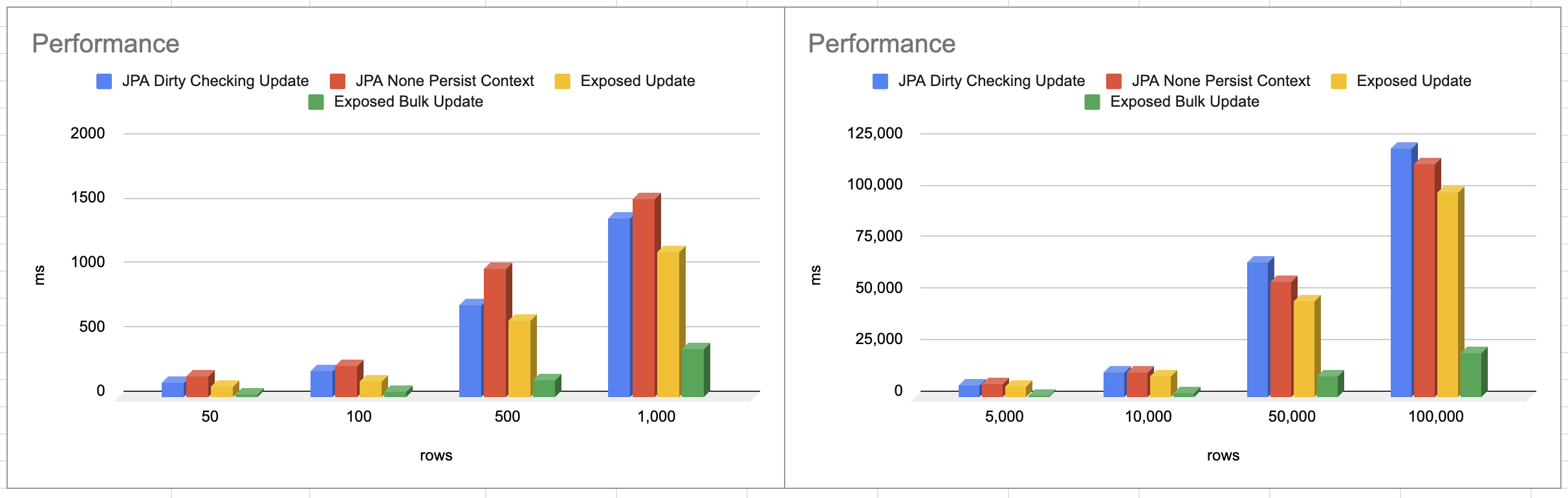
MySQL 기반으로 대량 업데이트를 진행하는 경우 JPA, Exposed 프레임워크 기반으로 테스트를 진행했습니다. 결론부터 말씀드리면 Exposed 기반 Batch Update가 가장 빨랐습니다. 물론 JPA에서도 addBatch 방식을 진행하면 유의미한 속도 차이는 없을 것 같아 보이나 Exposed가 addBatch 기능을 직관적으로 지원하고 있어 addBatch 방식은 Exposed를 사용했으며 JPA는 영속성 컨텍스트 기반인 Dirty Checking Update, 영속성 컨텍스트가 필요 없는 ID 기반 업데이트를 진행했습니다.
@Test internalfun `dirty checking update test`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val total = 500 val map = (1..total).map { Writer( name = "old", email = "old" ) } // 데이터 셋업, 속도 측정 포함 X setup(map) // 데이터 조회, 속도 특정 X val writers = writerService.findAll()
val stopWatch = StopWatch() // 업데이트 속도 측정 stopWatch.start() writerService.update(writers) stopWatch.stop()
@Test internalfun `none persistence context update test`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val total = 500 val map = (1..total).map { Writer( name = "old", email = "old" ) } // 데이터 셋업, 속도 측정 포함 X setup(map) val findAll = writerService.findAll()
// 업데이트 속도 측정 val stopWatch = StopWatch() stopWatch.start() writerService.nonPersistContestUpdate(findAll.map { it.id!! }) stopWatch.stop()
// 영속성 컨텍스트 없는 업데이트 @Transactional overridefunupdate(ids: List<Long>) { for (id in ids) { update(qWriter) .set(qWriter.name, "update") .where(qWriter.id.eq(id)) .execute() } } }
JPA에서는 Persistence Context 기반인 Dirty Checking을 통한 업데이트와, Persistence Context 없이 상태의 업데이트를 진행했습니다.
