Elasticsearch APM 분산 트랜잭션 추적
분산 환경에서는 한 요청이 여러 서비스들의 호출로 이루어집니다. 이런 경우 여러 서비스 사이의 트랜잭션, 로그의 모니터링과 요청에 대한 순차적인 연결이 중요합니다.
분산 트랜잭션 추적#
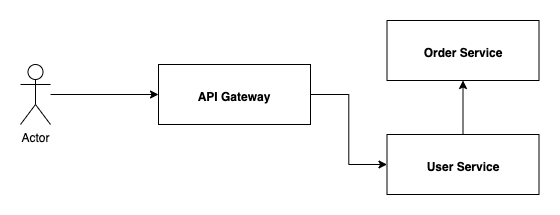
유저의 본인 정보와 본인이 주문한 목록을 조회하는 플로우 입니다. API Gateway -> User Service(유저 정보 조회) -> Order Service(주문 목록 조회)
이런 경우 분산 환경에서의 트랜잭션 추적은 상당히 어려운 부분이 있습니다. 위 예제는 2대의 서버밖에 없지만 연결 서비스가 많아지면 그 복잡도는 더욱 증가됩니다. 이런 경우 연결된 요청의 트랜잭션을 시각화하여 제공해 주는 루션이 매우 유용하게 사용될 수 있습니다. Elasticsearch APM은 이러한 서비스를 제공해 주고 있습니다. Elasticsearch APM의 기초적인 설명 및 설정 방법은 Elasticsearch APM 기본 설정을 참고해 주세요.
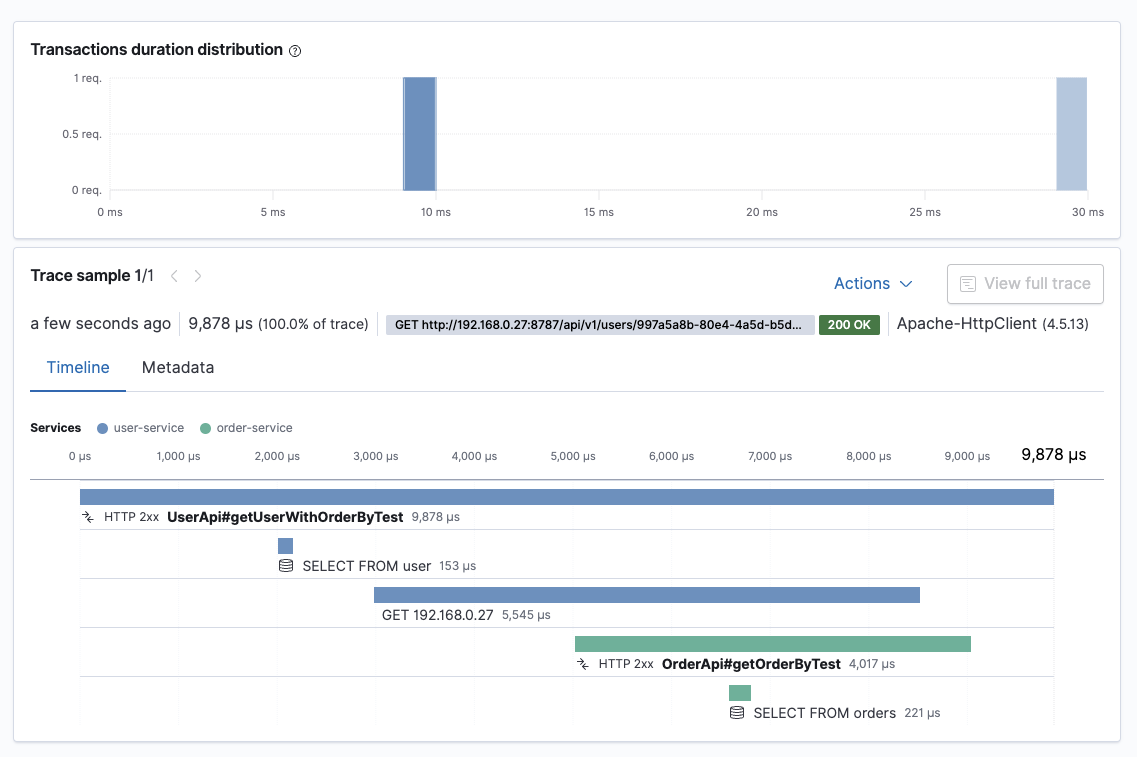
User Service(유저 정보 조회) -> Order Service(주문 목록 조회)의 분산 트랜잭션에 대한 정보를 Elasticsearch APM에서 제공해 주고 있습니다. user-service, order-service의 각각의 트랜잭션에 사항을 표시해 주고 있습니다.
