Isolation Repeatable Read을 보장 하기 위한 JPA JPQL의 동작 원리
JPQL 조회 방식#
findById() 같은 경우는 영속성 컨텍스트를 먼저 찾고 영속성 컨텍스트에 해당 엔티티가 있으면 그 값을 바로 리턴합니다. 이를 1차 캐시라고 말합니다. 반면 JPQL은 영속성 컨텍스트를 먼저 조회하지 않고 데이터베이스에 Query 하여 결과를 가져옵니다. 그리고 아래와 같은 흐름으로 영속성 컨텍스트를 저장을 시도합니다.

- JPQL을 호출하면 데이터베이스에 우선적으로 조회한다.
- 조회한 값을 영속성 컨텍스트에 저장을 시도한다.
- 저장을 시도할 때 해당 데이터가 이미 영속성 컨텍스트에 존재하는 경우(영속성 컨텍스트에서는 식별자 값으로 식별) 데이터베이스에서 조회한 신규 데이터를 버린다.
JPQL 조회 방식 테스트#
1 |
|
해당 코드는 단순합니다. Team은 N 개의 Member를 가질 수 있는 구조입니다. TeamRepository의 findFetchJoinBy 메서드는 단순히 팀 이름으로 Fetch Join 해서 해당 Team에 속한 모든 Member를 조회하는 JPQL 코드입니다. JPQL이 위에서 설명한 방식대로 동작하는지 아래 테스트 코드로 확인해보겠습니다.
1 |
|
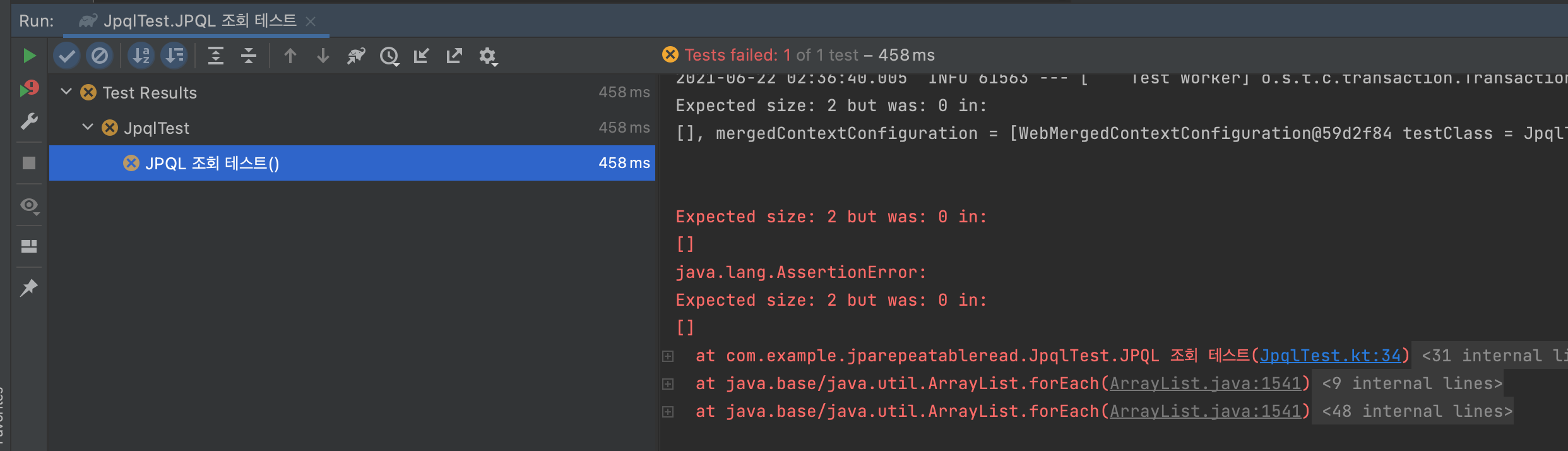
해당 테스트는 실패합니다. teamA를 저장하고, member1, member2에 각각 teamA를 저장했습니다. 그리고 Fetch Join을 통해서 아래 SQL 문으로 데이터를 조회합니다.