@Test fun `update`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val totalCount = 500 val ids = (1..totalCount).map { it.toLong() } // 데이터 셋업, 속도 측정 포함 X setup(ids)
// 데이터 셋업, 속도 측정 포함 X val stopWatch = StopWatch() stopWatch.start() for (writerId in ids) { Writers .update({ Writers.id eq writerId }) { it[email] = "update" } } stopWatch.stop() println("${ids.size} update, ${stopWatch.lastTaskTimeMillis}") }
@Test fun `bulk update`() { // 업데이트 대상 rows, 50, 100, 500, 1,000, 5,000, 10,000, 50,000, 100,000 val totalCount = 500 val ids = (1..totalCount).map { it.toLong() } // 데이터 셋업, 속도 측정 포함 X setup(ids)
// 업데이트 속도 측정 val stopWatch = StopWatch() stopWatch.start() BatchUpdateStatement(Writers).apply { ids.forEach { addBatch(EntityID(it, Writers)) this[Writers.email] = "update" } } .execute(TransactionManager.current())
JDBC 드라이버에서는 addBatch()를 제공하고 있습니다. 이 기능은 rewriteBatchedStatements 옵션을 활성화하면 MySQL Connector/J가 addBatch() 함수로 레코드를 모아 MySQL 서버로 전달합니다. 일반적으로 Batch Insert를 진행할 때 많이 사용하는 옵션으로 Batch Insert 성능 향상기 1편 - With JPA, Batch Insert 성능 향상기 2편 - 성능 측정에서 다룬 적 있습니다. Insert 쿼리 같은 경우는 addBatch()를 사용하면 다음과 같은 형태로 묶어서 실행시켜 줍니다.
1 2 3 4 5 6
-- addBatch() 사용시 단일 insert에서 아래 SQL 형태로 변경 insert into writer (`name`, `email`, `created_at`, `updated_at`) values ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442'), ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442'), ... ('old', 'old', '2022-11-06 13:48:14.135442', '2022-11-06 13:48:14.135442');
Update 쿼리는 형식의 변경은 없지만 레코드를 모아서 한 번에 MySQL 서버로 전달하여 네트워크 통신을 최소화할 수 있습니다.
해당 테스트 환경은 로컬 애플리케이션에서 로컬 MySQL 통신으로 진행했기 때문에 네트워크 리소스 비용이 크게 발생하지 않았음에도 Exposed 기반의 Batch Update 성능이 가장 좋았습니다. 실제 운영 환경에서는 물론 Exposed Bulk Update도 시간이 더 오래 걸리겠지만 다른 업데이트 방법들은 네트워크 리소스가 높아짐에 따라 더 많은 시간이 발생할 것으로 보입니다.
그리고 JPA에서는 Dirty Checking Update, None Persistence Context의 성능 차이는 생각보다 크게 발생하진 않았습니다. 물론 영속성 컨텍스트가 반드시 필요하니 조회에 대한 부분까지 포함 시키면 유의미한 차이가 있을 것으로 보입니다. 하지만 이런 대량 조회의 경우 영속성 컨텍스트를 통하지 않고 Projections을 사용하는 것이 일반적이라 그 부분까지 테스트하진 않았습니다. JPA 기반으로 대량 데이터를 조회하는 경우 가능하면 Projections을 사용하는 것을 권장 드립니다. 그리고 이런 대량 데이터를 처리하는 특성상 배치 애플리케이션으로 구성하고 Chunk 단위로 데이터를 처리하기 때문에 100,000 정도의 데이터를 처리하는 것은 권장하진 않습니다. 데이터 모수와 처리 시간에 대한 상관관계를 확인하기 위해 작업했습니다.
실제 운영 환경에서의 네트워크 통신 비용에 따라서 addBatch() 방식과, 그렇지 않은 단건 업데이트 방식의 처리 시간은 더 차이가 날것으로 보이며, 구조적으로 큰 변경 없이 데이터 업데이트 방식만 바꾸는 것으로 6배 가까운 향상이 있기 때문에 대용량 업데이트 처리를 하고 있다면 권장 드립니다. JPA는 정말 좋은 ORM 프레임워크가 생각이 들지만 대량 처리에 대한 도구로는 적절하지 않다는 생각이 많이 듭니다. MySQL 기반의 대용량 처리를 진행하는 경우 다른 적절한 도구를 찾아보는 것이 좋을 거 같습니다.