코루틴을 이용한 성능 개선 - Flow를 활용한 다중 요청 처리
Kotlin의 코루틴을 이용한 비동기 프로그래밍은 성능을 크게 향상시킬 수 있는 강력한 도구입니다. 특히 Flow를 활용하여 여러 요청을 동시에 처리하는 방식은 효율적인 비동기 처리를 가능하게 합니다. 이 포스팅에서는는 Flow를 사용하여 다중 요청을 처리하는 방법과 이론적 배경, 그리고 이를 사용할 때 주의할 점에 대해 다루겠습니다.
시나리오#

300ms가 발생하는 API 요청을 100번 반복하는 시나리오를 가정해봅시다. 동기적으로 처리하면 100번의 요청을 처리하는 데 30초가 걸립니다.
1 | class OrderClient { |
위 코드에서 OrderClient의 getOrder 함수는 각 호출마다 300ms가 소요된다고 가정합니다. 일반적인 API 호출의 경우 300ms 응답속도는 빠른 편에 속합니다. 하지만 100번을 호출 한다고 가정하면 총 소요 시간은 100 * 300ms = 30,000ms, 즉 30초가 됩니다.
1 |
|
코루틴 Flow를 이용한 성능 개선#
Kotlin의 코루틴은 비동기 작업을 손쉽게 처리할 수 있는 강력한 도구입니다. 특히 Flow를 활용하면 여러 비동기 요청을 효율적으로 처리할 수 있습니다. Flow는 데이터 스트림을 처리하는 코루틴 기반 API로, 여러 개의 작업을 동시에 병렬로 수행할 수 있도록 지원합니다. 이번 섹션에서는 Flow의 flatMapMerge를 사용하여 다수의 API 요청을 효율적으로 처리하는 방법과, 이를 통해 얻을 수 있는 성능 향상에 대해 다뤄보겠습니다.
1 |
|
위 코드에서 getOrderFlow 함수는 orderRequests 리스트를 플로우로 변환하고, flatMapMerge를 사용하여 각 요청을 병렬로 처리합니다. 각 요청은 코루틴 내에서 300ms 동안 지연된 후 결과를 반환합니다. 이 방식으로 100개의 요청을 동시에 처리하면, 전체 처리 시간은 가장 오래 걸리는 요청 하나의 시간인 300ms로 줄어듭니다.
성능 테스트#
1 |
|
이론상 100개의 요청을 동시에 처리하면 300ms 정도의 시간이 소요되어야 하지만, 실제로는 2,228ms가 소요됩니다. 이는 다음과 같은 요인들로 인한 것입니다.
- 코루틴 생성과 컨텍스트 전환 오버헤드
- 코루틴을 생성하고 실행할 때 발생하는 오버헤드는 무시할 수 없는 시간 지연을 초래할 수 있습니다.
- 특히,
flatMapMerge를 사용하여 다수의 코루틴을 병렬로 실행할 때, 각 코루틴의 생성과 컨텍스트 전환 비용이 누적되어 총 실행 시간이 증가할 수 있습니다.
flatMapMerge의 병합 과정flatMapMerge는 여러 플로우를 병합하면서 각 플로우의 결과를 수집합니다.- 이 과정에서 발생하는 추가적인 작업들, 예를 들어 플로우의 결과를 수집하고 병합하는 오버헤드가 존재할 수 있습니다.
- 이 오버헤드는 특히 플로우의 개수가 많을 때 더 크게 작용합니다.
emit호출과 플로우 수집의 지연- 각 플로우에서
emit을 호출하고, 최종적으로toList로 수집하는 과정에서 발생하는 지연도 무시할 수 없습니다. emit은 비동기적으로 데이터를 내보내는 작업이므로, 여러 번 호출될 때 지연이 누적될 수 있습니다.
- 각 플로우에서
- 기본 Concurrency 설정
- flatMapMerge의 기본 concurrency 값은 16이며, 이 코드는 기본값으로 동작합니다.
- Concurrency 16으로 동작할 때 100개의 요청을 처리하는 데 소요되는 시간은 100 / 16 * 300 = 1875ms 정도입니다.
