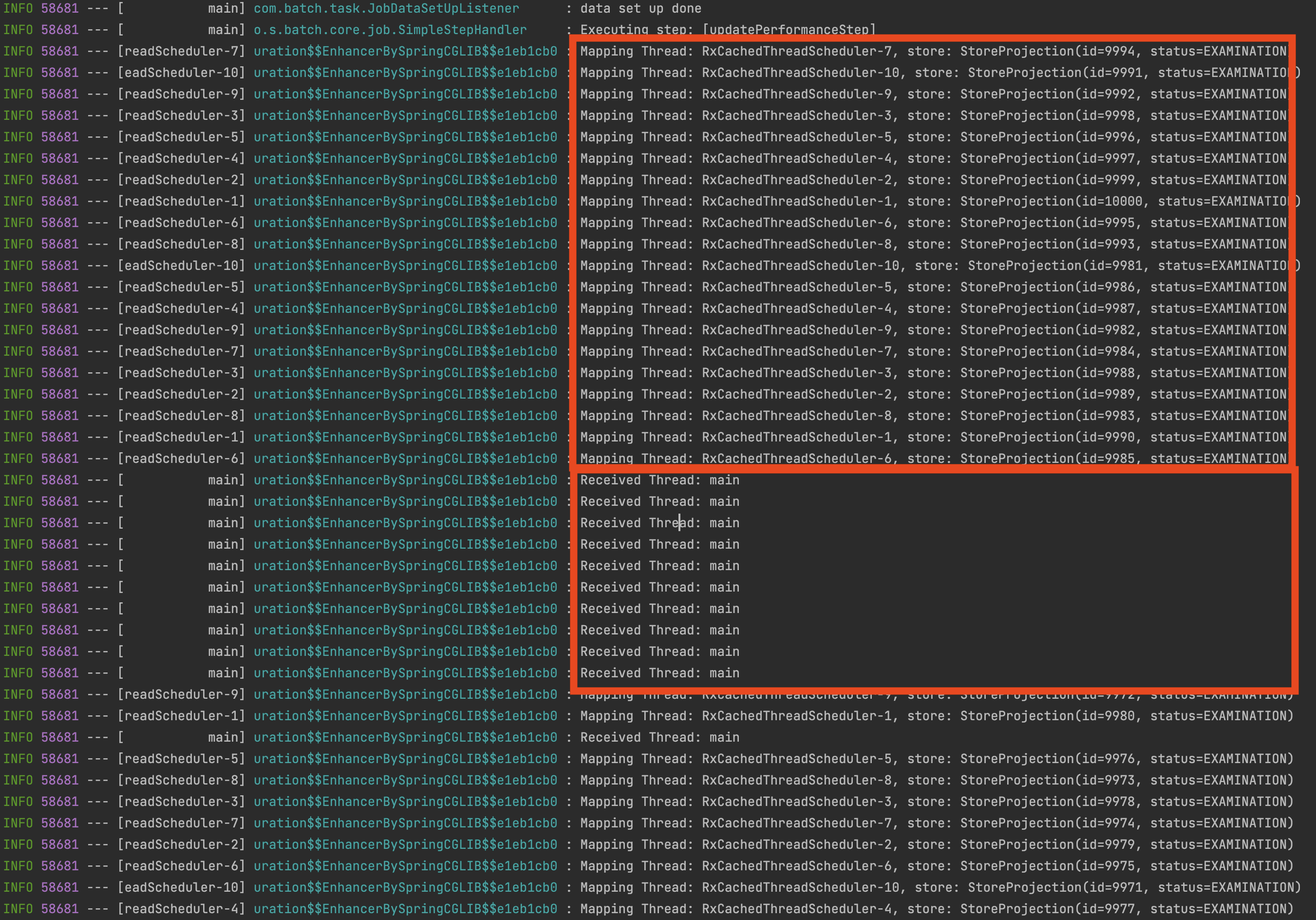
privatefunrxWriter(): ItemWriter<StoreProjection> { return ItemWriter { stores -> stores .toFlowable() .parallel() // (1) .runOn(Schedulers.io()) // (2) .map { store -> // 속도 특정 시에는 주석 log.info("Mapping Thread: ${Thread.currentThread().name}, store: $store") // 사업자 최산 상태 조회 150ms 이후 응답 Pair(store, latestStoreStatusObtainer.getLatestStoreStatus(store.id)) } .sequential() // (3) .blockingSubscribe( // (4) { store -> // 속도 특정 시에는 주석 log.info("Received Thread: ${Thread.currentThread().name}") val second = store.second store.first.status = second }, { log.error(it.message, it) }, { // (5) for (store in stores) { storeRepository.updateStatus( id = store.id, status = store.status ) } } ) } } }
(1): stores를 병렬화하여 위 이미지처럼 레일을 만들며 레일에게 발송할 수 있게 합니다.
(2): Schedulers.io()를 통해서 ParallelFlowable의 병렬 처리 수준만큼 Scheduler.createWorker를 호출해서 스레드를 생성합니다.
(3): sequential를 통해서 parallel에서 여러 레일을 생성하는 것을 다시 단일 시퀀스로 병합합니다.
(4): 해당 레일이 정상 종료, 오류가 발생하기 전까지 Blocking 합니다.
(5): 단일 시퀀스로 병합이 완료되고 Query DSL 기반으로 업데이트를 진행합니다.
Writer에서 넘겨받은 stores 객체를 병렬 처리하기 때문에 더 이상 Proccsor가 필요하지 않습니다. 배치 애플리케이션에서 Proccsor에서 데이터 가공 처리하는 것은 역할 책임의 분리로는 적절하나 I/O 작업처럼 상대적으로 느린 작업이 있으면 Proccsor에서 처리하지 않고 가능하면 Writer에서 벌크(병렬) 처리하는 것이 성능적으로 큰 이점이 있습니다.
RxCachedThreadScheduler-1~10으로 10개의 스레드로 데이터를 사업자 최산 상태 조회를 하고 있으며 이후 blockingSubscribe의 onNext는 메인 스레드로 다시 전달받는 것을 확인할 수 있습니다. runOn()에 각자 환경에 맞는 Schedulers를 적절하게 사용하면 되며 모든 테스트는 10개의 스케줄러 스레드 기반으로 테스트를 진행했습니다.
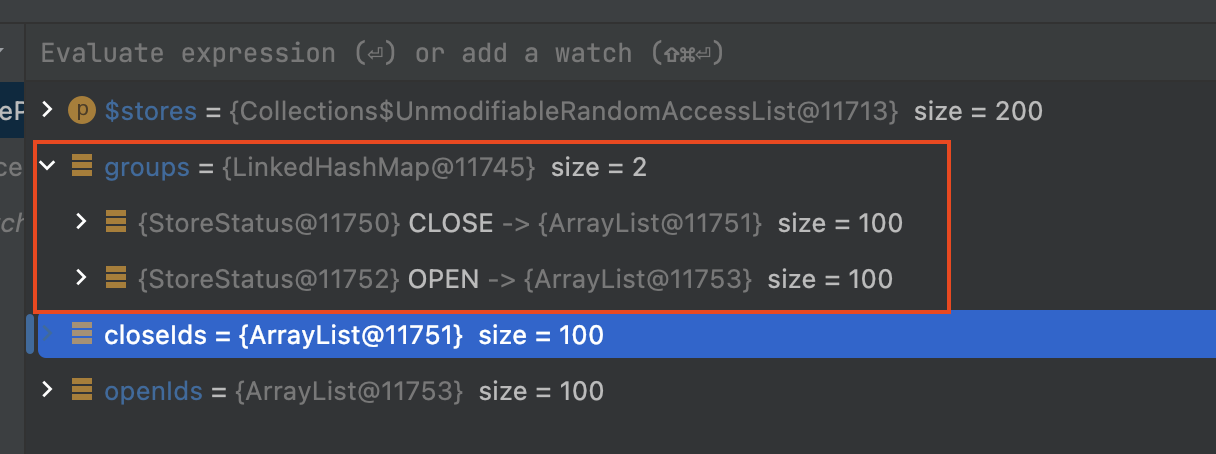
privatefunrxAndBulkWriter(): ItemWriter<StoreProjection> { return ItemWriter { stores -> stores .toFlowable() .parallel() .runOn(Schedulers.io()) .map { store -> // 속도 특정 시에는 주석 log.info("Mapping Thread: ${Thread.currentThread().name}, store: $store") // 사업자 최산 상태 조회 150ms 이후 응답 Pair(store, latestStoreStatusObtainer.getLatestStoreStatus(store.id)) } .sequential() .blockingSubscribe( { store -> // 속도 특정 시에는 주석 log.info("Received Thread: ${Thread.currentThread().name}") val second = store.second store.first.status = second }, { log.error(it.message, it) }, { // 속도 특정 시에는 주석 log.info("onComplete Thread: ${Thread.currentThread().name}") // (1) val groups = stores.groupBy({ it.status }, { it.id }) // (2) val closeIds = groups[StoreStatus.CLOSE] ?: emptyList() val openIds = groups[StoreStatus.OPEN] ?: emptyList()
// (3) if (closeIds.isNotEmpty()) { storeRepository.updateStatus(ids = closeIds, status = StoreStatus.CLOSE) } if (openIds.isNotEmpty()) { storeRepository.updateStatus(ids = openIds, status = StoreStatus.OPEN) } } ) } } }
(4): Query DSL where id in 기반으로 일괄 업데이트, 디비 서버와 네트워크 I/O 최소화
onComplete으로 최종 결과를 main Thread로 받는 것을 확인했습니다.
이전 Rx과 거의 동일하며 Query DSL 업데이트 처리하는 방식만 달라졌습니다. Chunk 단위로 데이터를 모아서 가맹점 상태를 기준으로 그룹화를 진행하며, 그룹화를 통해서 ids 통해서 DB 업데이트를 진행합니다. Chunk 단위로는 DB 서버와 최대 2번의 통신을 하기 때문에 기존 방식 대비 네트워크 I/O가 크게 줄어들게 됩니다. 모든 테스트는 로컬 DB 서버와 통신을 했기 때문에 JpaWriter, RxWriter 방식에서 네트워크 I/O에 비용이 크게 발생하지 않았지만 실제 운영 환경에서는 네트워크 I/O 비용이 커짐에 따라 더 안 좋은 성능을 보여주게 되며, RxAndBulkWriter와의 차이는 더 발생할 것으로 보입니다.
JpaWriter는 단일 스레드, RxWriter는 10 스레드로 진행하여 대략적인 수치는 스레드 차이만큼의 결과를 보여주는 것을 확인할 수 있습니다. RxWriter와 RxAndBulkWriter의 차이는 대략 10% 정도 차이가 있습니다. 이 차이는 배치 애플리케이션과 DB 서버가 로컬에 있어 루프백으로 통신을 진행하여 차이가 크게 발생하지 않았으나 실제 환경에서는 더 유의미한 차이가 있을 것으로 보입니다. 네트워크 I/O 비용뿐만 아니라 트랜잭션을 점유하는 시간, 커넥션을 맺고 있는 시간 등등 그룹화하여 where in 절로 처리가 가능하다면 이렇게 처리하는 것이 훨씬 더 효율적이라고 판단됩니다.
또 RxAndBulkWriter 경우 where in으로 처리하기 때문에 ChunkSize를 늘리면 더 성능이 좋을 것으로 생각했지만 5,000 보다 1,000 Chunk가 더 좋은 성능이 좋았습니다. 아마 Rx에서 스레드를 알맞게 나누고 그것을 다시 병합하는 과정의 비용이 비싸기 때문이라고 추정됩니다. 대량 처리를 진행하는 경우는 각 환경에 맞는 ChunkSize를 측정하여 사용하는 것이 바람직해 보입니다.