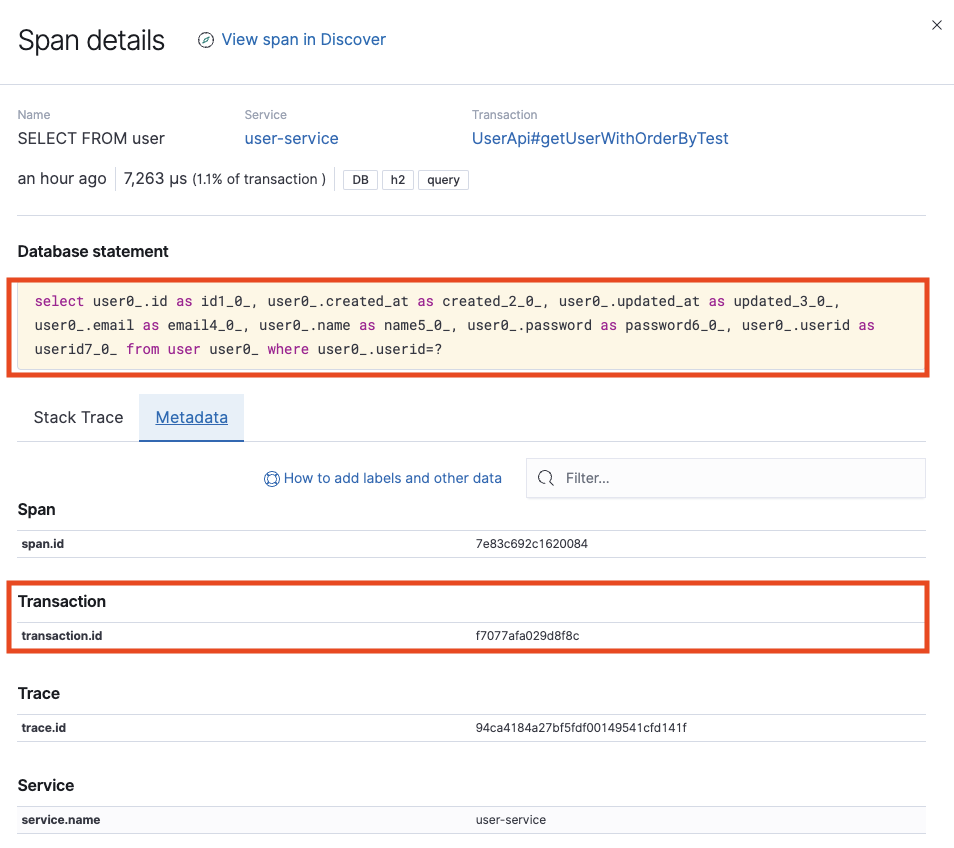
User Service의 트랜잭션에 대한 내용이 있습니다.