- 이 시간은 앞서 언급한 1, 2, 3번 항목들과 함께 작업을 수행해야 하므로 추가적인 지연이 발생할 수 있습니다.
- 특히, Concurrency 16으로 처리하는 시간이 가장 오래 걸리며, 이는 전체 처리 시간에 크게 영향을 미칩니다.
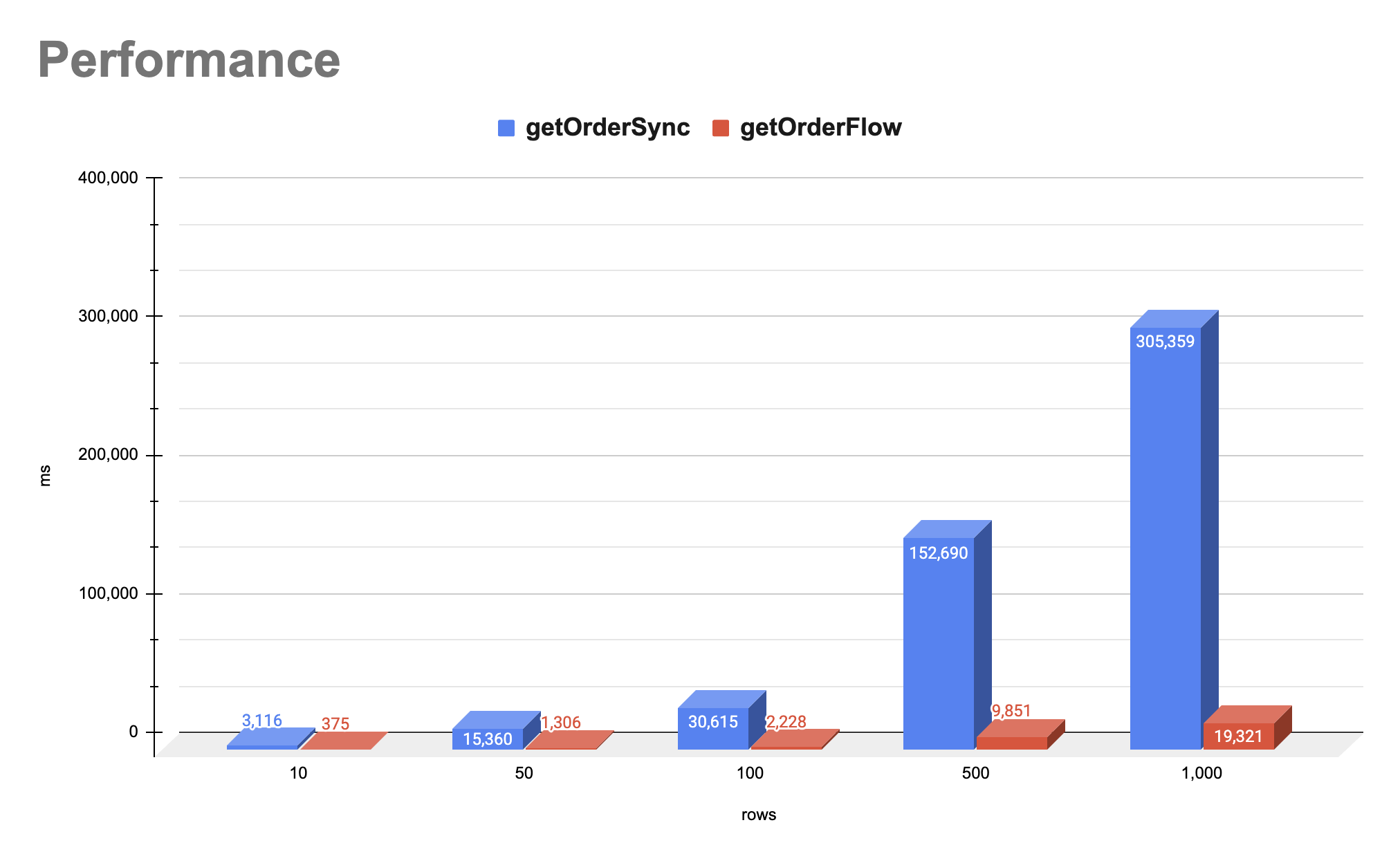
| Rows | getOrderSync (ms) | getOrderFlow (ms) | Improvement (%) |
|---|---|---|---|
| 10 | 3,116 | 375 | 87.97 |
| 50 | 15,360 | 1,306 | 91.50 |
| 100 | 30,615 | 2,228 | 92.72 |
| 500 | 152,690 | 9,851 | 93.55 |
| 1,000 | 305,359 | 19,321 | 93.67 |
위 표는 동기 방식(getOrderSync)과 비동기 방식(getOrderFlow)의 성능을 비교한 결과입니다. getOrderFlow를 사용한 비동기 방식은 모든 요청을 동시에 처리함으로써 동기 방식에 비해 큰 성능 개선을 보여주고 있습니다. 특히, 요청 수가 많을수록 비동기 방식의 성능 향상 효과가 더욱 두드러집니다. 이는 동기 방식이 요청 수에 비례하여 선형적으로 시간이 증가하는 반면, 비동기 방식은 병렬 처리를 통해 시간 증가를 억제할 수 있기 때문입니다.