]]>
<p>아래와 같은 시나리오의 경우 배치 애플리케이션 성능을 높이기 위한 방법에 대한 내용을 정리했습니다.</p>
<h2><span id="시나리오">시나리오</span></h2>
<p>해당 배치 애플리케이션은 등록되어 있는 가맹점(Store)에 대한
MySQL Batch Update 성능 측정 및 분석https://cheese10yun.github.io/mysql-batch-update/2022-11-06T15:00:00.000Z2023-07-12T02:12:16.460ZMySQL 기반으로 대량 업데이트를 진행하는 경우 JPA, Exposed 프레임워크 기반으로 테스트를 진행했습니다. 결론부터 말씀드리면 Exposed 기반 Batch Update가 가장 빨랐습니다. 물론 JPA에서도 addBatch 방식을 진행하면 유의미한 속도 차이는 없을 것 같아 보이나 Exposed가 addBatch 기능을 직관적으로 지원하고 있어 addBatch 방식은 Exposed를 사용했으며 JPA는 영속성 컨텍스트 기반인 Dirty Checking Update, 영속성 컨텍스트가 필요 없는 ID 기반 업데이트를 진행했습니다.
@Test internalfun `dirty checking update test`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val total = 500 val map = (1..total).map { Writer( name = "old", email = "old" ) } // 데이터 셋업, 속도 측정 포함 X setup(map) // 데이터 조회, 속도 특정 X val writers = writerService.findAll()
val stopWatch = StopWatch() // 업데이트 속도 측정 stopWatch.start() writerService.update(writers) stopWatch.stop()
@Test internalfun `none persistence context update test`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val total = 500 val map = (1..total).map { Writer( name = "old", email = "old" ) } // 데이터 셋업, 속도 측정 포함 X setup(map) val findAll = writerService.findAll()
// 업데이트 속도 측정 val stopWatch = StopWatch() stopWatch.start() writerService.nonPersistContestUpdate(findAll.map { it.id!! }) stopWatch.stop()
// 영속성 컨텍스트 없는 업데이트 @Transactional overridefunupdate(ids: List<Long>) { for (id in ids) { update(qWriter) .set(qWriter.name, "update") .where(qWriter.id.eq(id)) .execute() } } }
JPA에서는 Persistence Context 기반인 Dirty Checking을 통한 업데이트와, Persistence Context 없이 상태의 업데이트를 진행했습니다.
@Test fun `update`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val totalCount = 500 val ids = (1..totalCount).map { it.toLong() } // 데이터 셋업, 속도 측정 포함 X setup(ids)
// 데이터 셋업, 속도 측정 포함 X val stopWatch = StopWatch() stopWatch.start() for (writerId in ids) { Writers .update({ Writers.id eq writerId }) { it[email] = "update" } } stopWatch.stop() println("${ids.size} update, ${stopWatch.lastTaskTimeMillis}") }
@Test fun `bulk update`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val totalCount = 500 val ids = (1..totalCount).map { it.toLong() } // 데이터 셋업, 속도 측정 포함 X setup(ids)
// 업데이트 속도 측정 val stopWatch = StopWatch() stopWatch.start() BatchUpdateStatement(Writers).apply { ids.forEach { addBatch(EntityID(it, Writers)) this[Writers.email] = "update" } } .execute(TransactionManager.current())
Exposed는 일반 업데이트와, addBatch를 통한 batch update를 진행 행했습니다.
addBatch란 ?
JDBC 드라이버에서는 addBatch()를 제공하고 있습니다. 이 기능은 rewriteBatchedStatements 옵션을 활성화하면 MySQL Connector/J가 addBatch() 함수로 레코드를 모아 MySQL 서버로 전달합니다. 일반적으로 Batch Insert를 진행할 때 많이 사용하는 옵션으로 Batch Insert 성능 향상기 1편 - With JPA, Batch Insert 성능 향상기 2편 - 성능 측정에서 다룬 적 있습니다. Insert 쿼리 같은 경우는 addBatch()를 사용하면 다음과 같은 형태로 묶어서 실행시켜 줍니다.
1 2 3 4 5 6
-- addBatch() 사용시 단일 insert에서 아래 SQL 형태로 변경 insertinto writer (`name`, `email`, `created_at`, `updated_at`) values ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442'), ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442'), ... ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442');
Update 쿼리는 형식의 변경은 없지만 레코드를 모아서 한 번에 MySQL 서버로 전달하여 네트워크 통신을 최소화할 수 있습니다.
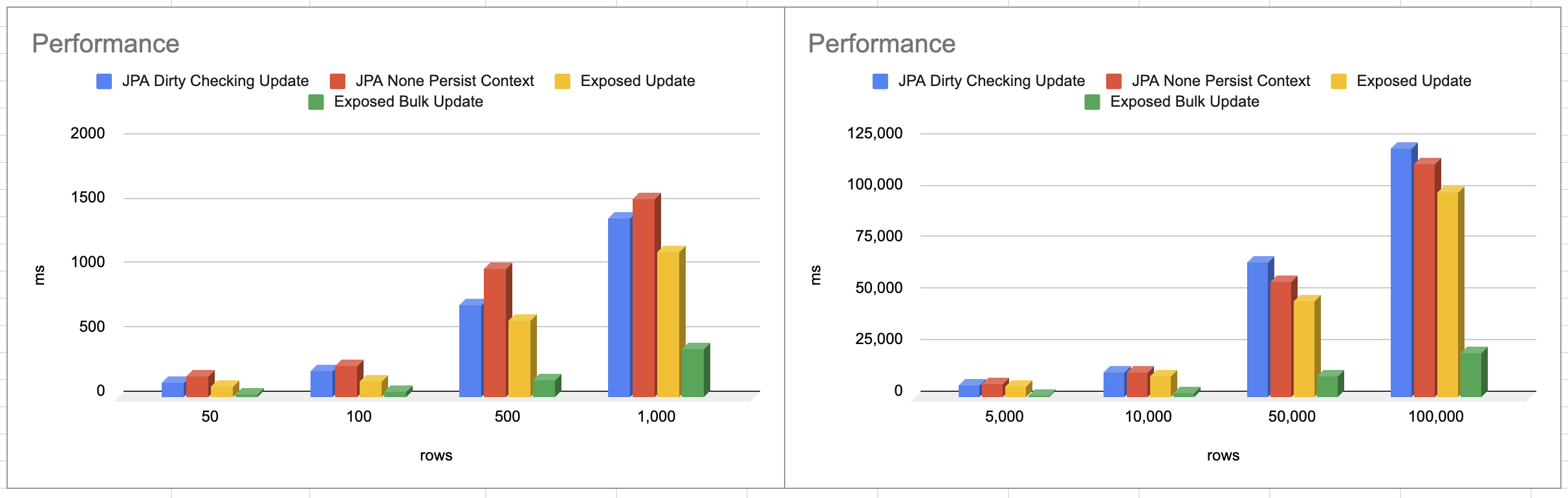
Performance 측정 및 분석
rows
JPA Dirty Checking Update
JPA None Persistence Context
Exposed Update
Exposed Bulk Update
50
115 ms
167 ms
80 ms
23 ms
100
206 ms
242 ms
130 ms
40 ms
500
71 8ms
994 ms
596 ms
135 ms
1,000
1,388 ms
1,540 ms
1,130 ms
381 ms
5,000
6,204 ms
6,441 ms
5,121 ms
1,127 ms
10,000
12,151 ms
12,209 ms
10,094 ms
2,227 ms
50,000
65,309 ms
56,295 ms
46,506 ms
10,355 ms
100,000
120,906 ms
11,3194 ms
99,349 ms
21,370 ms
해당 테스트 환경은 로컬 애플리케이션에서 로컬 MySQL 통신으로 진행했기 때문에 네트워크 리소스 비용이 크게 발생하지 않았음에도 Exposed 기반의 Batch Update 성능이 가장 좋았습니다. 실제 운영 환경에서는 물론 Exposed Bulk Update도 시간이 더 오래 걸리겠지만 다른 업데이트 방법들은 네트워크 리소스가 높아짐에 따라 더 많은 시간이 발생할 것으로 보입니다.
그리고 JPA에서는 Dirty Checking Update, None Persistence Context의 성능 차이는 생각보다 크게 발생하진 않았습니다. 물론 영속성 컨텍스트가 반드시 필요하니 조회에 대한 부분까지 포함 시키면 유의미한 차이가 있을 것으로 보입니다. 하지만 이런 대량 조회의 경우 영속성 컨텍스트를 통하지 않고 Projections을 사용하는 것이 일반적이라 그 부분까지 테스트하진 않았습니다. JPA 기반으로 대량 데이터를 조회하는 경우 가능하면 Projections을 사용하는 것을 권장 드립니다. 그리고 이런 대량 데이터를 처리하는 특성상 배치 애플리케이션으로 구성하고 Chunk 단위로 데이터를 처리하기 때문에 100,000 정도의 데이터를 처리하는 것은 권장하진 않습니다. 데이터 모수와 처리 시간에 대한 상관관계를 확인하기 위해 작업했습니다.
실제 운영 환경에서의 네트워크 통신 비용에 따라서 addBatch() 방식과, 그렇지 않은 단건 업데이트 방식의 처리 시간은 더 차이가 날것으로 보이며, 구조적으로 큰 변경 없이 데이터 업데이트 방식만 바꾸는 것으로 6배 가까운 향상이 있기 때문에 대용량 업데이트 처리를 하고 있다면 권장 드립니다. JPA는 정말 좋은 ORM 프레임워크가 생각이 들지만 대량 처리에 대한 도구로는 적절하지 않다는 생각이 많이 듭니다. MySQL 기반의 대용량 처리를 진행하는 경우 다른 적절한 도구를 찾아보는 것이 좋을 거 같습니다.
]]>
<p>MySQL 기반으로 대량 업데이트를 진행하는 경우 JPA, Exposed 프레임워크 기반으로 테스트를 진행했습니다. 결론부터 말씀드리면 Exposed 기반 Batch Update가 가장 빨랐습니다. 물론 JPA에서도 addBatch 방식을 진행하
테스트 대역폭 늘리기https://cheese10yun.github.io/test-bandwidth/2022-10-15T15:00:00.000Z2022-10-16T07:16:06.000Z다양한 케이스에 대한 테스트 대역폭을 늘려서 테스트 코드를 작성하는 것은 중요한 작업입니다. 로직이 복잡하고 다양한 케이스에 대응하는 코드가 있다면 이러한 테스트 대역 폭은 더욱 중요합니다. 본 포스팅은 다양한 케이스에 대한 커버리지를 높이는 방법에 대한 방법에 관한 내용입니다.
funorder( productId: Long, orderDate: LocalDate, orderAmount: BigDecimal, shopId: Long, couponCode: String? ): String { // 상품 정보는 Elasticsearch에서 조회 val product = productQueryService.findById(productId) // 환율 정보는 Redis에서 조회 val exchangeRateResponse = exchangeRateClientImpl.getExchangeRate(orderDate, "USD", "KRW") // 쿠폰 정보는 MySql에서 조회 val coupon = couponQueryService.findByCode(couponCode) // 가맹점 정보는 MySql에서 조회 val shop = shopQueryService.findById(shopId)
/** * 복잡한 로직... * 1. 상품 정보 조회 하여 금액 및 상품 재고 확인, 재고가 없는 경우 예외 처리 등등 * 2. 환율 정보 조회 하여 특정 국가 환율로 계산 * 3. 쿠폰 정보 조회하여 적용 가능한 상품인지 확인, 가맹점과 할인 금액 부담 비율 등등 계산 * 4. 가맹점 정보 조회하여 수수료 정보등 조회 */
// 영속화 val orderNumber = save( productId, exchangeRateResponse.amount, )
return orderNumber } }
주문에 대한 sample code가 위처럼 작성되어 있는 경우 적어도 10~20개의 시나리오에 대한 테스트는 필요하다고 생각합니다. 하지만 해당 테스트 코드를 작성하기 위해서는 많은 어려움이 있습니다. 서비스 구조가 커지면 특정 문제를 해결하기 위한 다양한 인프라를 갖추게 됩니다. 위 코드도 각 데이터 특성에 맞는 저장소에 저장하고 조회하고 있습니다. 이런 경우 테스트 코드를 작성하기 위해서는 Given 절에 해당하는 곳에서 해당 인프라에 대한 데이터 셋업이 반드시 필요합니다. 이 작업의 어려움 때문에 다양한 케이스의 테스트 코드 작성이 어렵다고 생각합니다.