1 | SELECT team0_.id AS id1_1_0_, |
올바르게 데이터가 저장되고, 조회 쿼리 또한 문제가 없는데 해당 테스트는 실패합니다.
왜 테스트가 실패하는 것일까 ?#
주의!
Team 객체를 저장할 때 member1, member2를 members 컬렉션에 저장하는 양방향 편의 메서드를 작성하면 해당 테스트는 실패하지 않습니다. JPQL의 동작 방식을 테스트해보기 위해서 작성했습니다.
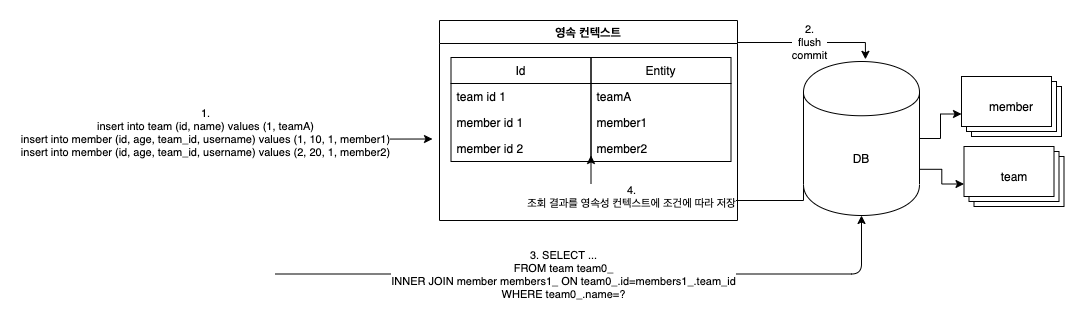
영속성 컨텍스트와 데이터베이스 흐름을 자세히 살펴 보겠습니다.
- teamA, member1, memeber2를 영속화를 위해서 persist 메서드를 통해서 영속성 컨텍스트에 저장
- 데이터베이스에 영구적으로 저장하기 위해서 flush, commit을 진행
- findFetchJoinBy를 통해서 조회를 진행, JPQL은 영속성 컨텍스트를 먼저 들리는 것이 아니라 데이터베이스로 조회
- 조회한 결과를 영속성 컨텍스트에 저장 시도, 이미 존재하는 경우(영속성 컨텍스트에서는 식별자 값으로 식별) 데이터베이스에서 조회한 값을 버림, 즉 member1, memeber2가 포함된 데이터는 버리게 됩니다.
위와 같은 메커니즘으로 JPQL이 동작하니 해당 테스트는 실패하게 됩니다. 그렇다면 조회 직전에 영속성 컨텍스트를 초기화 하면 어떻게 동작할까요?
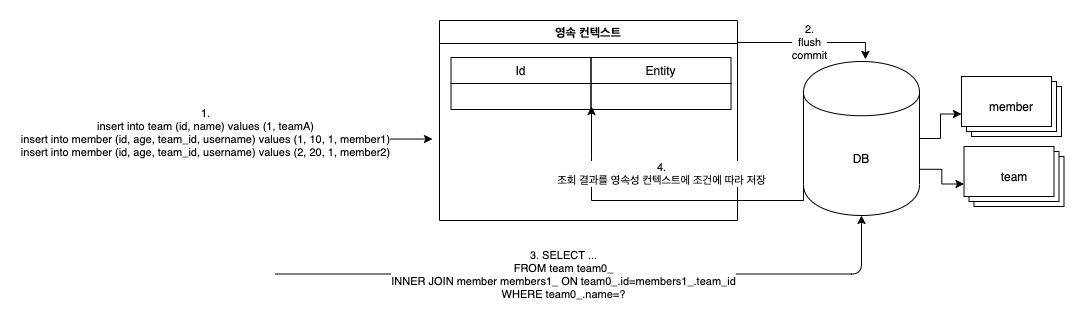
3번 조회 전에 영속성 컨텍스트를 초기화를 하면 위 이미지처럼 3번에서 조회한 값을 영속성 컨텍스트에 저장하게 됩니다.