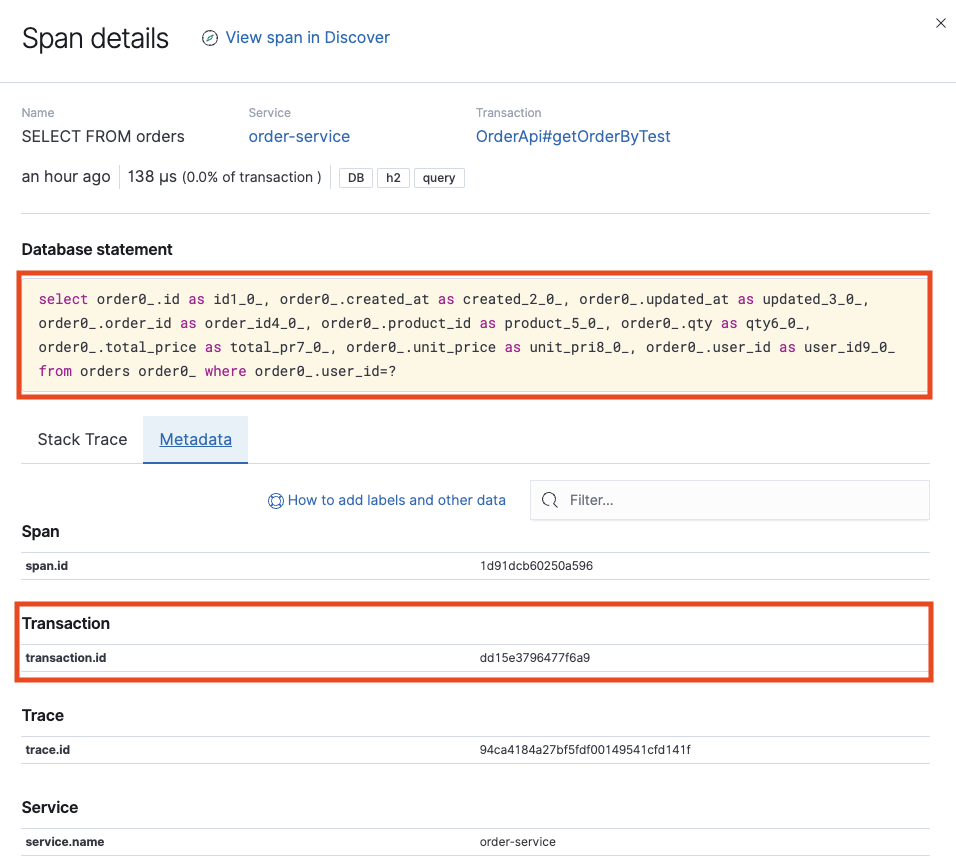
Order Service의 트랜잭션에 대한 내용이 있으며 당연한 이야기겠지만 transaction.id가 서로 다르고 trace.id는 94ca4184a27bf5fdf00149541cfd141f으로 동일한 것을 확인할 수 있습니다.
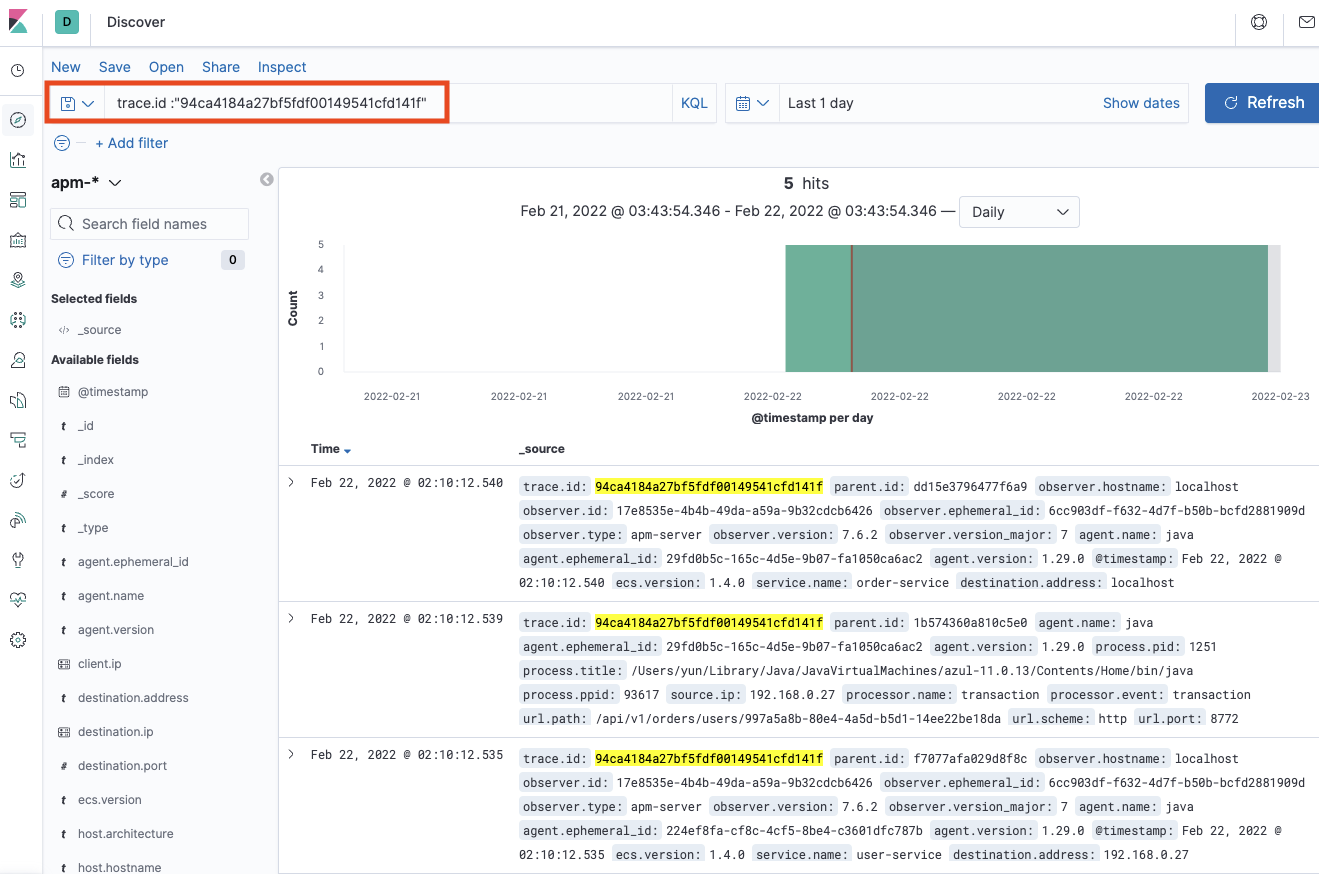
해당 값으로 전체의 분산 트랜잭션의 로그 데이터를 타임라인으로 확인할 수 있습니다.