중요한 것은 관심사
테스트 코드를 작성하는 것은 해당 코드의 주요 관심사에 대한 테스트 코드를 작성하는 것입니다. 그렇다면 위 코드의 중요 관심사는 각각의 인프라에서의 조회, 복잡한 로직...에의 데이터 처리입니다. 두 가지 관심사에 대한 테스트 코드를 작성해야 하고 그 다양한 테스트 케이스에 대한 커버를 해야 하기 때문에 어려움이 있는 것입니다. 물론 중요 관심사라는 것은 대부분 명확하게 나눠지지 않고 항상 애매합니다. 로직이 복잡할수록 이러한 현상이 나타납니다. 그러기 때문에 테스트 코드를 작성하다 보면 설계의 경계선에 대한 피드백을 받을 수 있다는 점이 매우 유용한 장점이라고 생각합니다.
funorder( productId: Long, orderDate: LocalDate, orderAmount: BigDecimal, shopId: Long, couponCode: String? ): String { // 상품 정보는 Elasticsearch에서 조회 val product = productQueryService.findById(productId) // 환율 정보는 Redis에서 조회 val exchangeRateResponse = exchangeRateClientImpl.getExchangeRate(orderDate, "USD", "KRW") // 쿠폰 정보는 MySql에서 조회 val coupon = couponQueryService.findByCode(couponCode) // 가맹점 정보는 MySql에서 조회 val shop = shopQueryService.findById(shopId)
// 복잡한 로직... OrderServiceSupport 객체로 위임 val order = OrderServiceSupport().order(...)
val order = save(order)
return order.orderNumber } }
복잡한 로직...관련 로직을 OrderServiceSupport 객체로 위임합니다. 해당 코드의 주관심사는 다양한 인프라에 해당하는 조회를 정상적으로 진행했는지에 대한 코드를 작성합니다. 각각의 인프라 조회는 해당 서비스 로직에서 주요 관심사로 보고 테스트를 진행하기 때문에 order에서는 중복적인 테스트는 불필요하다고 생각하며 몇 가지 간단한 케이스에 대해서 Order 객체가 영속 화가 알맞게 되었는지 검증하는 테스트 코드를 작성합니다.
/** * Spring Bean Context와 인프라스트럭처의 관련 코드가 없는 순수한 POJO */ classOrderServiceSupport{
/** * 각각의 인프라의 조회 책임을 위임 하여 복잡한 로직 작성... 에대한 관심사만 갖는다. */ funorder( product: Product, orderDate: LocalDate, orderAmount: BigDecimal, exchangeRateResponse: ExchangeRateResponse, shop: Shop, coupon: Coupon?, ): Order {
/** * 복잡한 로직... * 1. 상품 정보 조회 하여 금액 및 상품 재고 확인, 재고가 없는 경우 예외 처리 등등 * 2. 환율 정보 조회 하여 특정 국가 환율로 계산 * 3. 쿠폰 정보 조회하여 적용 가능한 상품인지 확인, 가맹점과 할인 금액 부담 비율 등등 계산 * 4. 가맹점 정보 조회하여 수수료 정보등 조회 */ return Order( ... ) } }
internalclassOrderServiceSupportTest{
@Test internalfun `쿠폰 적용 없는 주문 생성`() { //given // 순수하게 POJO 기반으로 데이터를 만들고 테스트를 진행하기 때문에 자연스럽게 비즈니스 로직에만 집중 할 수 있습니다. val product = Product( productId = ..., amount = ..., currency = ... ) val orderDate = LocalDate.of(2022, 2, 2) val orderAmount = 100.toBigDecimal() val exchangeRateResponse = ExchangeRateResponse( 1222.12.toBigDecimal() ) val shop = Shop( feeRate = 0.023.toBigDecimal() )
복잡한 로직(데이터 처리) 관심사만 갖는 객체를 만들어 해당 데이터에 대한 처리를 진행합니다. 이때 해당 객체는 Spring Bean Context 및 인프라스트럭처의 관련 코드가 없이 동작하는 순수한 POJO 객체로 만들어 데이터 처리를 진행합니다. Given 절에서 외부 환경에 대한 의존성이 없이 다양한 테스트 케이스를 쉽게 작성할 수 있으며 인프라 및 기타 환경에 구애받지 않기 때문에 비즈니스 로직의 관심사에만 자연스럽게 집중할 수 있게 됩니다.
]]>
<p>다양한 케이스에 대한 테스트 대역폭을 늘려서 테스트 코드를 작성하는 것은 중요한 작업입니다. 로직이 복잡하고 다양한 케이스에 대응하는 코드가 있다면 이러한 테스트 대역 폭은 더욱 중요합니다. 본 포스팅은 다양한 케이스에 대한 커버리지를 높이는 방
외부 인프라스트럭처 테스트https://cheese10yun.github.io/external-infrastructure-testing/2022-10-09T15:00:00.000Z2023-07-12T01:17:10.895Z외부 인프라를 의존하는 로직의 경우 테스트 코드를 작성하기 어려운 부분이 있습니다. 예를 들어 특정 날짜 기준으로 환율 정보를 기반으로 금액을 계산하고, 그 환율 정보를 외부 HTTP Server에 질의한다고 하면 HTTP Server가 외부 인프라라에 해당합니다. 이런 경우 대부분 Mocking을 하여 테스트 코드를 작성하게 됩니다. 이전 포스팅 Mockserver Netty 사용해서 HTTP 통신 Mocking 하기에서 다룬 적이 있습니다. 해당 포스팅은 라이브러리에 대한 사용법을 설명한 것이고 본 포스팅은 외부 인프라스트럭처를 효율적으로 관리하는 방법론에 대한 개인적인 생각을 정리했습니다. 외부 인프라의 대표적인 예가 HTTP Server를 호출하는 것이라서 설명을 그 기준으로 하는 것이고 다른 외부 인프라를 사용하더라도 해당 방법이 적절한 대한이 될 수 있습니다.
//when val orderNumber = orderService.order(1L, LocalDate.of(2022, 2, 2), 100.toBigDecimal())
//then val findOrder = orderQueryService.findOrderNumber(orderNumber) then(findOrder.amount).isEqualByComparingTo(140000.toBigDecimal()) }
로컬 환경에 Mock Server를 띄워 Given 절에 미리 요청/응답을 정의한 것으로 동작하게 합니다.
문제점
다양한 케이스에한 커버리지
물론 위처럼 정말 간단한 코드는 위 형식처럼 작성하는 것이 적절한 해결법이 될 수 있다고 생각합니다. 하지만 로직이 복잡하여 다양한 케이스에 대한 커버리지를 확보하기 위해서는 어려움이 있습니다. 20220202 기준일 이외의 테스트 시 Given 절에 해당하는 요청/응답을 미리 정의해야 합니다. 1개의 객체를 처리하는 것은 어렵지 않으나 여러 객체를 처리하기 위해서는 어려움이 있습니다. 그리고 getExchangeRate() 메서드를 사용하는 모든 구간에서 동일하게 Mocking을 진행해야 합니다.
테스트의 관심사
order()메서드의 주 관심사는 주문을 객체를 환율 정보를 기반으로 영속화하는 것입니다. 그렇다는 것은 order() 테스트하는 관점도 해당 관점에서 진행해야 한다고 생각합니다. 즉 HTTP 통신의 관심사는 아니라고 생각하며 테스트 코드는 해당 관심사에 맞는 테스트를 진행해야 한다고 생각합니다.
해결 방법 Interface
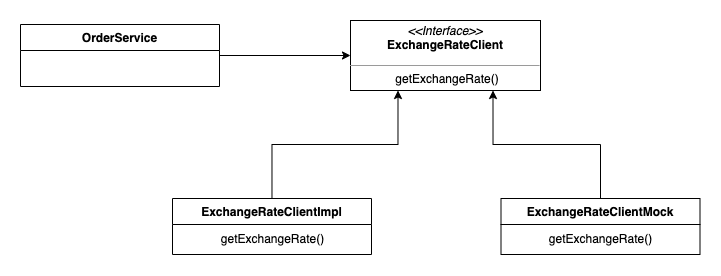
결과적으로 다양한 케이스를 커버하기 위해서는 실제 Mock 서버로 커버하는 것은 비효율적이고 무엇보다 중요한 것은 order라는 관점에서 실제 외부 HTTP 통신이 큰 관심사가 아니라고 생각합니다. 그렇다면 Mocking을 진행한다면 HTTP 통신에 대한 Mocking을 하는 것보다 객체 자체를 Mocking 하는 것이 더 좋다고 생각합니다.
Interface를 두고 실제 HTTP 통신을 하는 실제 구현체는 ExchangeRateClientImpl에서 진행하고, 테스트 코드 또는 일부 환경에서 구현체는 ExchangeRateClientMock을 사용하게 합니다.
@Configuration classAppConfiguration{ @Bean @Profile("production | sandbox")// 특정 환경에서만 등록 하는 경우 // @Profile("!test") // 특정 환경만 제외하는 경우 funexchangeRateClient() = ExchangeRateClientImpl() }
@Configuration을 통해서 Bean으로 등록할 실제 구현 객체를 작성합니다. 이때 @Profile을 통해서 특정 환경에서만 등록시킬지, 특정 환경에서만 제외할지 프로젝트에 특성에 맞게 조절하면 됩니다. 다음으로는 테스트에서 사용할 Mock 구현체로 테스트에서만 사용하는 것이라고 하면 test scope에 위치 시켜 실제 동작하는 코드 환경과 분리시키는 것이 바람직합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
└── src ├── main │ ├── kotlin │ │ └── com │ │ └── example │ │ └── demo │ │ └── ExchangeRateClientImpl.kt │ └── resources │ └── application.yml └── test └── kotlin └── com └── example └── demo └── ExchangeRateClientMock.kt
위 경로처럼 test scope에서 ExchangeRateClientMock 객체를 위치 시켜 테스트 환경 외에는 해당 객체에 접근 못하도록 합니다.
테스트 환경에서 사용할 설정 클래스인 @TestConfiguration 객체를 만들고 테스트 환경에서만 Bean이 등록 가능하도록 설정합니다. 그리고 실제 Mocking의 Given 절에 해당하는 코드를 작성합니다. 즉 20220202 날짜의 경우 USD > KRW 환율이 12000으로 내려오게 설정합니다. order에 관심사는 해날 날짜에 환율 정보 기반으로 주문 금액이 정상적으로 영속화의 여부이기 때문에 미리 정의된 환율 정보 기반으로 정상적으로 금액이 잘 되었는지 검증하는 Then 절에 해당하는 테스트 코드를 작성합니다. Mock 구현체를 test 스코프에 위치 시켰지만 일반 main 위치 시키는 경우도 있습니다. 예를 사용해야 하는 외부 인프라가 특정 환경을 갖추지 못하는 경우, 외부 호출 경우 비용이 추가적으로 발생하는 경우 등등 이런 경우에서는 main 클래스에 위치 시키고 해당 환경에서 Mock 객체를 동작 시키는 것도 가능합니다. 물론 Mockito와 같은 테스트 도구를 이용하면 위와 같은 비슷한 방법으로 테스트가 가능합니다. 하지만 몇 가지 문제점들과 실제 객체를 Mockg 하는 방법이 더 효율적이라고 생각하여 위에서 설명한 방법으로 외부 인프라스트럭처 테스트를 진행합니다.
특정 환경에서 다양한 이유로 해당 외부 인프라스트럭처를 이용하지 못하는 경우 Mock 객체로 갈아 끼우는 게 편리하다.
Mockito를 사용하면 단위 테스트 개념으로 실제 order가 영속화되었고 그 영속 화가 끝난 이후 데이터를 조회하여 실제로 원하는 형식으로 들어갔는지 테스트까지 어려우며, 내부 인프라에 대한 테스트가 또 필요 한 경우 거의 비슷한 테스트를 또 진행해야 합니다.
@Mockbean을 사용하는 경우 스프링 빈 컨텍스트가 n 번 올라가기 때문에 속도적인 측면에서 많은 손해가 발생한다.