1 | { |
em.clear() 메서드로 영속성 컨텍스트를 제거하고 테스트를 돌리면 정상적으로 동작하게 됩니다.

위 테스트를 통해서 JPQL 조회 방식에 대해서 검증을 진행 완료했습니다.
그렇다면 JPQL은 왜 이렇게 동작하는 것일까요?#
JPQL에서 데이터베이스에서 조회한 값을 그대로 사용하지 않는 이유는 트랜잭션 격리 수준 때문입니다. 트랜잭션의 격리 수준이란 동시에 여러 트랜잭션이 처리될 때, 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있도록 허용할지 말지를 결정하는 것입니다.
결론부터 말씀드리면 JPQL 조회 방식 때문에 Isolation 레벨이 REPEATABLE READ 수준까지 올라가게 됩니다. 해당 트랜잭션 REPEATABLE READ 보다 낮은 READ UNCOMMITTED, READ COMMITTED 경우에도 REPEATABLE READ의 수준으로 애플리케이션 한에서 보장받을 수 있습니다.
격리 수준#
| ISOLATION | DIRY READ | NOE-REPEATABLE READ | PHANTOM READ |
|---|---|---|---|
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | X | O | O |
| REPEATABLE READ | X | X | O(InnoDB는 발생하지 않음) |
| SERIALIZABLE | X | X | X |
각 격리 수준마다 동시에 여러 트랜잭션이 처리될 때 문제가 발생하기 때문에 더 높은 격리 레벨이 필요해집니다. 먼저 각 Isolation에서 발생할 수 있는 문제들을 간단하게 정리해보겠습니다.
READ UNCOMMITTED#
READ UNCOMMITTED 격리 수준에서는 트랜잭션에서의 변경 내용이 COMMIT, ROLLBACK 여부와 상관없이 다른 트랜잭션에 영향을 줍니다.

- 사용자 A는 emmp_no = 5000의 Han을 트랜잭션 BEGIN 이후 INSERT(아직 COMMIT 완료되지 않음)
- 사용자 B는 A가 아직 COMMIT 하기 전 emmp_no = 5000 조회, 아직 COMMIT 하지 않은 emmp_no = 5000 조회 성공
- 사용자 A는 COMMIT을 하여 데이터베이스에 저장
3번에서 COMMIT을 진행하여 데이터베이스에 영구 저장하면 문제는 없습니다. 하지만 문제가 발생해서 3번에서 Rollback을 진행하게 되면 사용자 B는 더 이상 유효하지 않은 데이터를 읽고 해당 로직을 이어가게 됩니다. 이런 현상을 더티 리드라고 합니다.
즉, READ UNCOMMITTED에서는 더티 리드가 발생하며 RDBMS 표준에서도 트랜잭션 격리 수준으로 인정하지 않을 정도로 정합성에 문제가 많은 격리 수준이기 때문에 거의 사용하지 않습니다.
READ COMMITTED#
READ COMMITTED 레벨에서는 더티 리드 현상은 발생하지 않습니다. 어떤 트랜잭션에서 데이터를 변경했더라도 COMMIT이 완료된 데이터만 다른 트랜잭션에서 조회가 가능하기 때문입니다.

- 사용자 A는 emp_no=5000인 사원의 first_name을 Han -> Yun으로 변경 경
- 1번 변경 시 새로운 값인 Yun은 즉시 기록되고 이전 값인 Han은 언두 영역으로 백업된다.
- 사용자 A가 커밋을 수행하기 전에 사용자 B가 emp_no=5000을 조회하면 Yun이 아니라 Han으로 조회된다. 즉 언두 영역에서 데이터를 가져온 것이다.
- 사용자 A가 최종 적으로 COMMIT 하여 데이터를 영구적으로 반영한다.
READ COMMITTED 격리 수준에서는 어떤 트랜잭션에서 변경한 내용이 커밋 되기 전까지 다른 트랜잭션에서 그러한 변경 내용을 조회할 수 없습니다. 따라서 사용자 A가 변경된 내용을 커밋 하면 그때부터 다른 트랜잭션에서도 백업된 언두 레코드가 아니라 새롭게 변경된 데이터를 참조할 수 있게 됩니다.
