QueryDSL을 이용한 Batch Insert 성능 개선
JPA를 사용하다 보면 대량의 데이터를 삽입해야 하는 상황에서 saveAll의 성능 한계에 부딪히게 됩니다. 이번 포스팅에서는 JPA saveAll의 성능 이슈를 살펴보고, QueryDSL의 SQLQueryFactory를 활용한 Batch Insert로 성능을 획기적으로 개선하는 방법을 소개합니다.
개요#
대량의 데이터를 데이터베이스에 저장해야 할 때, 일반적으로 JPA의 saveAll 메서드를 사용합니다. 하지만 데이터의 양이 늘어날수록 saveAll의 처리 속도는 급격히 느려질 수 있습니다. 특히 ID 생성 전략이 IDENTITY인 경우, JPA는 Batch Insert를 지원하지 않아 단건으로 Insert 쿼리가 실행되는 문제가 있습니다.
이전 포스팅(Spring Batch에서 Exposed를 이용한 Batch Insert)에서 Exposed를 활용한 성능 개선 방법을 소개한 적이 있습니다. 하지만 오직 Batch Insert만을 위해 JPA 환경에 Exposed라는 새로운 ORM을 도입하고 혼합해서 사용하는 것은 설정의 복잡함이나 학습 곡선 측면에서 비효율적일 수 있습니다.
만약 이미 프로젝트에서 JPA와 QueryDSL을 사용하고 있다면, 추가적인 ORM 도입 없이 QueryDSL-SQL 모듈을 활용하여 Type-Safe하게 Batch Insert를 구현할 수 있습니다. 이번 포스팅에서는 그 방법을 소개합니다.
JPA saveAll의 성능 이슈#
JPA(Hibernate)는 엔티티의 ID 생성 전략이 @GeneratedValue(strategy = GenerationType.IDENTITY)로 설정되어 있을 때, JDBC 레벨의 Batch Insert를 비활성화합니다. 이는 영속성 컨텍스트가 엔티티를 관리하기 위해 Insert 즉시 ID 값을 알아야 하기 때문입니다. 결과적으로 1,000개의 데이터를 저장하면 1,000번의 Insert 쿼리가 데이터베이스로 전송되어 성능 저하의 주원인이 됩니다.
일반적인 JPA의 saveAll 사용 코드는 다음과 같습니다.
1 |
|
위 코드는 사용하기 매우 편리하지만, 대량의 데이터를 처리할 때는 각 엔티티마다 개별적인 Insert 쿼리가 발생하여 네트워크 오버헤드와 데이터베이스 처리 비용이 증가하게 됩니다.
QueryDSL Batch Insert 구현#
QueryDSL-SQL 모듈을 사용하면 JPA 엔티티가 아닌 JDBC 레벨에서 직접 SQL을 구성하여 실행할 수 있습니다. 이를 통해 addBatch 기능을 활용한 Bulk Insert를 구현할 수 있습니다.
의존성 설정#
QueryDSL-SQL을 사용하기 위해 build.gradle.kts에 아래 의존성을 추가합니다.
1 | dependencies { |
QueryDSL-SQL 소개:
QueryDSL-SQL은 JPA 엔티티 모델이 아닌 데이터베이스 스키마를 기반으로 쿼리를 작성할 수 있게 해주는 모듈입니다. JPA가 제공하지 않는 세밀한 SQL 제어(예: Batch Insert, 특정 벤더 전용 구문 등)가 필요할 때 유용하게 사용할 수 있습니다. SQLQueryFactory를 통해 JDBC 레벨의 기능을 Type-Safe하게 사용할 수 있도록 도와줍니다.
구현 코드 예시#
SQLQueryFactory를 사용하여 Batch Insert를 구현하는 방법은 다음과 같습니다.
1 |
|
코드 설명
- RelationalPathBase: SQL 쿼리 작성을 위해 대상 테이블의 메타데이터를 정의합니다.
- addBatch(): 루프를 돌며 데이터를 즉시 Insert 하지 않고, JDBC의 Batch 기능을 활용하기 위해 메모리에 쿼리 파라미터들을 쌓아둡니다.
- execute(): 쌓여있는 Batch 쿼리를 데이터베이스로 한 번에 전송하여 실행합니다.
MySQL 최적화 옵션: rewriteBatchedStatements#
MySQL을 사용하는 경우, JDBC 연결 URL에 rewriteBatchedStatements=true 옵션을 반드시 추가해야 합니다.
1 | jdbc:mysql://localhost:3306/mydb?rewriteBatchedStatements=true |
이 옵션이 필요한 이유:
기본적으로 MySQL JDBC 드라이버는 addBatch()로 들어온 쿼리들을 개별적인 Insert 구문으로 전송합니다. 하지만 이 옵션을 활성화하면 드라이버 레벨에서 여러 개의 Insert 구문을 하나의 INSERT INTO ... VALUES (...), (...), (...) 형태의 Multi-Value Insert 구문으로 재작성(Rewrite)하여 전송합니다. 이를 통해 네트워크 패킷 수를 획기적으로 줄이고 데이터베이스의 파싱 비용을 절감하여 성능을 극대화할 수 있습니다.