외부 인프라를 의존하는 코드들에 모든 테스트에 Mockito와 같은 Given 절을 작성해야 합니다. 이는 HTTP Server를 Mocking 테스트와 동일하게 발생합니다.
다양한 케이스에 대해서 애플리케이션 로직으로 처리가 가능합니다. ExchangeRateClientMock 객체의 getExchangeRate 메서드는 정해진 날짜 외에는 15000.12이 응답하게 했습니다. 이처럼 다양한 케이스에 대해서 추가적으로 애플리케이션 단에서 직관적으로 추가 및 변경이 가능합니다.
이러한 이유들로 저는 Mockito와 같은 테스트 도구를 사용하지 않고 실제 Mock 객체를 직접 정의하여 사용합니다.
그렇다면 Mocking은 불필요한 것일까?
그렇다고 HTTP Server를 Mocking 하여 테스트하는 것은 의미가 없다고 할 수는 없습니다. 결국 중요한 것은 테스트의 관심사입니다. order 입장에서는 해당 행위가 큰 관심사가 아닐 수 있겠지만 getExchangeRate()메서드에서는 중요한 관점입니다. 즉 해당 테스트의 중요 관심사라면 Mocking 하여 테스트하는 것이 바람직합니다.getExchangeRate() 관심사는 요청/응답입니다. 즉 요청한 HTTP 파라미터들이 미리 정의된 값으로 나갔고 해당 요청에 따른 응답이 오면 그 응답을 적절하게 deserialize 하여 자신을 호출한 객체로 넘겨 줄 수 있는 지입니다.
이러한 관심사에 맞게 Givin 절에서 요청과 응답을 미리 정의하고 getExchangeRate() 메서드를 호출하면 Json 응답을 deserialize 하여 객체로 전달이 잘 되는지에 대한 관심사에 대해서 테스트 코드를 작성합니다. 외부 인프라에 대한 테스트도 마찬가지로 책임과 역할을 명확하게 구분하고 분리해야 한다고 생각합니다. 그렇지 않으면 특정 객체에 책임이 과중되고 결국 전체적인 설계 디자인이 좋지 않게 됩니다. 이러한 현상(냄새)를 가장 빠르게 눈치챌 수 있는 게 테스트 코드라고 생각합니다. 테스트 코드를 작성하다 보면 너무 많은 의존성이 필요 해지고 내가 검증하려는 관심사 외에도 다른 관심사에도 관여하게 되는 경우 문제가 있다고 빠른 피드백을 줄 수 있습니다. 저는 이것이 테스트 코드의 아주 큰 장점 중에 하나라고 생각합니다.
overridefungetExchangeRate( targetDate: LocalDate, currencyForm: String, currencyTo: String, ): ExchangeRateResponse { val response = "http://localhost:8080/exchange-rate" .httpGet( parameters = listOf( "targetDate" to targetDate, "currencyForm" to currencyForm, "currencyTo" to currencyTo ) ) .response()
if (response.second.statusCode / 100 != 2) { // HTTP Status Code 2xx 아닌 경우는 어떻게 throw IllegalStateException("HTTP Status Code: ${response.second.statusCode} ") } return response .first.responseObject<ExchangeRateResponse>(objectMapper) .third.get() }
getExchangeRate() 메서드에서 2xx 응답이 아닌 경우 예외를 발생시키는 코드를 추가했다고 가정하면 해당 메서드를 사용하는 오류가 발생해도 다음 로직을 이어 가야 하는 경우 try catch 묶는 해당 코드에서 예외 처리를 리팩토링 해야 합니다. 이러한 현상도 결국 역할과 책임이 과중 됐다고 생각합니다. getExchangeRate() 메서드는 HTTP 통신으로 요청/응답에 대한 역할과 책임을 갖고 그 부분만 충실하게 하면 됩니다. 예외 처리에 대한 특히 비즈니스 로직에 의한 핸들링은 관여하지 않는 것이 좋은 설계라고 생각합니다.
책임, 역활 분리
HTTP Client 책임 분리하기에서 포스팅한 적 있듯 내부, 외부 인프라스트럭처는 추상화 단계를 가지며 그 단계에서 본인의 역할과 책임에 대해서 성실하게 다 하는 것이 좋다고 생각합니다.
JPA를 사용하는 것으로 예를 들면 JpaRepository 영역은 ExchangeRateClient과 동일한 영역이라고 생각합니다. 특정 키값으로 조회하여 없는 경우 같은 비즈니스 영역의 책임을 JpaRepository에서 진행하지 않고 우리 비즈니스 로직을 풀어내는 서비스 영역에서 진행하는 것과 마찬가지로 HTTP 외부 통신도 동일하게 해당 요청/응답에 관한 부분만 책임을 부여하고 그 외의 영역에서는 다른 서비스 객체를 만들고 그 객체에서 핸들링하는 것이 좋다고 생각합니다. 결과적으로 테스트 커버리지를 넓혀 다양한 케이스에 대한 테스트 코드를 작성하기 위해서는 객체 간에 역할 책임을 명확하게 구분하고 본인의 영역에 대해서는 충실하게 수행하는 코드가 동반되어야 가능하다고 생각합니다.
정리
해당 테스트 방법이 대부분의 환경에서 적절한 대안이 될 수 있다고는 생각하지 않습니다. 그래도 제가 경험한 환경에서는 외부 인프라스트럭처에 대한 테스트에 대한 코드를 작성할 때는 하고자 하는 테스트의 중요 관심사가 아닌 경우 불필요한 Mocking에 많은 코드를 작성하는 것이 효율적이지 못하다고 생각했습니다. 그리고 무엇보다 중요하는 것은 어떤 계층을 어떻게 바라보고 어떻게 테스트해야 할 것인지에 대한 팀 내부 차원의 합의된 부분이 먼저 선행되어야 한다고 생각합니다. 다양한 테스트 기법을 공부하는 것도 좋지만 프로젝트로 일을 진행하고 있다면 팀 내에서 토론하여 최소한의 합의를 먼저 구하고 테스트에 대한 기법을 적용하는 것이 더 좋을 거 같습니다.
]]>
<p>외부 인프라를 의존하는 로직의 경우 테스트 코드를 작성하기 어려운 부분이 있습니다. 예를 들어 특정 날짜 기준으로 환율 정보를 기반으로 금액을 계산하고, 그 환율 정보를 외부 HTTP Server에 질의한다고 하면 HTTP Server가 외부 인
DataGrip 살펴 보기https://cheese10yun.github.io/data-grip/2022-09-25T15:00:00.000Z2023-07-12T01:12:47.102ZDataGrip은 JetBrains에서 만든 데이터베이스 및 SQL 용 크로스 플랫폼 IDE입니다. 자세한 소개는 DataGrip에서 확인 가능합니다.
다양한 제품들이 있지만 저는 DataGrip 선호하며 애용하고 있는 제품입니다. 공식 자료에서도 충분히 다양한 기능들을 소개해 주고 있지만 개인적으로 DataGrip에 좋은 기능들을 정리해 보겠습니다.
다양한 플랫폼 지원
DataGrip은 다양한 플랫폼을 지원하기 때문에 한 가지 도구를 이용하여 여러 플랫폼에 대한 제어가 가능합니다. 동일한 도구를 사용하기 때문에 단축키 및 플러그인 등을 그대로 사용이 가능하여 좋은 생산성을 제공해 줍니다.
조회한 데이터에 대한 가공
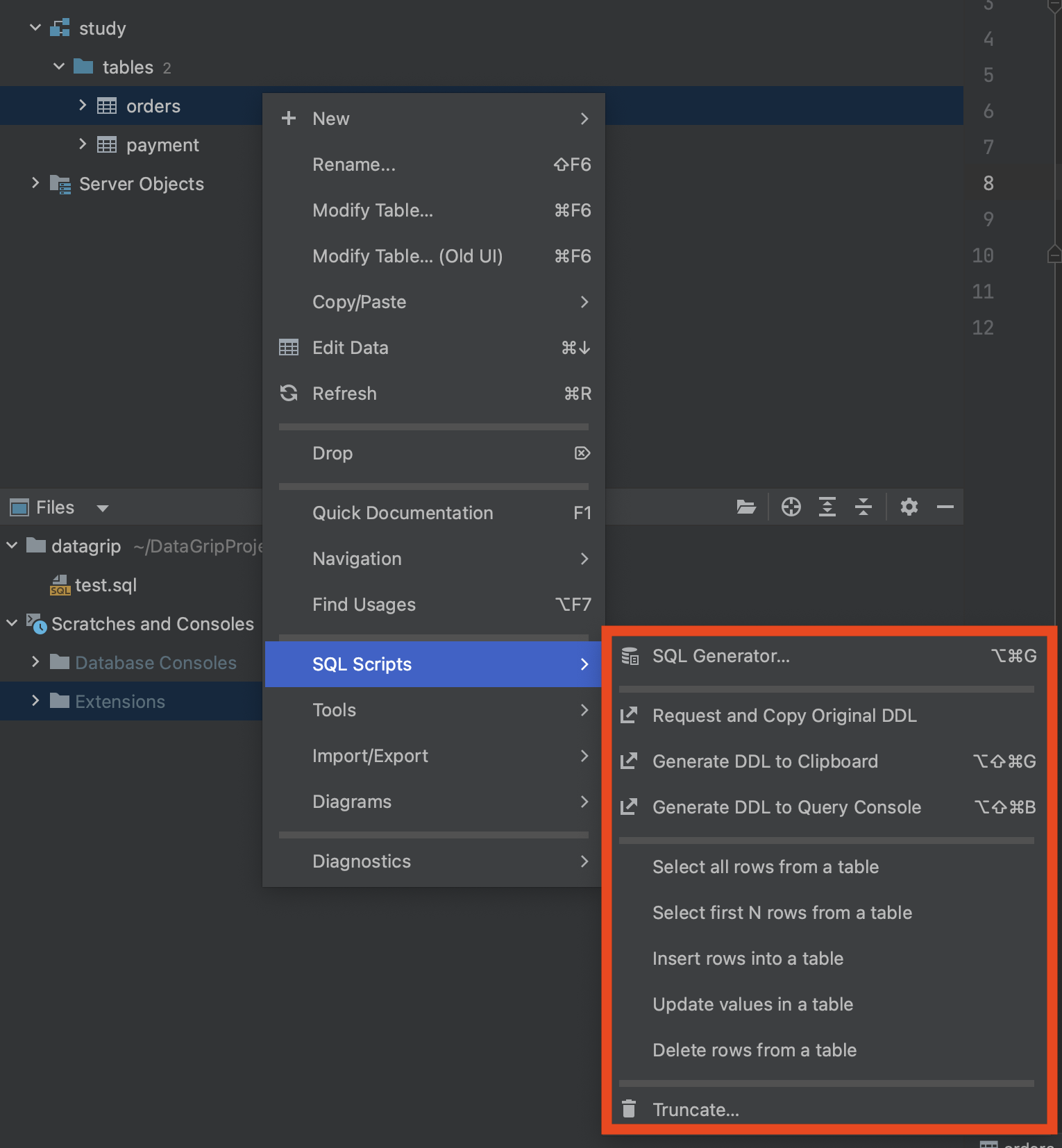
조회한 데이터를 다양한 형식으로 가공 처리를 도와줍니다. 데이터를 조회한 이후에 추출할 형식을 지정하고 원하는 데이터를 선택하고 복사하기만 하면 됩니다.
SQL Scripts 기능으로 도움 되는 기능들이 있습니다. 저 같은 경우에는 Generate DDL to Clibboard 기능을 자주 사용합니다. sandbox 환경에서 설계 및 개발을 진행하면서 테이블에 대한 변경이 이루어지기 때문에 처음에 작성한 DDL로 운영에 반영되는 일은 흔하지 않은 거 같습니다. 이렇게 설계가 다 끝난 시점에서 해당 DDL을 추출하여 운영에 반영합니다.