스레드와 코루틴: 경량 스레드의 강점#
Kotlin 문서에서는 코루틴을 경량 스레드라고 합니다. 이는 대부분의 스레드와 마찬가지로 코루틴이 프로세스가 실행할 명령어 집합의 실행을 정의하기 때문입니다. 또한 코루틴은 스레드와 비슷한 라이프 사이클을 갖고 있습니다.
코루틴은 스레드 안에서 실행됩니다. 하나의 스레드에는 여러 개의 코루틴이 있을 수 있지만, 주어진 시간에 하나의 스레드에서는 하나의 명령만 실행될 수 있습니다. 즉, 같은 스레드에 10개의 코루틴이 있다면 해당 시점에는 하나의 코루틴만 실행됩니다.
스레드와 코루틴의 가장 큰 차이점은 코루틴이 빠르고 적은 비용으로 생성될 수 있다는 점입니다. 수천 개의 코루틴도 쉽게 생성할 수 있으며, 수천 개의 스레드를 생성하는 것보다 빠르고 자원도 훨씬 적게 사용합니다.
코루틴 생성 테스트#
다음 코드는 코루틴을 생성하는 데 필요한 스레드 수를 테스트하는 예제입니다. 이 테스트를 통해 코루틴이 얼마나 적은 리소스로 동작하는지 확인할 수 있습니다.
1 | // 코드 출처 코틀린 동시성 프로그래밍 |
다음은 테스트 결과입니다. 다양한 수의 코루틴을 생성했을 때 사용되는 스레드 수를 보여줍니다.