분산 HTTP 통신 추적#
분산 환경에서 HTTP 통신을 효율적으로 진행하고 추적하기 위해서는 여러 도구의 도움이 필요합니다. Sleuth는 분산 환경에서의 추적을 위한 도구이고 그 외에 도구는 분산 환경에서의 추적을 위한 도구는 아니기 때문에 분산 환경에서의 트레킹을 위한 도구만 살펴보시려면 Sleuth만 참고하시면 됩니다.
유레카 네임 서버#
마이크로서비스 아키텍처는 서로 상호 작용하는 더 작은 마이크로서비스가 필요 하다. 이 밖에도 각 마이크로서비스의 인스턴스가 여러 개 있을 수 있다. 마이크로서비스의 새로운 인스턴스가 동적으로 생성되고 파괴되면 외부 서비스의 연결 및 구성을 수동으로 유지하는 것이 어려울 수 있다. 네임 서버는 서비스 등록 및 서비스 검색 기능을 제공한다. 네임 서버는 마이크서비스가 이들 자신을 등록할 수 있게 하고, 상호 작용하고자 하는 다른 마이크러서비스에 대한 URL을 찾을 수 있게 도와준다.
네임서버 동작#

- 모든 마이크로서비스는 각 마이크로서비스가 시작될때 네임 서버에 등록한다.
- 서비스 소비자가 특정 마이크로 서비스의 위치를 얻으려면 네임 서버를 요청해야한다.
- 고유한 마이크로서비스 ID가 각 마이크로서비스에 지정된다. 이것을 등록 요청 및 검색 요청에서 키로 사용된다.
- 마이크로서비스는 자동으로 등록 및 등록 취소할 수 있다.
- 서비스 소비자가 마이크로서비스ID로 네임 서버를 찾을 때마다 해당 특정 마이크로서비스의 인스턴스 목록을 가져온다.
유레카 서버 설정#
1 | dependencies { |
1 |
|
1 | server: |
유레카 서비스 등록#
1 | dependencies { |
1 |
|
의존성 추가 및 @EnableDiscoveryClient 어노테이션 추가합니다
동작 순서#

- 마이크로서비스 A의 각 인스턴스가 시작되면 유레카 네임 서버에 등록한다.
- 서비스 소비자 마이크로서비스는 마이크로서비스 A의 인스턴스에 대해 유레카 네임 서버를 요청한다.
- 서비스 소비자 마이크로서비스는 립본 클라이언트-클라이언트 로드 밸런서를 사용해 소출할 마이크로서비스 A의 특정 인스턴스를 결정한다.
- 서비스 소비자 마이크로서비스는 마이크로서비스 A의 특정 인스턴스를 호출한다.
유레카의 가장 큰 장점은 서비스 소비자 마이크로서비스가 마이크로서비스 A와 분리된다는 것이다. 서비스 소비자 마이크로서비스는 마이크로서비스 A의 새로운 인스턴스가 나타나거나 기존 인스턴스가 디운될 때마다 재구성할 필요가 없다.