다양하고 편리한 플러그인 지원
Jetbrains에서 제공하고 있는 다양한 플러그인이 존재하며 다른 Jetbrains의 제품에서 사용하던 플러그인을 그대로 사용할 수 있습니다. 아래 소개한 플러그인 외에도 유용한 플러그인이 많기 때문에 플러그인 탭에서 다운로드 높은 순으로 정렬하여 좋은 플러그인을 찾아보는 것을 권장 드립니다.
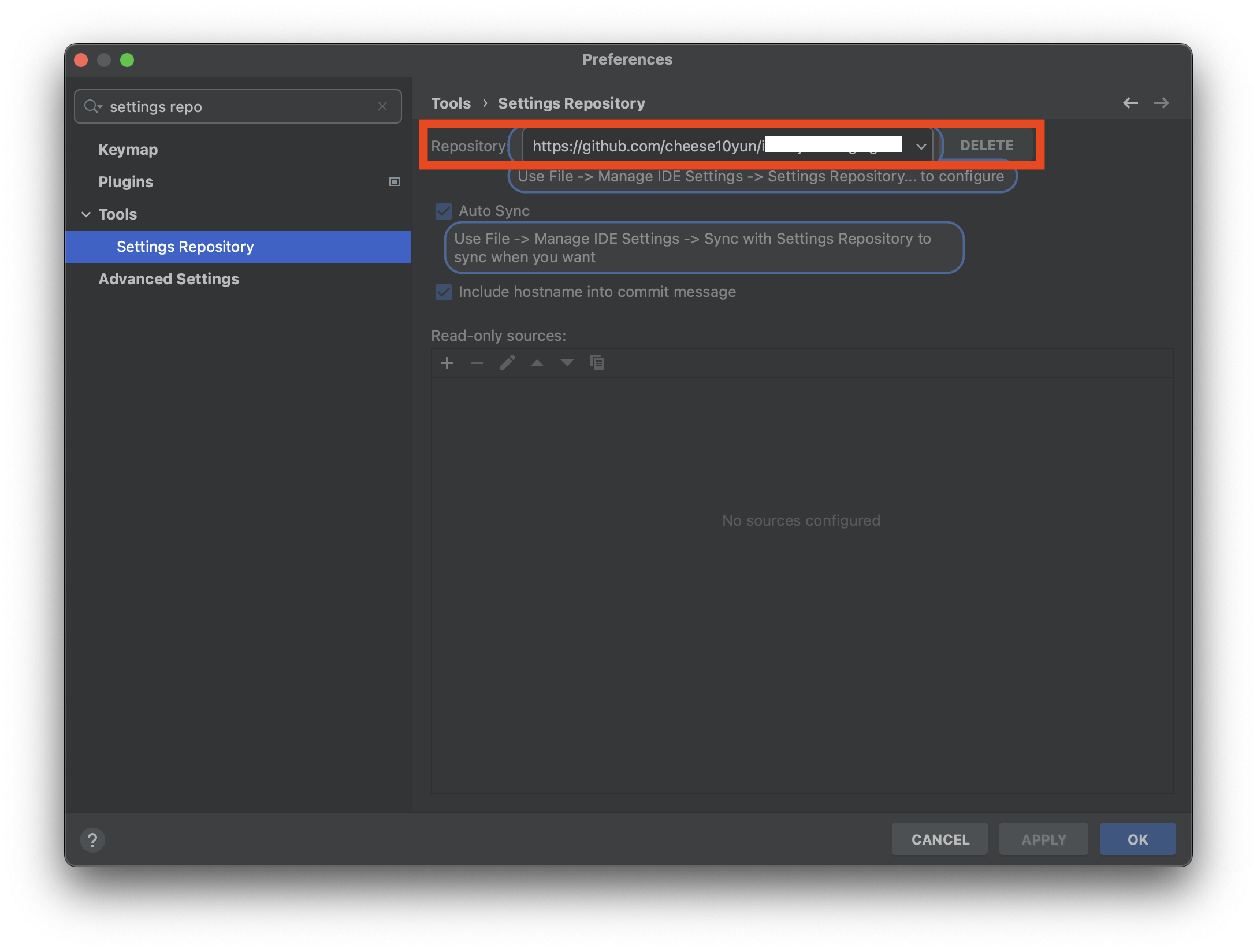
Settings Repositroy
Settings Repositroy는 해당 툴에 대한 단축키를 비롯한 다양한 설정을 Github에 저장하여 여러 환경에서 동일한 환경을 설정할 수 있게 해줍니다. 해당 설정은 XML으로 관리하며 변경 분을 Pull & Push 하여 설정을 동기화합니다. 저 같은 경우에는 단축키 및 다양한 설정들을 많이 하여 매우 유용하게 사용하고 있습니다.