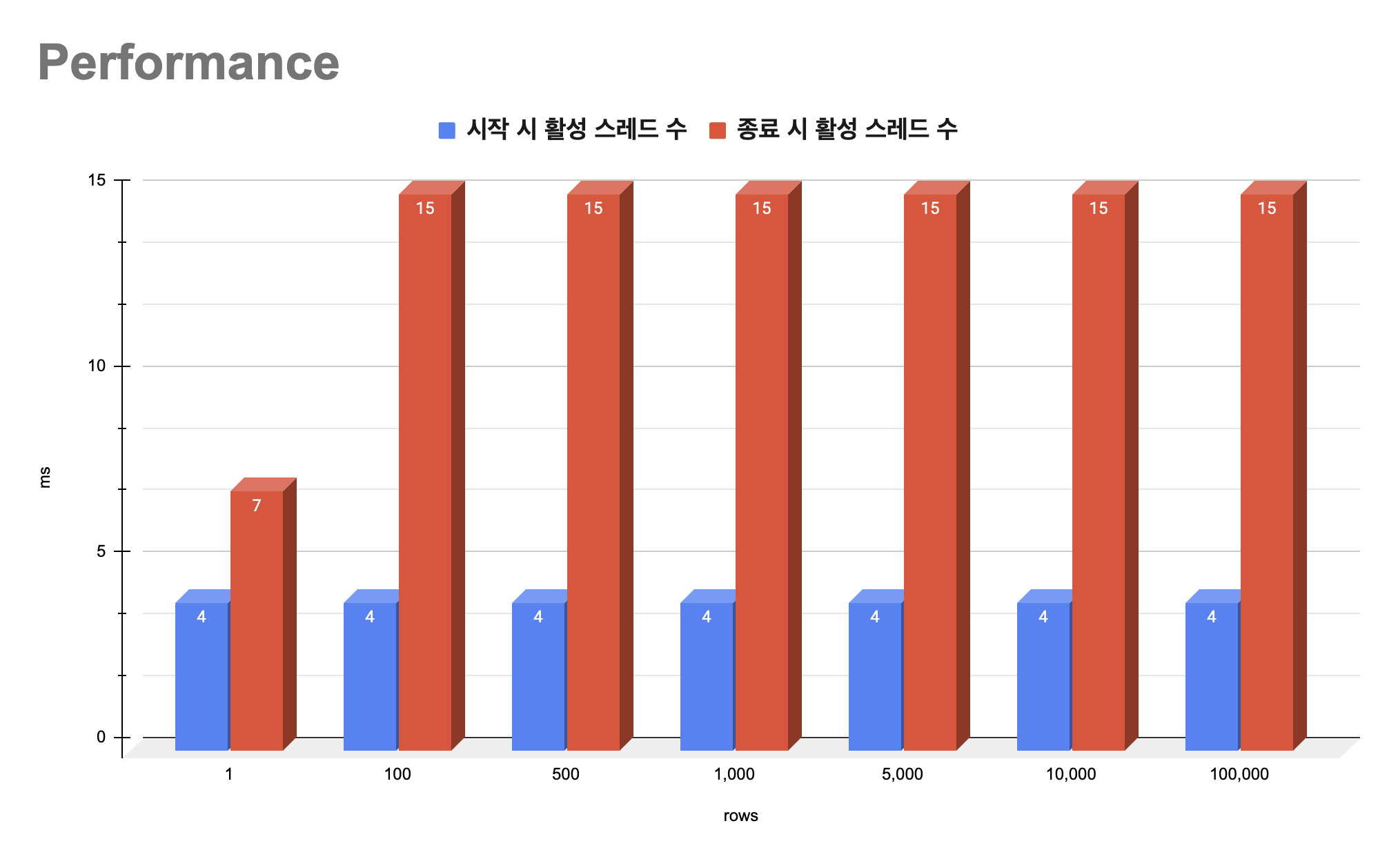
| amount | 시작 시 활성 스레드 수 | 종료 시 활성 스레드 수 |
|---|---|---|
| 1 | 4 | 7 |
| 100 | 4 | 15 |
| 500 | 4 | 15 |
| 1,000 | 4 | 15 |
| 5,000 | 4 | 15 |
| 10,000 | 4 | 15 |
| 100,000 | 4 | 15 |
위 결과에서 알 수 있듯이, 코루틴을 많이 생성해도 사용되는 스레드 수는 크게 증가하지 않습니다. 시작 시에는 4개의 스레드가 활성화되어 있었고, 종료 시에도 최대 15개의 스레드만 활성화되었습니다. 이는 코루틴이 얼마나 적은 리소스를 사용하여 병렬 작업을 수행할 수 있는지를 잘 보여줍니다. 위 Flow 처리에서도 요청 수가 10에서 1,000일 때 4개의 스레드만 필요합니다.
코루틴은 스레드와 비교했을 때 훨씬 가볍고, 생성 및 전환 비용이 낮습니다. 이러한 특성 덕분에 코루틴은 높은 동시성을 요구하는 애플리케이션에서 매우 유용합니다. 동기 방식에서 수천 개의 스레드를 생성하는 것은 비효율적이고 리소스 낭비가 심하지만, 코루틴을 사용하면 동일한 작업을 더 적은 리소스로 처리할 수 있습니다.