선언적 Rest 클라이언트 - Feign#
페인은 최소한의 구성과 코드로, REST 서비스를 위한 REST 클라이언트를 쉽게 작성할 수 있습니다. 간단한 인터페이스로, 적절한 어노테이션을 사용하는 것이 특징입니다. 페인은 립본 및 유레카와 통합하여 사용하면 더욱 효율성이 높아지게 됩니다.
1 | dependencies { |
Feign Client Interface#
1 |
|
- Controller 코드를 작성하듯이 작성합니다.
- 중요한 것은 이것은 인터페이스이며, 적절한 어노테이션 기반으로 동작한다는 것입니다.
Feign Client 호출#
1 |
|
/api/v1/users/{userId}/orders를 호출하면 인터페이스로 정의한 OrderClient를 사용해서 사용자의 주문 정보를 조회하게 됩니다.
Sleuth#
스프링 클라우드 슬루스(Sleuth)는 마이크로 서비스 환경에서 서로 다른 시스템의 요청을 연결하여 로깅을 해줄 수 있게 해주는 도구입니다. 이런 경우 슬루스를 이용해서 쉽게 요청에 대한 로깅을 연결해서 볼 수 있습니다. 또 RestTemplate, 페인 클라이언트, 메시지 채널 등등 다양한 플랫폼과 연결하기 쉽습니다.
1 | implementation("org.springframework.cloud:spring-cloud-starter-sleuth") |
User Service, Order Service에 각각 추가 sleuth 디펜던시를 추가한 이후에 User Service(유저 정보 조회) -> Order Service(주문 목록 조회)를 하는 경우 아래 로그처럼 Trace ID로 연결되어 분산 HTTP 통신을 연결할 수 있습니다.
1 | 2022-02-22 04:08:56.987 INFO [user-service,3defc05b993ef0c3,40dc9a19201f8a69] 1578 --- [nio-8787-exec-9] c.s.member.config.HttpLoggingFilter : |
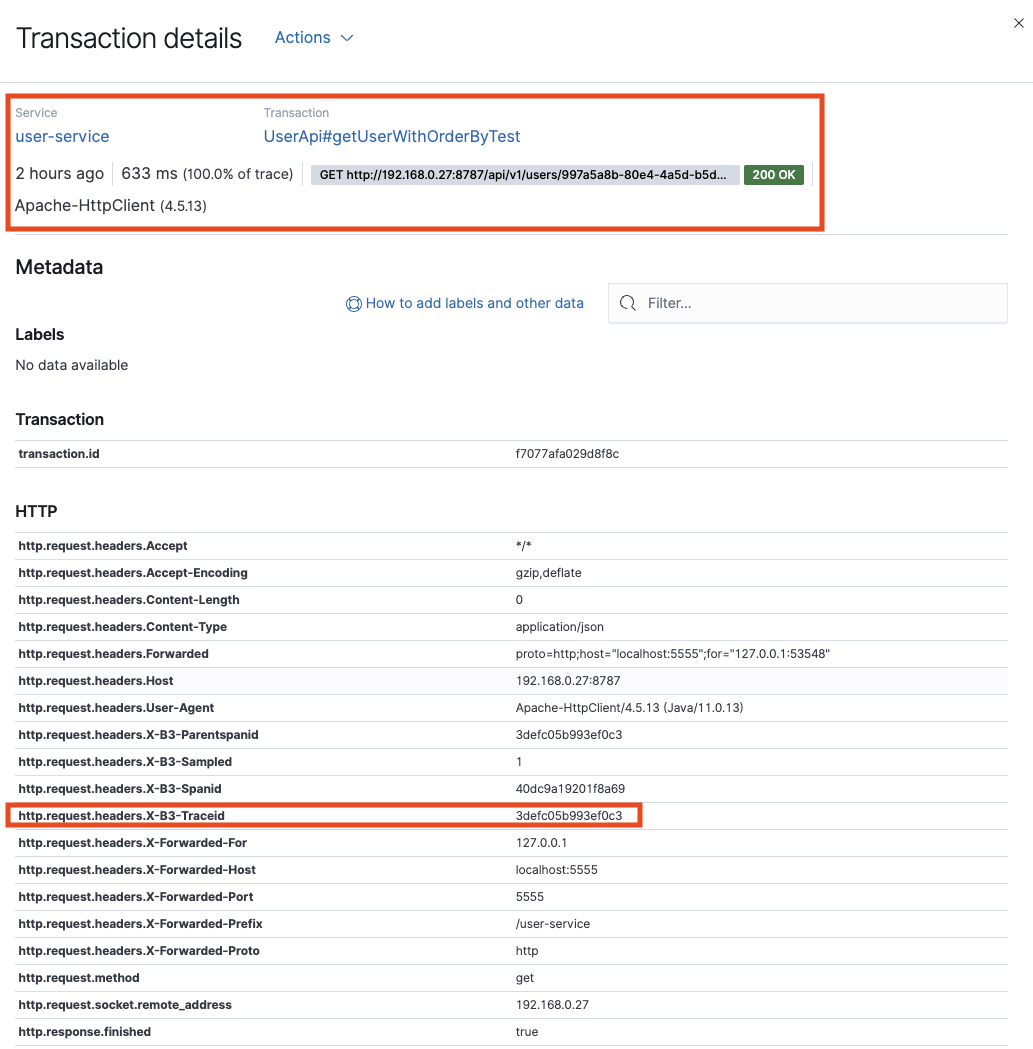
User Service의 http.request.headers.X-B3-Traceid:3defc05b993ef0c3 로그에 있는 값을 확인할 수 있습니다.