해당 플러그인을 설치하고 File -> Manage IDE Settings -> Settings Repositroy...에서 본인의 깃헙 주소로 설정하면 됩니다.
String Manipulation
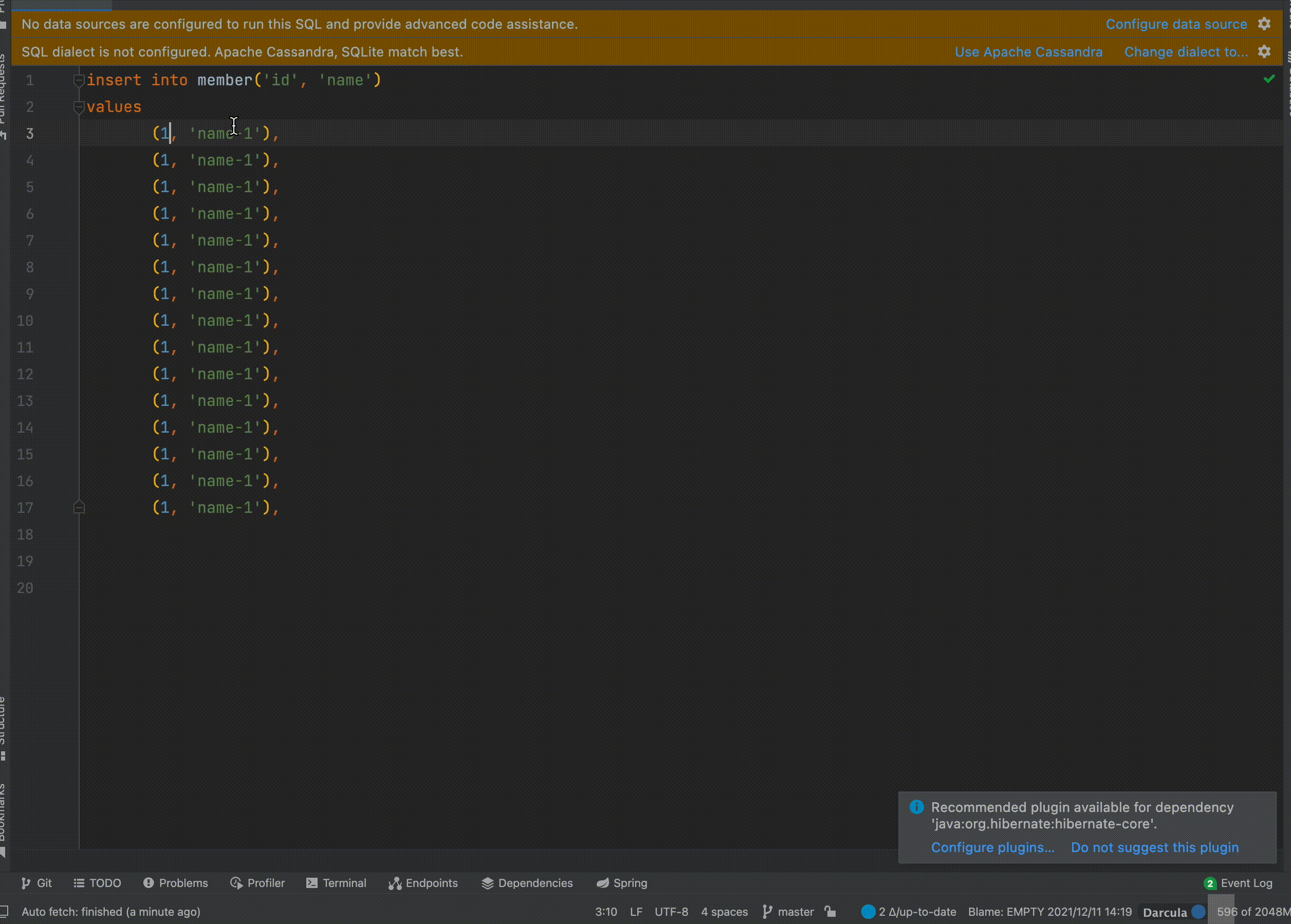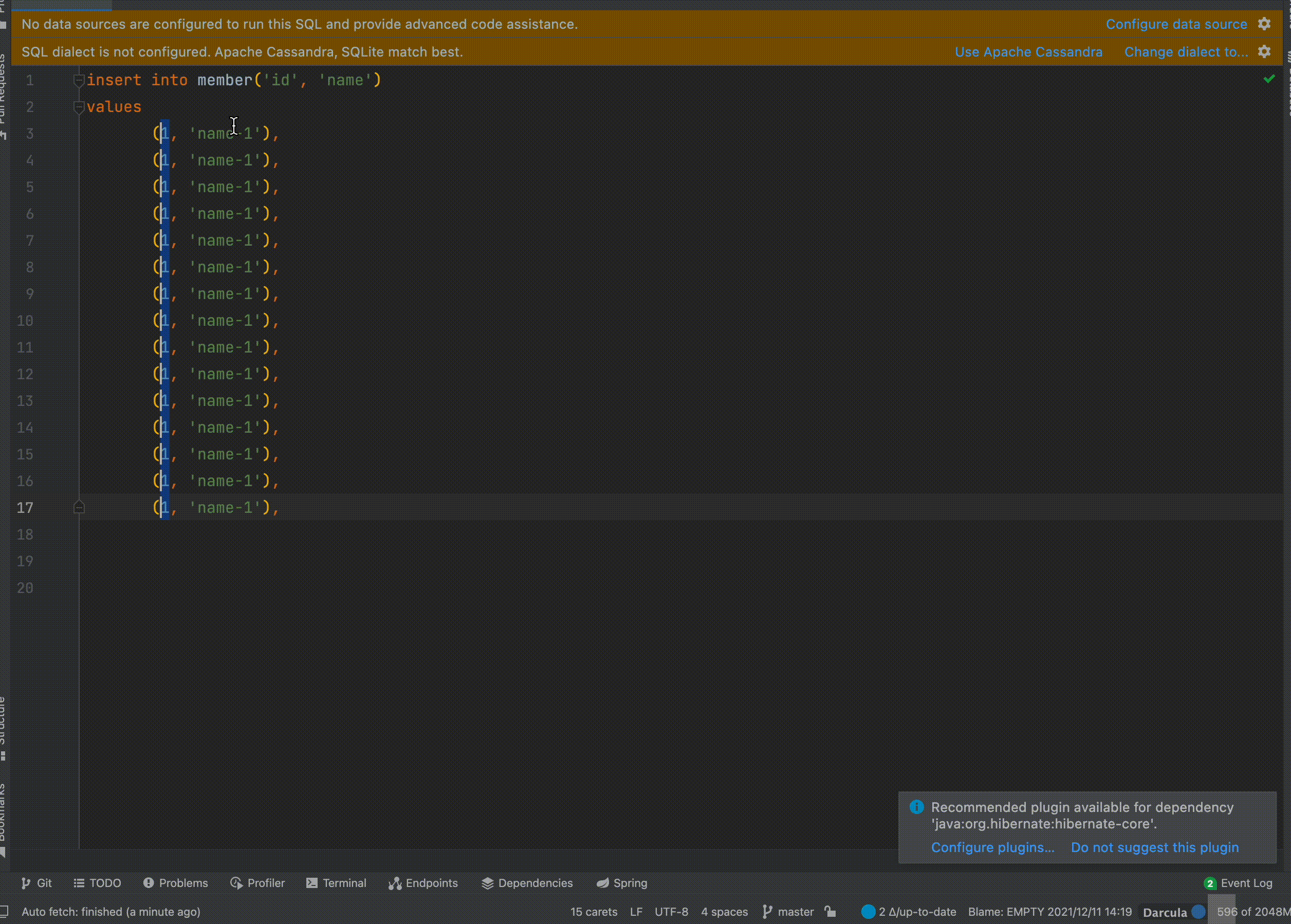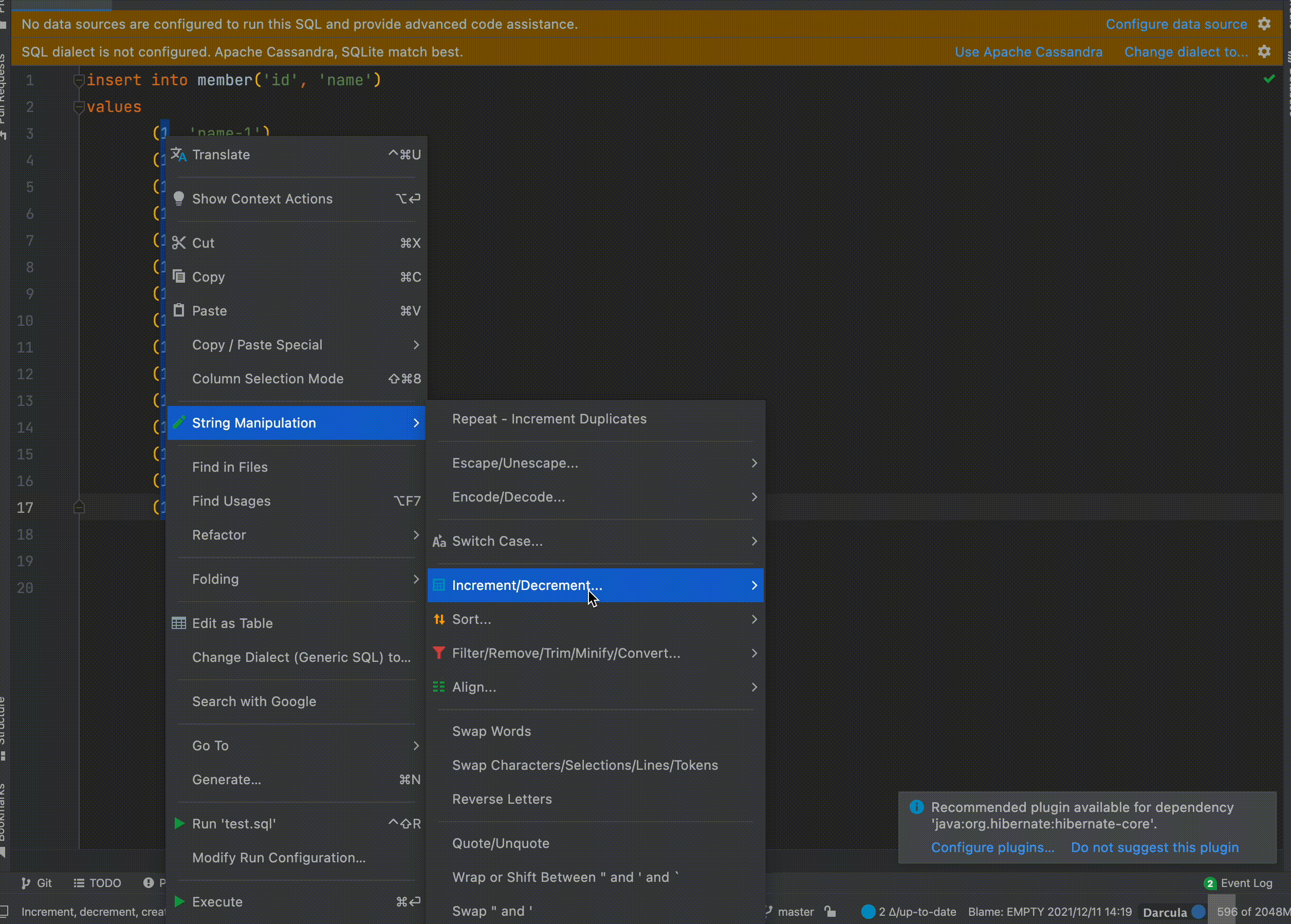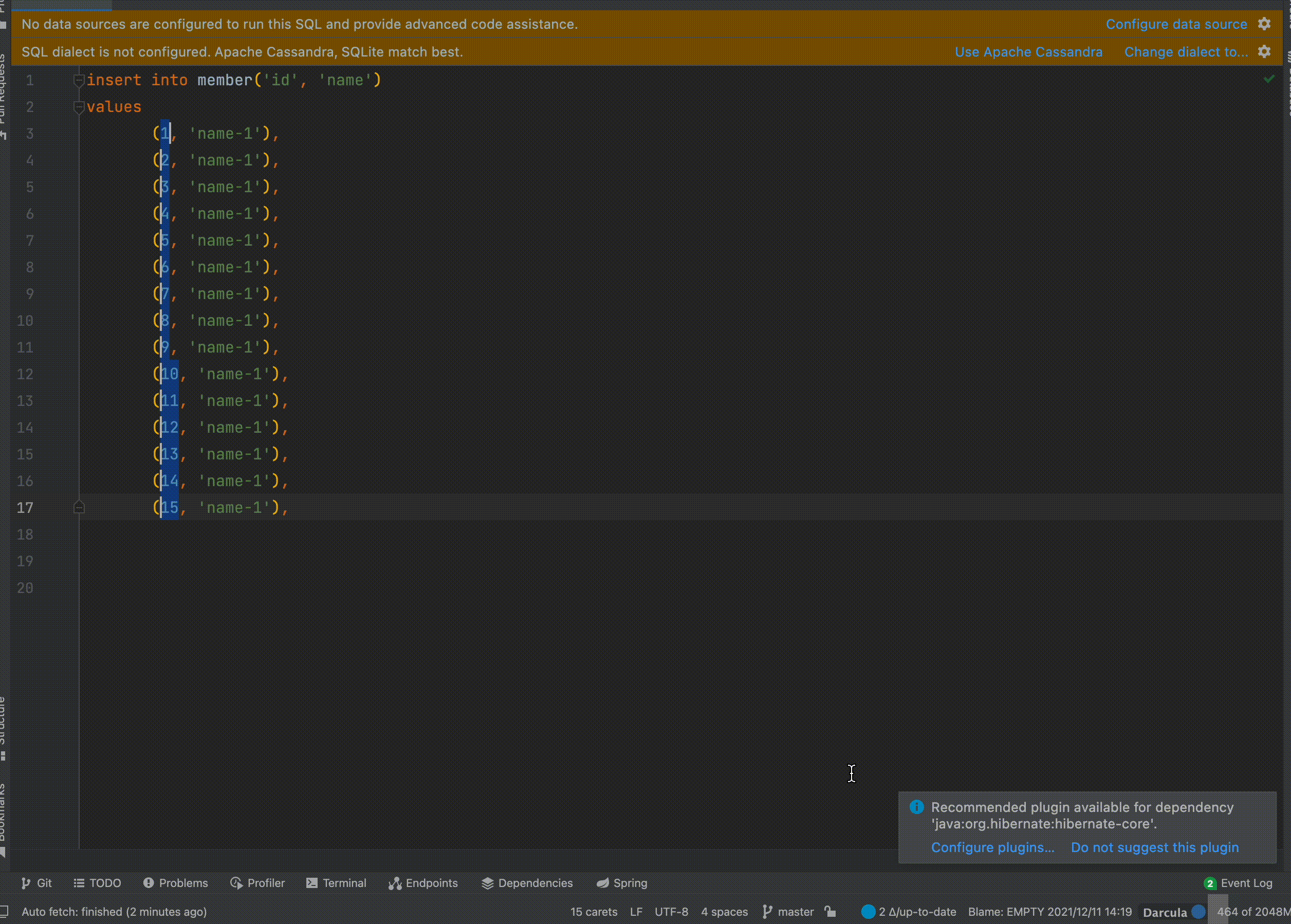
Increment 기능
특정 값에 대해서 자동으로 증가시켜 중복되지 않는 값으로 설정할 수 있습니다.
위 이미지와 같은 FK 참조하는 값에 대한 SQL을 작성하는 경우 매우 효율 적입니다. 이전에 Sql을 통해서 테스트 코드를 쉽게 작성하자 포스팅도 참고하시면 좋을 거 같습니다.
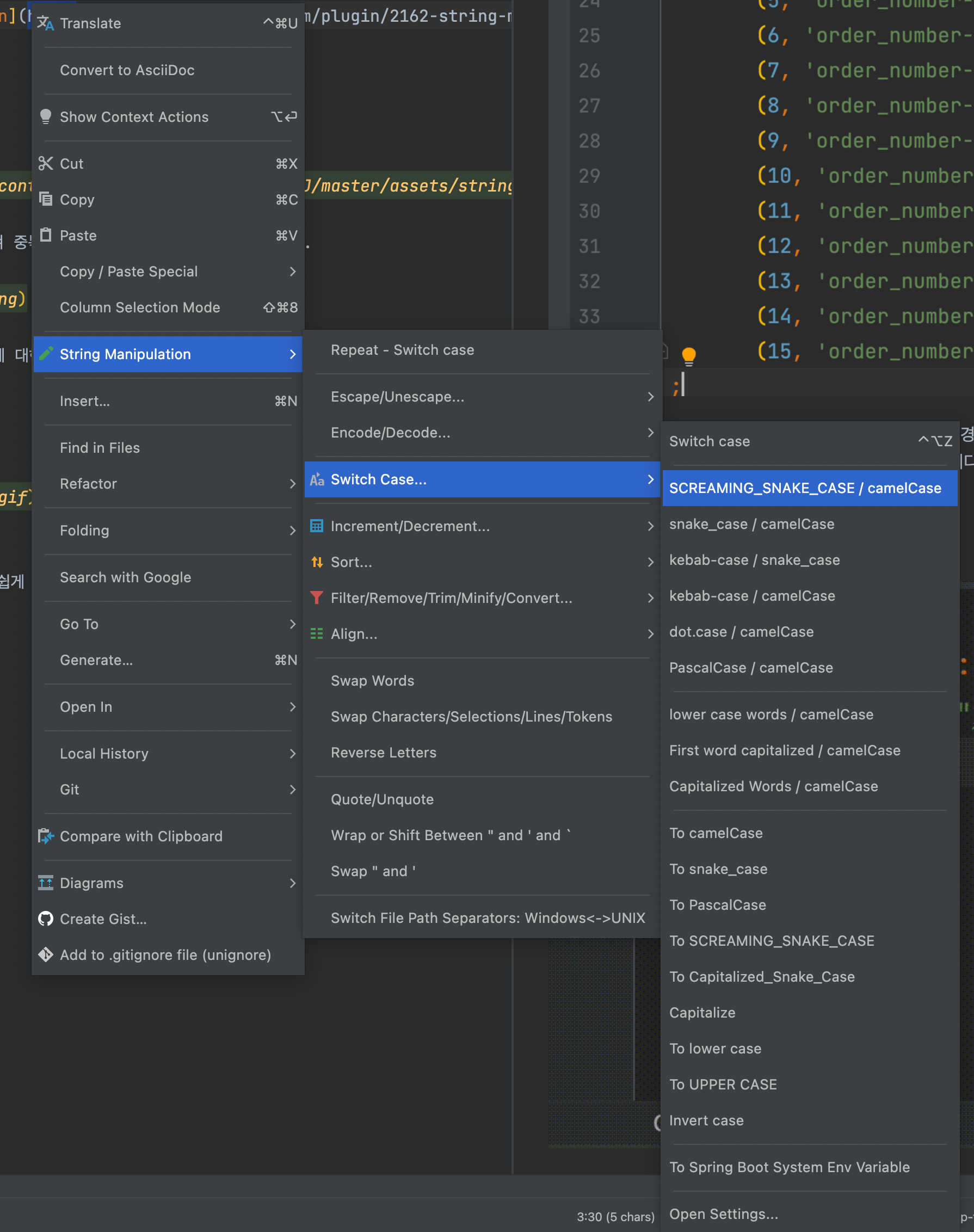
Switch
Switch는 다양한 문자열 포맷으로 쉽게 변경이 가능합니다.