Flow Concurrency Size 조절#
Concurrency 기본 개념#
Concurrency(동시성)은 여러 작업이 동시에 진행되는 것을 의미합니다. 컴퓨팅에서 이는 여러 작업이 동시에 실행되거나, 하나의 작업이 다른 작업의 실행 중간에 개입하는 것을 의미합니다. 코루틴을 활용한 동시성은, 실제로 동시에 실행되지 않더라도, 작업이 비동기적으로 실행되는 것처럼 보이게 만듭니다. 이는 특히 IO 바운드 작업에서 효과적입니다.
Kotlin의 flatMapMerge에서 concurrency 파라미터는 동시에 병렬로 실행할 최대 코루틴 수를 설정합니다. 이 파라미터를 통해 한 번에 얼마나 많은 코루틴이 실행될 수 있는지를 제어할 수 있습니다.
Concurrency Size 성능 테스트#
1 |
|
flatMapMerge의 concurrency 파라미터는 동시에 실행되는 코루틴 수를 테스트 코드에서 지정할 수 있도록 코드를 수정합니다. 지정하지 않으면 기본값은 DEFAULT_CONCURRENCY로 설정됩니다. 위 예제에서는 16으로 지정된 상태입니다. 다음은 1,000개의 요청을 처리할 때 다양한 concurrency 값에 따른 성능 테스트 결과입니다
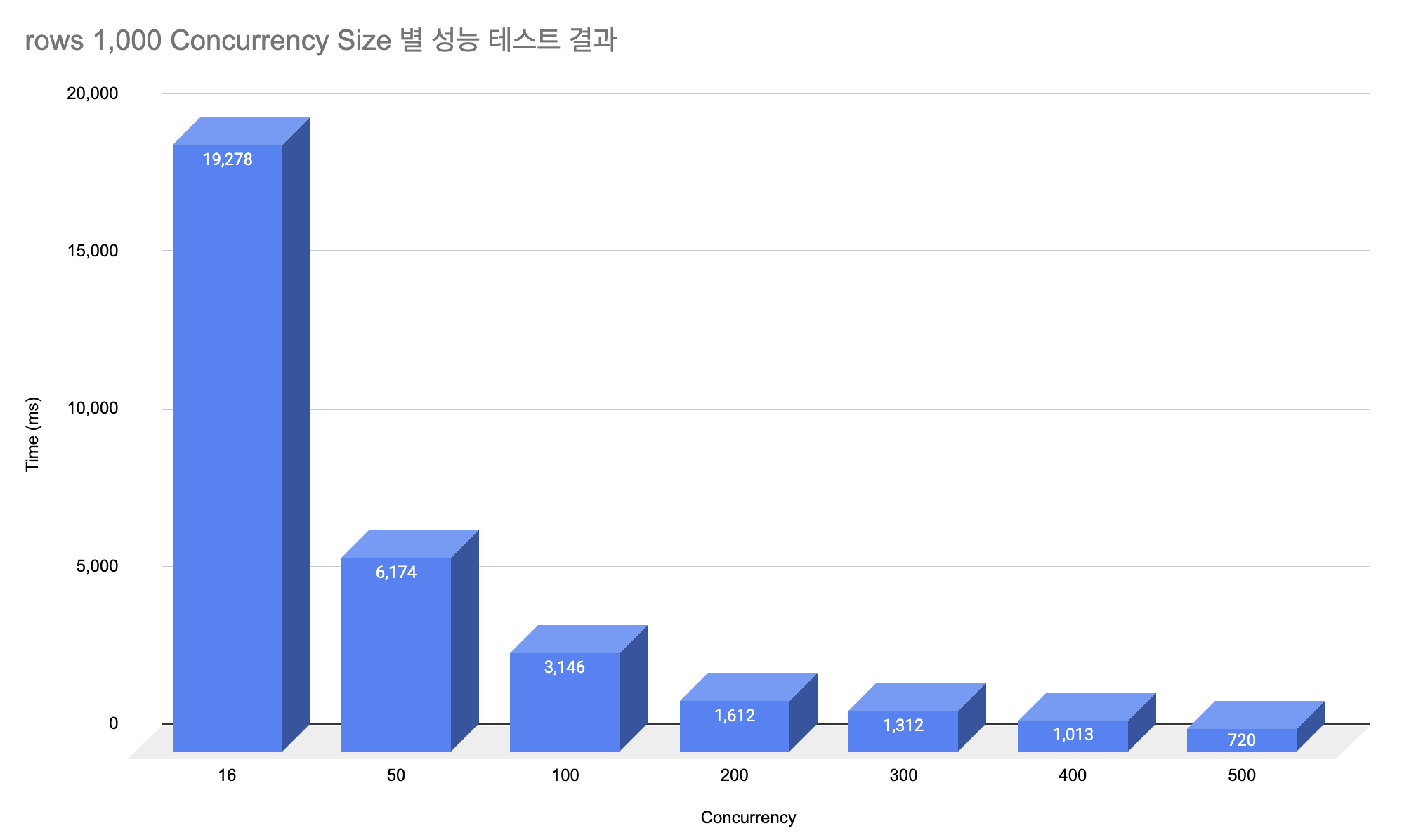
| Concurrency | Time (ms) |
|---|---|
| 16 | 19,278 |
| 50 | 6,174 |