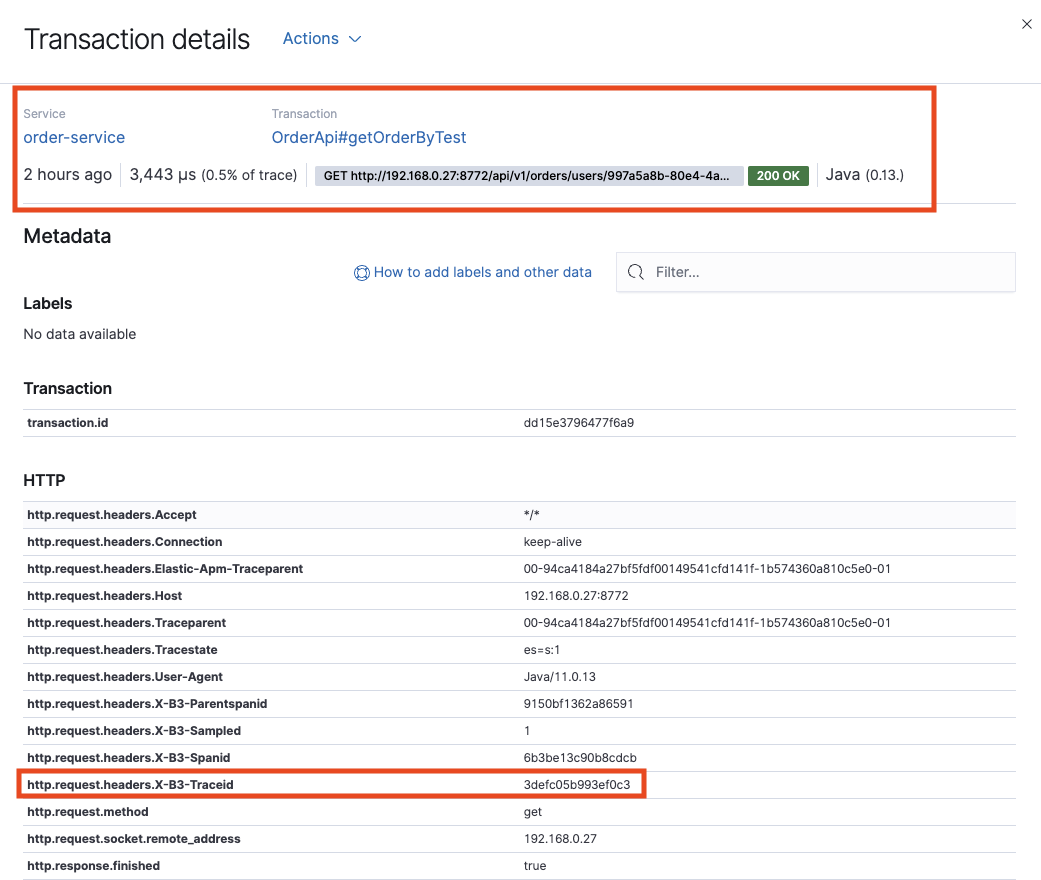
Order Service의 http.request.headers.X-B3-Traceid:3defc05b993ef0c3 로그에 있는 값으로 분산 환경에서 HTTP 요청에 대한 로그를 연결할 수 있습니다.