Switch Case 항목을 보시면 매우 다양한 항목으로 변경이 가능합니다.
]]>
<p>DataGrip은 JetBrains에서 만든 데이터베이스 및 SQL 용 크로스 플랫폼 IDE입니다. 자세한 소개는 <a href="https://www.jetbrains.com/ko-kr/datagrip/" rel="external nofollo
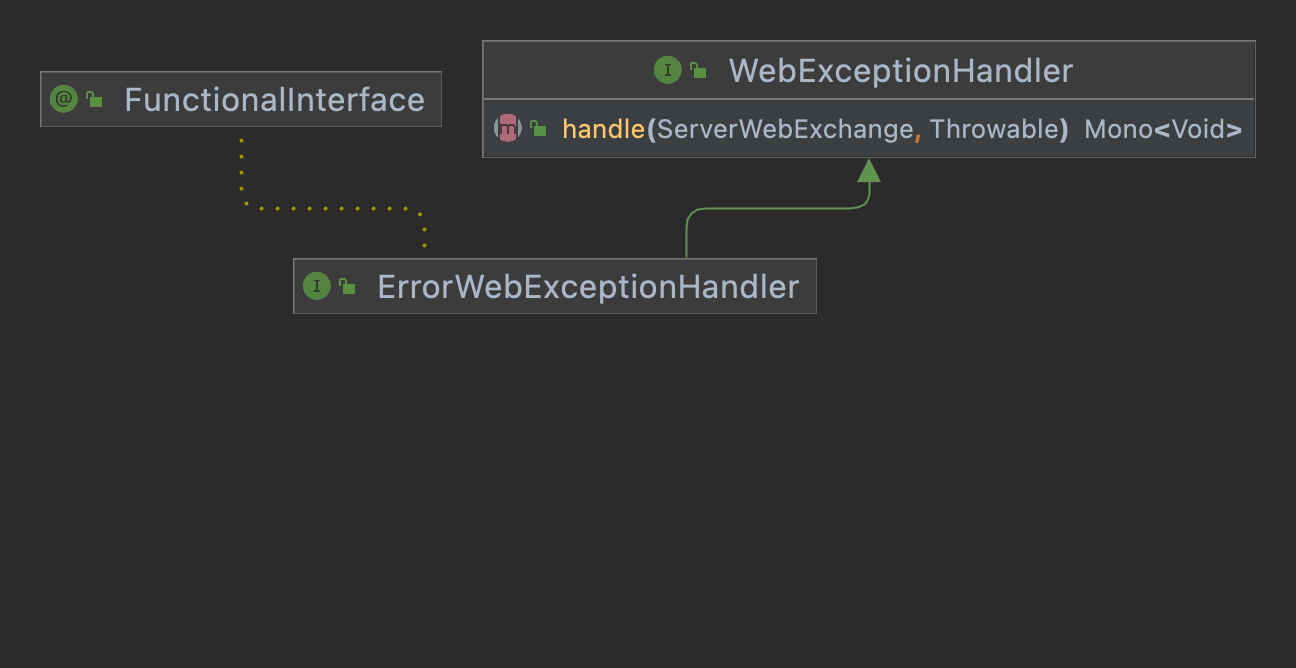
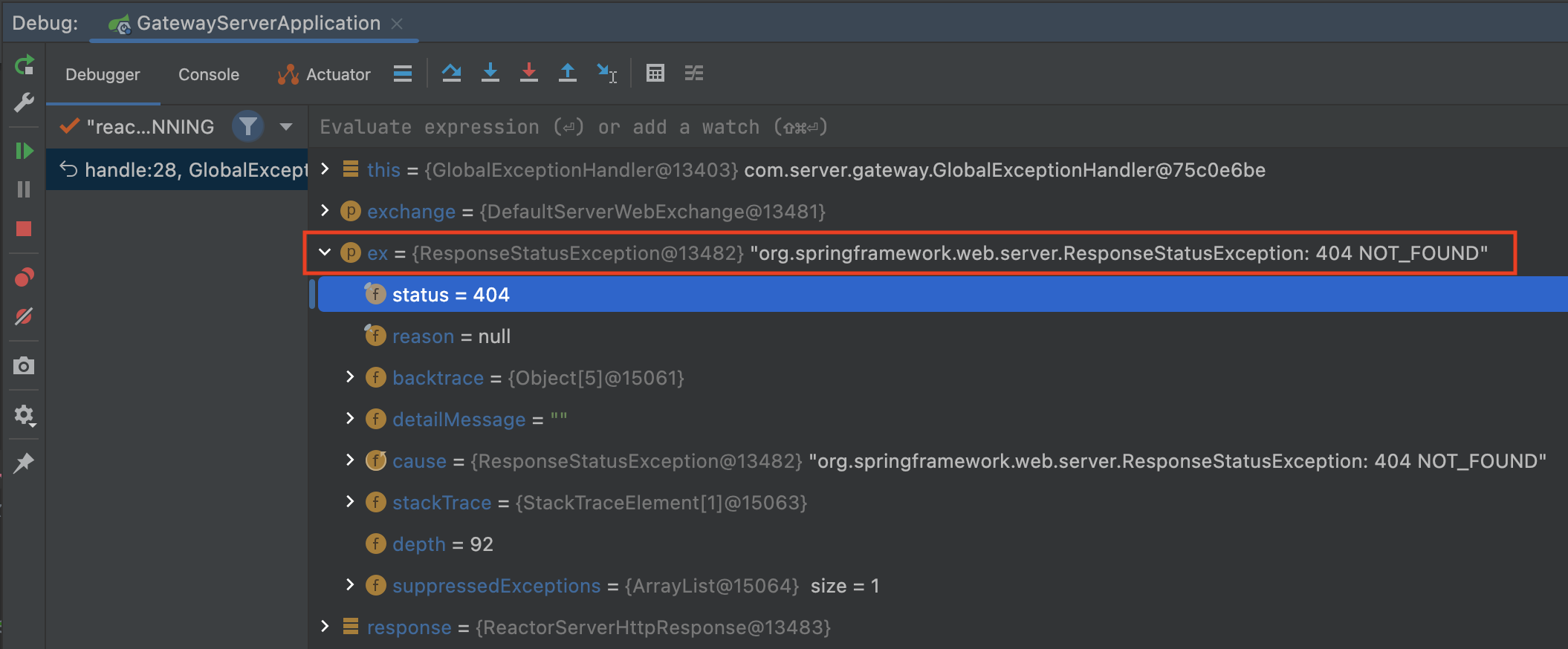
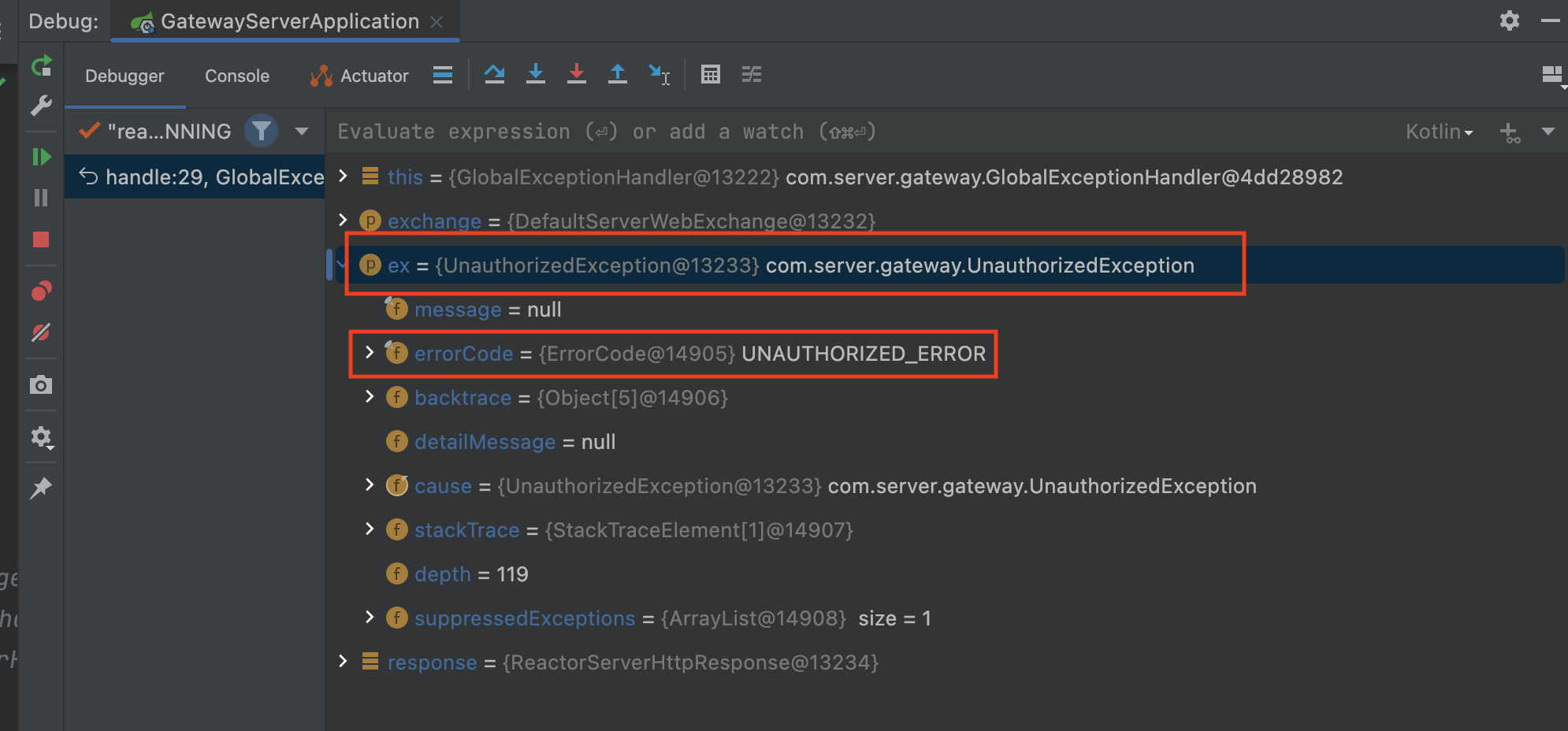
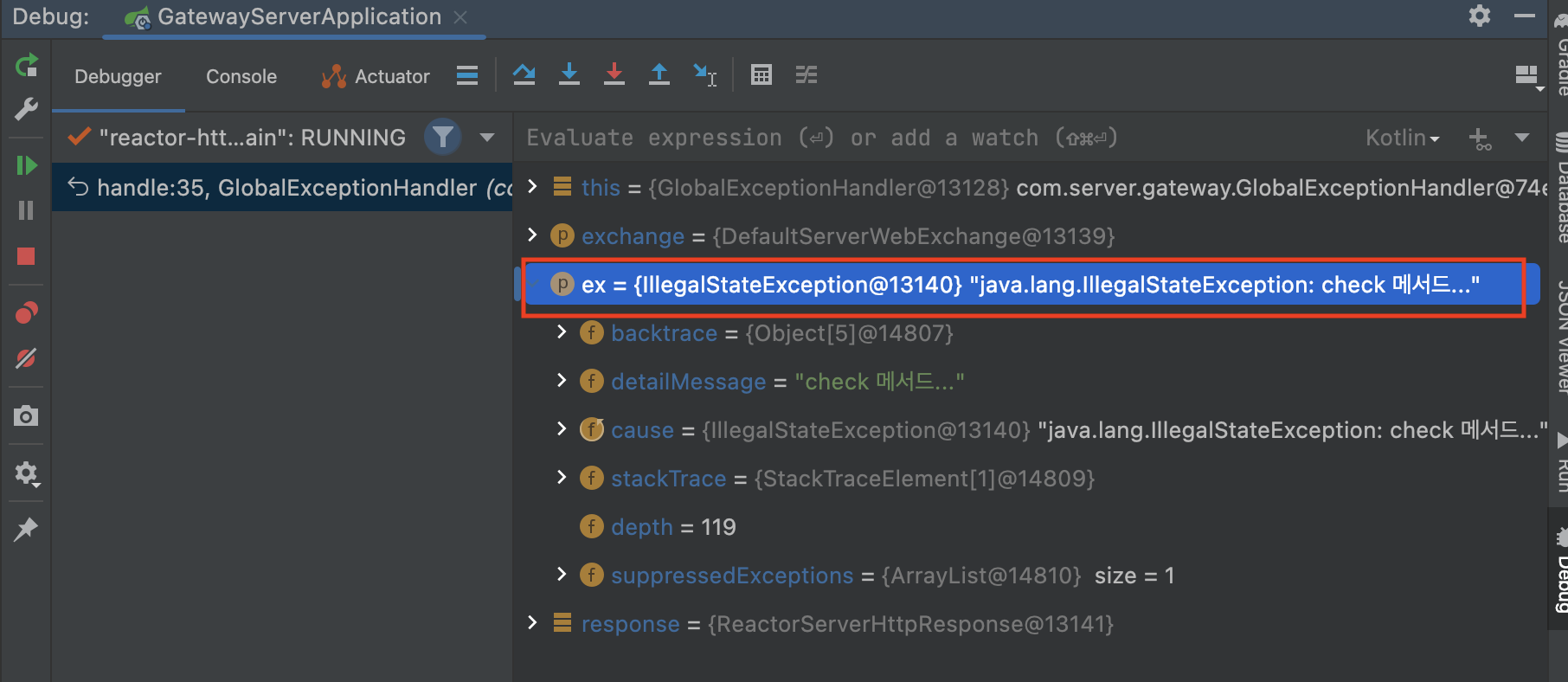
Spring Cloud Gateway Error Handling & Filterhttps://cheese10yun.github.io/spring-cloud-gateway-2/2022-06-10T15:00:00.000Z2023-07-12T01:09:09.578ZSpring Cloud Gateway를 활용하여 여러 API를 서비싱 하는 경우 해당 API들은 이전에 포스팅한 Spring Guide - Exception 전략으로 통일된 Error Response를 갖게 할 수 있습니다. 하지만 게이트웨이 내부에서 발생한 예외에 대한 Error Response를 핸들링하지 않게 되는 경우는 통일된 메시지를 갖지 못하게 됩니다. 예를 들어 해당 리소스를 찾을 수 없는 예외의 경우 아래와 같이 응답됩니다.