| 100 | 3,146 |
| 200 | 1,612 |
| 300 | 1,312 |
| 400 | 1,013 |
| 500 | 720 |
위 결과에서 알 수 있듯이, concurrency 값을 늘릴수록 전체 처리 시간이 줄어듭니다. 특히, concurrency 값을 16에서 500까지 늘렸을 때, 전체 처리 시간이 19,278ms에서 720ms로 크게 감소한 것을 확인할 수 있습니다. 이는 concurrency 값을 적절히 설정하면 성능을 크게 향상시킬 수 있다는 것을 보여줍니다.
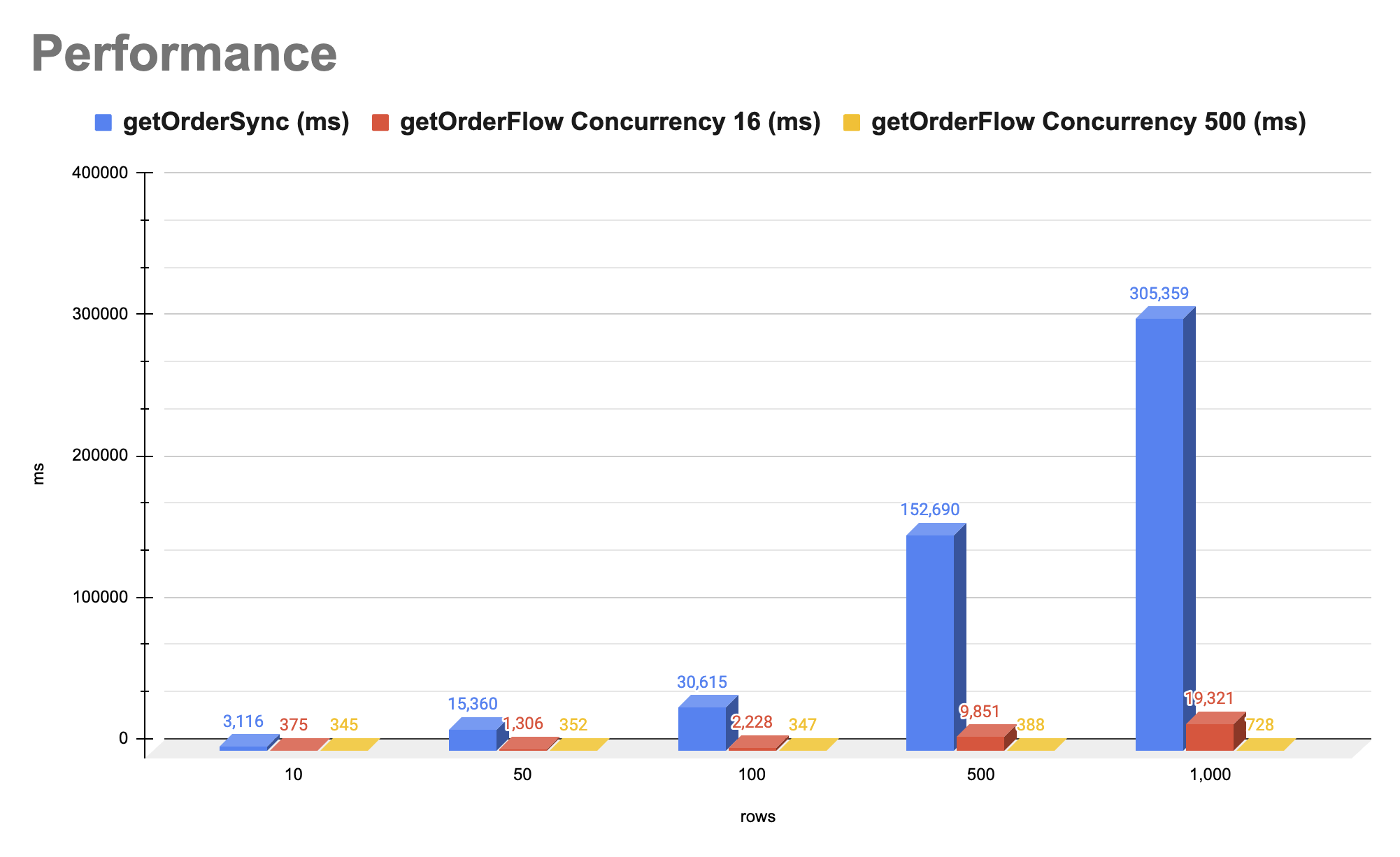
| Rows | getOrderSync (ms) | getOrderFlow Concurrency 16 (ms) | getOrderFlow Concurrency 500 (ms) |
|---|---|---|---|
| 10 | 3,116 | 375 | 345 |
| 50 | 15,360 | 1,306 | 352 |
| 100 | 30,615 | 2,228 | 347 |
| 500 | 152,690 | 9,851 | 388 |
| 1,000 | 305,359 | 19,321 | 728 |
1,000개의 요청을 처리하는 데 있어, 동기식 방식은 305,359ms가 소요되었으며, Flow Concurrency 16을 사용하면 처리 시간이 19,321ms로 줄어들어 약 93.67%의 