성능 비교#
성능 측정 코드#
정확한 성능 측정을 위해 saveAll과 QueryDSL addBatch의 실행 시간을 각각 측정했습니다.
1 |
|
측정 방식 설명
- 반복 측정: 각 데이터 구간(100건 ~ 10,000건)마다 총 5회 반복하여 측정했습니다.
- Warm-up 고려: 테스트 실행 시 첫 번째 회차는 결과에서 제외했습니다. 이는 데이터베이스 커넥션 풀(Connection Pool)에서 커넥션을 처음 생성하는 초기 비용 등 초기화 작업에 소요되는 시간이 포함되어 결과가 왜곡되는 것을 방지하기 위함입니다.
- 평균값 산출: 첫 회차를 제외한 나머지 4회의 실행 시간을 합산하여 평균값을 산출함으로써 보다 신뢰성 있는 성능 데이터를 얻었습니다.
성능 측정 결과#
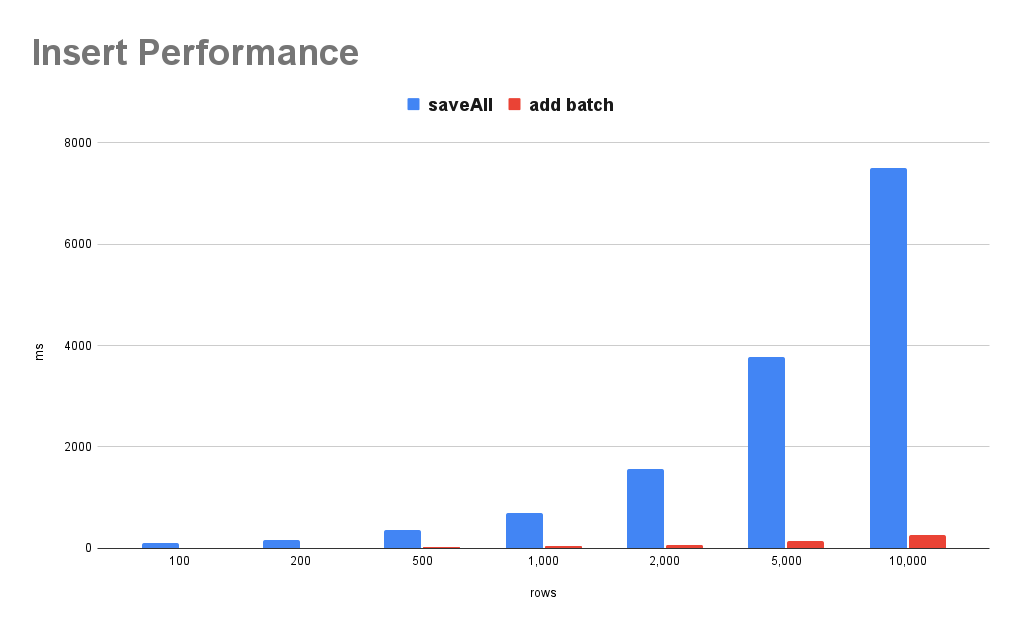
JPA saveAll과 QueryDSL addBatch를 사용했을 때의 성능 차이를 비교한 결과입니다. 데이터 개수가 늘어날수록 성능 차이가 확연하게 벌어지는 것을 확인할 수 있습니다.
| rows | saveAll (ms) | add batch (ms) | 성능 개선율 |
|---|---|---|---|
| 100 | 104 | 12 | 88.50% |
| 200 | 174.5 | 16 | 90.80% |
| 500 | 370.25 | 27.5 | 92.60% |
| 1,000 | 695 | 56 | 91.90% |
| 2,000 | 1,574 | 68 | 95.70% |
| 5,000 | 3,778 | 140 | 96.30% |
| 10,000 | 7,505 | 265 | 96.50% |
- saveAll: JPA Repository의 saveAll 메서드 사용
- add batch: QueryDSL SQLQueryFactory의 addBatch 사용
10,000건 기준으로 약 96.5%의 성능 개선 효과가 있었습니다. saveAll이 약 7.5초 걸리는 작업을 Batch Insert로는 0.26초 만에 처리할 수 있습니다.
결론#
대량의 데이터를 처리해야 하는 배치성 작업이나 초기 데이터 적재 시에는 JPA의 saveAll보다는 JDBC Batch Insert를 사용하는 것이 필수적입니다.
특히, 오직 Batch Insert 성능 개선만을 위해 Exposed와 같은 새로운 ORM을 도입하는 것은 프로젝트의 복잡도를 높일 수 있습니다. 이미 JPA와 QueryDSL을 사용 중인 환경이라면, QueryDSL-SQL을 활용하는 것이 추가적인 학습 곡선이나 설정의 번거로움 없이 Type-Safe하게 성능을 극대화할 수 있는 가장 효율적인 대안입니다.
프로젝트에서 대량 Insert가 필요한 구간이 있다면, 별도의 라이브러리 추가 없이 QueryDSL-SQL을 통해 성능과 생산성을 동시에 챙겨보시기를 권장합니다.