Spring Batch로 애플리케이션을 작성하는 경우 내부 데이터가 아니라 외부의 데이터를 가져와서 가공해야 하는 경우 데이터 파이프라인은 어떻게 구축해야 할지 결정해야 합니다. 예를 들어 데이터베이스에 직접 연결해서 필요한 데이터를 쿼리 하여 가져올 것인지, 아니면 csv 등 파일을 주고받는 방식, HTTP API를 통해서 가져오는 방식 등등 여러 가지 방식이 있습니다. 데이터베이스 연결 방식, 파일방식은 스프링 배치에서 기본 제공해 주고 있지만 HTTP Paging 기반 Reader는 제공해 주고 있지 않아 해당 기능을 Item Reader를 직접 구현해 보겠습니다. 부족한 부분은 프로젝트에 맞게 추가하셔도 좋을 거 같습니다.
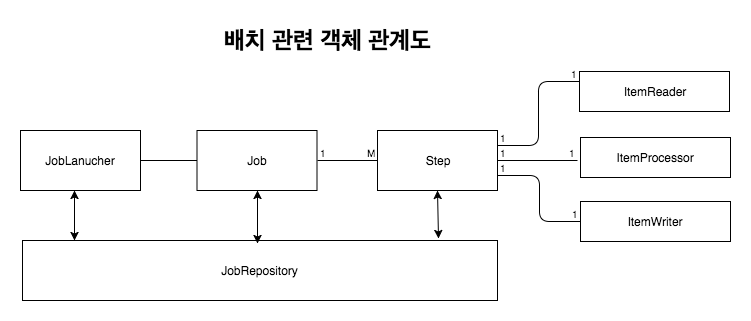
읽기(read) : 데이터 저장소(일반적으로 데이터베이스)에서 특정 데이터 레코드를 읽습니다.
처리(processing) : 원하는 방식으로 데이터 가공/처리합니다.
쓰기(write) : 수정된 데이터를 다시 저장소에 저장합니다.
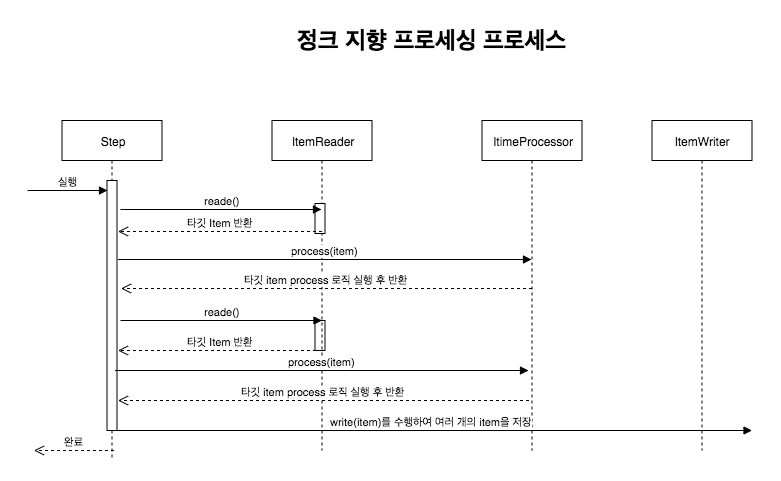
Reader에서 데이터를 하나 읽어 옵니다.
읽어온 데이터를 Processor에서 가공합니다.
가공된 데이터들을 별도의 공간에 모은뒤, Chunk 단위만큼 쌓이게 되면 Writer에 전달하고 Writer는 일괄 저장합니다.
Reader와 Processor에서는 1건씩 다뤄지고, Writer에선 Chunk 단위로 처리된다는 것이 중요합니다.
Chunk 지향 처리를 Java 코드로 표현하면 아래처럼 될 것 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13
fun Chunk_처리_방법(chunkSize: Int, totalSize: Int) { vari=0 while (i < totalSize) { val items: MutableList<*> = ArrayList<Any?>() for (j in 0 until chunkSize) { val item: Any = itemReader.read() val processedItem: Any = itemProcessor.process(item) items.add(processedItem) } itemWriter.write(items) i = i + chunkSize } }
즉 chunkSize 별로 묶는 다는 것은 total_size에서 chunk_size 만큼 읽어 자장한다는 의미입니다.
실제 데이터는 rows 23개가 저장되어 있다면 size를 10을 기준으로 2페이지 까지 읽으면 모든 데이터를 다 읽게 됩니다. 2페이지에서는 남은 데이터 rows 3개가 응답되며 3페이지를 조회하면 빈 응답 페이지가 넘어오게 됩니다. 즉 HttpPageItemReader는 content가 빈 배열이 나올 때까지 page를 1식 증가 시키며 다음 페이지를 계속 읽어 나가는 형태로 구성됩니다.
// (4) privatefunreadRow() = url .httpGet(generateQueryParameter()) .responseString() .run { when { second.isSuccessful -> { page++ serializeResponseBody(responseBody = third.get()) } else -> throw IllegalArgumentException("...") // 2xx 응답을 받지 못한 경우는 각 상황에 맞게 구현 } }
// (5) privatefungenerateQueryParameter() = when (parameters) { null -> { listOf( "page" to page, "size" to size, ) } else -> { mutableListOf( "page" to page, "size" to size, ) .plus(parameters) } }
// (6) privatefunserializeResponseBody(responseBody: String): MutableList<T> { val rootNode = objectMapper.readTree(responseBody) val contentNode = rootNode.path("content")
require(rootNode.isEmpty.not()) { "Response Body 값이 비어 있을 수 없습니다." } require(contentNode.isArray) { "Response content 필드는 Array 타입 이어야 합니다." }
content에 해당하는 내용들만 사용하기 때문에 content 노드를 찾아 해당 정보만 시리얼 라이즈를 진행합니다. HTTP Paging API에 대한 응답 형태를 통일화하여 특정 응답에 대해서만 지원 가능하게 유효성 검사 코드가 있습니다. 유연하게 사용 하기를 원하시면 해당 부분을 외부에는 변경이 가능하게 파라미터로 받는 방식으로 진행해도 무방합니다. 다만 통일된 응답 포맷을 갖는 것이 더 바람직하다고 생각합니다.