성능 향상을 보였습니다. Concurrency를 500으로 설정하면 처리 시간이 728ms로 더욱 향상됩니다. Concurrency 값을 적절히 설정하면 성능을 크게 향상시킬 수 있음을 확인할 수 있습니다. 또 코루틴은 적은 양의 스레드로도 많은 데이터를 효율적으로 처리할 수 있음을 보여줍니다. 이러한 결과는 적절한 Concurrency 설정을 통해 애플리케이션의 성능을 극대화할 수 있음을 시사합니다.
Concurrency Size 성능 최적화 시 고려 사항#
성능은 크게 향상됐지만 무턱대고 concurrency 값을 늘리는 것은 해결책이 아닙니다. concurrency 값을 너무 크게 설정하면 오히려 시스템 자원을 과도하게 사용하게 되어 성능 저하가 발생할 수 있습니다. 따라서 여러 코루틴을 사용하는 것은 자원을 더 많이 사용하게 되므로, 각자의 리소스와 환경에 맞는 concurrency 값을 적절하게 설정하는 것이 중요합니다. 시스템의 CPU, 메모리, 네트워크 대역폭 등을 고려하여 최적의 concurrency 값을 설정해야 합니다.
또한 배치 애플리케이션처럼 특정 작업만 하고 애플리케이션이 종료되는 환경에서는 concurrency 값을 높여 처리량을 극대화하는 것이 좋습니다. 이런 경우에는 단기간에 최대한 많은 작업을 처리하는 것이 목표이므로, 가능한 한 높은 concurrency 값을 설정하여 성능을 최적화할 수 있습니다.