READ COMMITTED 격리 수준에서도 NON-REPEATABLE READ가 가능하여 문제가 있습니다.

- 사용자 B가 BEGIN 명령으로 트랜잭션을 시작하고 first_name=‘Yun’ 검색하여 검색 결과 없음 응답받음
- 사용자 A가 이름을 'Yun’으로 변경하고 커밋을 실행
- 사용자 B는 똑같이 SELECT 하면 이번에는 결과가 1건이 조회된다.
이는 별다른 문제가 없어 보이지만, 사실 사용자 B가 하나의 트랜잭션 내에서 똑같은 SELECT 쿼리를 실행했을 때는 항상 같은 결과를 가져와야 한다는 REPEATABLE READ 정합성에 어긋납니다.
사용자 B가 하나의 트랜잭션 내에서 똑같은 SELECT 쿼리를 실행했을 때는 항상 동일한 결과를 가져와야 합니다. 이를 REPEATABLE READ 라고 하며 READ COMMITTED 레벨에서는 NOE-REPEATABLE READ 문제가 발생하게 됩니다.
해당 문제를 정산 시스템의 시나리오로 다시 풀어서 설명드리겠습니다. (물론 아래 흐름처럼 정산 시스템이 동작하지는 않습니다. 예시를 들어 설명하기 위함입니다.)
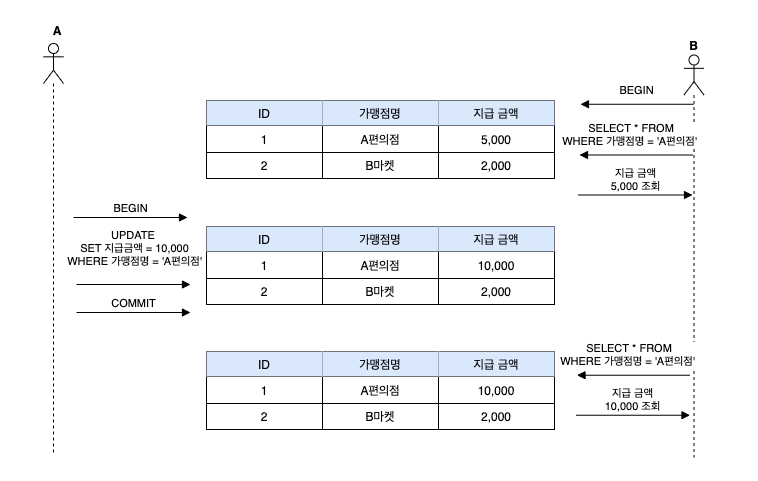
- 사용자 B는 A 편의점 지급 금액을 조회하여 지급 금액 5,000을 조회합니다.
- 사용자 A는 A 편의점 지급 금액을 5,000 -> 10,000으로 변경합니다.
- 사용자 B는 A 편의점 지급 금액을 다시 조회합니다. 1번에서 조회한 지급 금액 5,000이 아니라 10,000이 조회됩니다.
다시 조회하지 않으면 문제가 없다고 생각할 수 있지만 이는 문제의 본질이 아닙니다. 사용자 B는 트랜잭션을 BEGIN으로 시작했으면 해당 시점에서 데이터는 변경이 없이 반복적으로 조회를 하여도 결과가 반드시 동일해야 하는 것입니다. 즉 해당 조회 트랜잭션이 시작한 그때의 스냅샷의 데이터를 조회해야 합니다.
B마켓의 지급 금액을 2,000 -> 3,000으로 변경해도 동일합니다. 트랜잭션 BEGIN으로 데이터를 조회를 시작하면 그 시점의 스냅샷 데이터로 조회하는 것이며 반복적인 조회를 해도 해당 스냅샷의 데이터를 동일하게 조회해야 합니다.