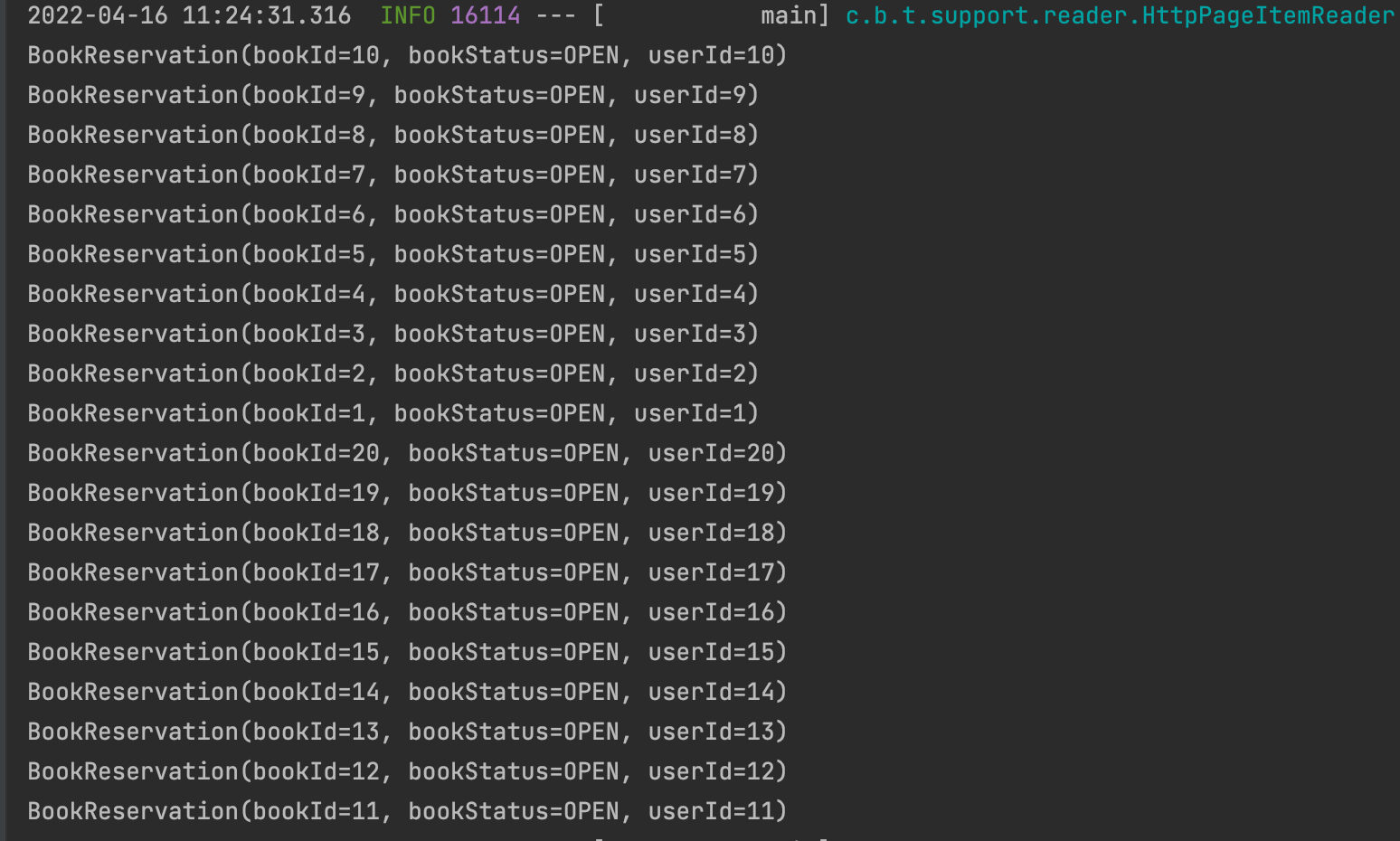
@Configuration classHttpPageReaderJobConfiguration( privateval jobBuilderFactory: JobBuilderFactory, privateval stepBuilderFactory: StepBuilderFactory ) { ... @Bean @StepScope funhttpPageReaderReader( entityManagerFactory: EntityManagerFactory ) = HttpPageItemReader( url = "http://localhost:8080/api/members", // API 주소 size = 10, // 응답받을 content size로 대부분 chunk size와 동일하게 구성 page = 0, // page start 값으로 대부분 0 부터 시작 parameters = listOf( "age" to 10, "email" to "1232@asd.com" ), // 쿼리 파라미터, page, size 외에 값을 사용 contentClass = BookReservation::class// 시리얼라이즈 대상 클래스 )
@Bean @StepScope funhttpPageReaderWriter( ): ItemWriter<BookReservation> = ItemWriter { contents -> for (content in contents) { println(content) } } }
dataclassBookReservation( val bookId: Long, val bookStatus:String, val userId: Long )