코루틴은 더 적은 스레드로 더 많은 동시성을 처리한다#
1 | private fun rxAndBulkWriter(): ItemWriter<StoreProjection> { |
RxJava에서 flow 방식으로 처리하는 코드는 코루틴과 비교해볼 수 있습니다. RxJava와 코루틴의 flow를 이용한 병렬 처리 및 병합 과정은 기본적으로 유사한 개념을 공유합니다. 두 방식 모두 데이터를 비동기적으로 처리하고 결과를 수집하며, 병렬로 처리한 작업들을 하나의 흐름으로 다시 병합합니다. 그렇다면, 이 두 방식의 차이점은 무엇일까요?
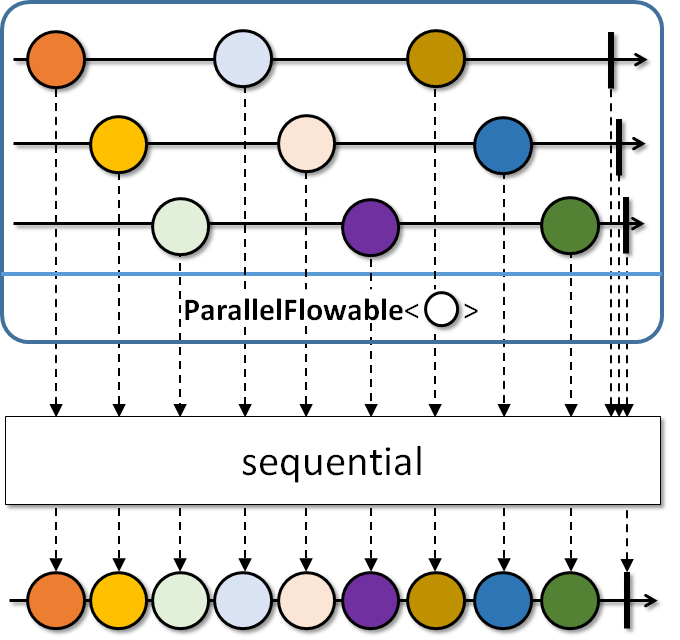
RxJava와 같은 라이브러리에서는 동시성 처리를 위해 CPU 코어 수에 맞춰 스레드를 생성하는 것이 일반적입니다. 예를 들어, CPU가 4코어라면 4개의 스레드를 생성해 병렬로 작업을 처리합니다. 이 방식은 각 스레드에 작업을 분배해 동시에 여러 작업을 처리할 수 있지만, 스레드의 생성과 컨텍스트 전환에서 발생하는 비용이 성능에 영향을 미칠 수 있습니다. 스레드 수가 많아질수록 시스템 자원을 더 많이 소비하게 됩니다.
코틀린의 코루틴은 동시성 프로그래밍에 있어서 더 효율적인 대안을 제공합니다. 코루틴은 스레드보다 훨씬 가벼우며, 하나의 스레드에서 여러 개의 코루틴을 실행할 수 있습니다. 코루틴은 스레드처럼 독립적인 작업 단위이지만, 스레드보다 적은 자원을 사용하고 빠르게 컨텍스트 전환을 할 수 있습니다.
코루틴은 I/O 작업이나 비동기 처리가 필요한 경우 특히 효과적입니다. 여러 코루틴이 동시에 실행되더라도, 이는 스레드 수와는 무관하게 적은 스레드로도 많은 작업을 처리할 수 있습니다. 즉, CPU 코어 수보다 훨씬 더 많은 동시 작업을 수행할 수 있으며, 스레드의 생성 및 컨텍스트 전환 비용도 줄어듭니다.
결론적으로, RxJava와 같은 방식은 CPU 코어 수만큼 스레드를 생성해 동시성을 처리하는 반면, 코루틴은 하나의 스레드에서 여러 작업을 동시에 처리할 수 있어, 적은 스레드로도 더 많은 동시성을 처리할 수 있다는 장점이 있습니다. 코루틴의 이러한 특성은 자원을 절약하고, 더 높은 성능을 제공할 수 있는 강력한 도구가 됩니다.