READ COMMITTED 격리 수준에서는 트랜잭션 내에서 실행되는 SELECT 문장과 트랜잭션 외부에서 실행되는 SELECT 문장의 차이가 없습니다. 하지만 REPEATABLE READ 격리 수준에서는 기본적으로 SELECT 쿼리 문장도 트랜잭션 범위 내에서만 작동해야 합니다. 즉, BEGEN TRANSACTION으로 트랜잭션을 시작한 상태에서는 동일한 쿼리를 반복해서 실행해봐도 동일한 결과를 보장받습니다. 아무리 다른 트랜잭션에서 그 데이터를 변경하고자 COMMIT을 실행한다 하더라도 동일한 결과를 응답받습니다.
REPEATABLE READ#
REPEATABLE READ는 MySQL의 InnoDB 스토리지 엔진에서 기본적으로 사용되는 격리 수준입니다. 이 격리 수준에서는 READ COMMITED 격리 수준에서 발생하는 NON-REPEATABLE READ 문제가 발생하지 않습니다. InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK될 가능성에 대비해 변경되기 전 레코드를 언두 공간에 백업해두고 실제 레코드 값을 변경하며 이러한 변경 방식을 MVCC라고 합니다. REPEATABLE READ와 READ COMMITTED의 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번째 이전 버전까지 찾아 들어가야 하는지에 있는 것입니다.
모든 InnodB 트랜잭션은 고유한 트랜잭션 번호(순차적으로 증가하는 값)를 가지며, 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함돼 있습니다. 이 트랜잭션 번호를 보고 어떤 데이터를 보여줄지 결정하게 됩니다.

- 이미 TRX-ID: 6 INSERT 되어 있다고 가정한다.
- 사용자 B의 TRX-ID: 10번으로 emp_no=5000 조회, Han 응답
- 사용자 A의 TRX-ID: 12번으로 emp_no=5000 first_name Han -> Yun으로 변경하고 최종 COMMIT, UNDO 영역의 이전 데이터 Yun 백업
- 사용자 B의 TRX-ID: 10번으로 emp_no=5000 조회 다시 조회, 10번 트랜잭션 안에서 실행되는 모든 SELECT 쿼리는 트랜잭션 번호가 10보다 작은 트랜잭션 번호에서 변경한 것만 본다 즉, 동일하게 Han 응답.
4번에서 데이터를 다시 조회하지만 트랜잭션 번호가 12번으로 자신의 트랜잭션 번호 6번 보다 크기 때문에 UNDO 영역의 데이터를 선택하게 되어 동일한 트랜잭션에서 반복적인 읽기를 하더라도 동일한 결과를 보장받습니다. SELECT ... FOR UPDATE 조회 시에는 그 결과가 다르겠지만 여기까지는 더 설명하지는 않겠습니다.
다시 JPQL#
다시 JPQL 조회 방식으로 돌아가겠습니다. 이미 영속성 컨텍스트에 데이터가 존재하는 경우에는 DIRY READ가 발생해서 아직 COMMIT 되지 않은 데이터를 읽어 오더라도 4번 항목에서 데이터를 버리게 돼서 애플리케이션에서는 DIRY READ가 발생하지 않으며 동일하게 NON-REPEATABLE READ가 발생해서 동일 트랜잭션에서 반복 읽기 시에 UNDO 영역의 데이터를 가져오지 않더라도 애플리케이션에서는 NON-REPEATABLE READ가 발생하지 않습니다.
MySQL을 사용한다면 기본적으로 격리 레벨이 REPEATABLE READ 이긴 하지만 JPA가 MySQL만을 지원하지 않을뿐더러 트랜잭션 설정으로 격리 레벨을 임의로 변경할 수 있습니다. 만약 가장 낮은 레벨인 READ UNCOMMITTED으로 조회하더라도 JPQL의 조회 방식으로 인해서 애플리케이션 한에서 REPEATABLE READ 격리 레벨을 보장받을 수 있습니다. 물론 이 동작을 믿고 MySQL에서 격리 레벨은 낮추면 안 됩니다. 어디까지나 이는 동일한 영속성 컨텍스트를 공유할 때만 동작하며, Projection과 같이 영속성 컨텍스트에서 관리하지 않는 경우에는 문제가 생깁니다.
참고#
- 자바 ORM 표준 JPA 프로그래밍
- Real MySQL ISOLATION 설명은 해당 도서를 참고했습니다.