classFieldError( val field: String, val value: String, val reason: String )
enumclassErrorCode( val status: Int, val code: String, val message: String ) { FRAME_WORK_INTERNAL_ERROR(500, "C001", "프레임워크 내부 예외"), UNDEFINED_ERROR(500, "C002", "정의하지 않은 예외"), }
Error Respones 객체를 서비스 API와 동일하게 만듭니다. 대부분의 객체는 Error Code 기반 생성자 기반 생성자로 만들게 생성되며 BusinessException는 게이트웨이 내부의 서비스 로직에 최상위 Exception으로 해당 객체를 기반으로 내부 예외가 핸들링됩니다. 만약 게이트웨이에 로직이 거의 없고 라우팅만 사용하는 경우에는 정의하지 않아도 무방합니다.
Code C001은 스프링 게이트웨이 내부에서 발생하는 내부 예외, C002는 정의하지 않은 예외들에 대한 코드입니다. 해당 코드들도 서비스 특성에 맞게 설정하면 됩니다.
예외 핸들링
Spring Cloud Gateway에서는 @ControllerAdvice와 같은 것을 지원해주지 않아 ErrorWebExceptionHandler를 구현하는 것으로 직접 만들어야 합니다.
@Component @Order(-1)// 내부 bean 보다 우선 순위를 높여 해당 빈이 동작하게 설정 classGlobalExceptionHandler( privateval objectMapper: ObjectMapper ) : ErrorWebExceptionHandler {
val errorResponse = when (ex) { // Spring Web Server 관련 오류의 경우 Spring 오류 메시지를 사용 is ResponseStatusException -> ErrorResponse(code = ErrorCode.FRAME_WORK_INTERNAL_ERROR) is BusinessException -> { response.statusCode = HttpStatus.valueOf(ex.errorCode.status) ErrorResponse(code = ex.errorCode) } // 그외 오류는 ErrorCode.UNDEFINED_ERROR 기반으로 메시지를 사용 else -> { response.statusCode = HttpStatus.valueOf(ErrorCode.UNDEFINED_ERROR.status) ErrorResponse(code = ErrorCode.UNDEFINED_ERROR) } }
해당 객체는 예외가 발생하면 발생한 Exception 인스턴스에 맞게 Jackson 기반으로 Error Response를 생성하여 최종 응답 메시지를 만들어 내려주게 됩니다.
ResponseStatusException 핸들링
ResponseStatusException는 게이트웨이 내부 예외 중 HTTP와 관련된 예외 객체로 예를 들어 게이트웨이에서 라우팅에 등록하지 않거나 없는 주소로 접근하는 경우, 등록되지 않은 HTTP method로 요청하는 경우 등 HTTP와 관련된 예외의 경우 사용되는 예외 객체입니다.
브레이크 포인트를 걸고 없는 페이지를 호출하면 ex 객체에 ResponseStatusException는 객체가 있는 것을 확인할 수 있습니다. 해당 객체로 위에서 정의한 ErrorResponse를 생성하여 아래와 같은 형식으로 응답합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13
http://localhost:5555/ASDASD
HTTP/1.1 200 OK transfer-encoding: chunked Content-Type: application/json
message는 ResponseStatusException에서 넘겨주는 message를 그대로 사용하고 있습니다. 만약 유저에게 공개되어 있는 API인 경우에는 이런 시스템 내부에서 넘겨주는 메시지를 그대로 사용하는 것보다 내부적으로 정제된 ErrorCode의 message를 사용하여 정제된 메시지가 내려가게 하는 것도 좋은 방법입니다. 프로젝트 특성에 맞게 선택하면 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12
http://localhost:5555/actuator
HTTP/1.1 200 OK transfer-encoding: chunked Content-Type: application/json
BusinessException는 비즈니스 예외가 발생하는 경우를 핸들링을 진행하기 위한 객체입니다. 예를 들어 게이트웨이에서 인증 관련된 내부로 직을 진행하다 오류가 발생했을 경우 핸들링하기 위한 객체입니다. 우선 모든 요청에 대한 필터를 추가하는 로직을 간단하게 작성해 보겠습니다.
overridefunapply(config: Config): GatewayFilter { return GatewayFilter { exchange, chain -> // 인증 관련 로직이 있다고 가정 하고, 인증이 실패하는 경우 라고 가정 if (true){ // UNAUTHORIZED_ERROR(401, "C003", "인증에 실패했습니다"), ErrorCode 추가 throw UnauthorizedException(ErrorCode.UNAUTHORIZED_ERROR) }
chain.filter(exchange) } } }
인증 관련된 UnauthorizedException 예외 클래스를 생성합니다. BusinessException 해당 객체를 그대로 사용해도 무방합니다. 해당 예외가 발생했을 경우 정의된 UNAUTHORIZED_ERROR 객체를 넘겨주기만 하면 적절한 ErrorResponse가 내려가게 됩니다.
해당 해당 예외가 발생하면 GlobalExceptionHandler 객체에서 BusinessException 객체로 예외 객체가 할당되어 핸들링됩니다.
BusinessException을 상속한 UnauthorizedException 객체와 해당 객체에 UNAUTHORIZED_ERROR ErrorCode 값이 할당되어 있는 것을 확인할 수 있습니다. 해당 정보 기반으로 최종적으로 Error Response는 다음과 같이 내려지게 됩니다.
val errorResponse = when (ex) { // Spring Web Server 관련 오류의 경우 Spring 오류 메시지를 사용 is ResponseStatusException -> ErrorResponse(code = ErrorCode.FRAME_WORK_INTERNAL_ERROR) is BusinessException -> { response.statusCode = HttpStatus.valueOf(ex.errorCode.status) ErrorResponse(code = ex.errorCode) } // 그외 오류는 ErrorCode.UNDEFINED_ERROR 기반으로 메시지를 사용 else -> { response.statusCode = HttpStatus.valueOf(ErrorCode.UNDEFINED_ERROR.status) ErrorResponse(code = ErrorCode.UNDEFINED_ERROR) } }
해당 코드에서 else에 해당하며 정의하지 않은 예외에 대한 부분에 대한 핸들링입니다. 예를 들어 Spring Cloud Gateway 등 내부 예외, 새롭게 추가한 의존성의 내부 예외, 우리가 직접 작성한 예외지만 BusinessException를 기반으로 하지 않은 예외 코드 등이 있습니다.
위 코드처럼 코틀린 자체적으로 지원해 주는 check메서드를 사용하는 경우 IllegalStateException을 예외를 발생시킵니다. 이런 경우 BusinessException에 의해서 핸들링되지 않기 때문에 else 항목으로 잡히게 되며 ErrorCode.UNDEFINED_ERROR에 의해 ErrorResponse가 내려가게 됩니다.
필요하다면 IllegalStateException 객체를 분기문에 추가하여 핸들링 할 수도 있습니다. 하지만 모든 예외에 대한 핸들링을 할 수 없기 때문에 우리가 정의하지 않은 예외에 대해서는 메시지를 통일화하는 작업은 필요합니다.
check메서드로 발생시킨 IllegalStateException 객체와 해당 메시지가 보이는 것을 확인할 수 있습니다. 해당 객체로 최종적으로 아래와 같은 메시지로 응답을 내려줍니다.
1 2 3 4 5 6 7 8 9 10 11 12
http://localhost:5555/a-service/actuator
HTTP/1.1 500 Internal Server Error transfer-encoding: chunked Content-Type: application/json
게이트웨이로 여러 내부 API에 대한 서비싱을 제공하고 있다면 내부 서비스들의 Error Response의 통일과 게이트웨이 자체도 서비스 내부의 Error Response와 통일하는 것이 본 내용의 핵심입니다. 그 틀안에서 예외 핸들링 전략은 각 서비스 특성과 처한 환경에 맞게 진행하면 된다고 생각합니다. 위에서 설명한 방법도 게이트웨이에 서비스 관련된 로직이 많지 않다고 가정하고 설명한 전략입니다. 라우팅 관련된 설정으로만 구성된 게이트웨이인 경우 예외 클래스를 따로 정의하고 예외 코드를 정의하지 않고 간단하게 구성하는 것이 더 효율적이라고 판단하며 인증 관련된 코드 및 기타 코드들이 많아 예외를 더 체계적으로 관리하게 된다면 위 전략 보다 더 디테일한 전략이 필요할 거 같습니다.
]]>
<p>Spring Cloud Gateway를 활용하여 여러 API를 서비싱 하는 경우 해당 API들은 이전에 포스팅한 <a href="https://cheese10yun.github.io/spring-guide-exception/">Spring Gui
Kotlin 기반 경량 ORM Exposed 추가 정리 part 1https://cheese10yun.github.io/exposed-2/2022-05-29T15:00:00.000Z2023-07-02T12:45:50.513ZExposed 포스팅
//when val id = insert[Writers.id] // SQL Qury UPDATE writer SET email='new@asd.com', updated_at='2022-05-29T20:08:48.411516' WHERE writer.id = 27 Writers.update({ Writers.id eq id }) { it[this.email] = "new@asd.com" it[this.updatedAt] = LocalDateTime.now() // 해당 코드가 없는 경우 아래 then 실패 } //then val findWriter = Writers.select(Writers.id eq id).first() then(insert[Writers.updatedAt]).isNotEqualTo(findWriter[Writers.updatedAt]) } } }
clientDefault는 생성 시에만 동작하고 업데이트에서는 동작하지 않습니다. 위 업데이트에서 it[this.updatedAt]를 지정하지 않는 경우에는 테스트가 실패하게 됩니다. 즉 칼럼 업데이트는 수기로 진행해야 합니다. 다음은 DAO 방식입니다. JPA로 비교했을 때는 엔티티 방식에 해당합니다.