Spring Batch Reader 성능 분석 및 측정 part 2
Spring Batch Reader 성능 분석 및 측정 part 1 이어지는 글입니다.
HibernateCursorItemReader#
HibernateCursorItemReader를 이해하기 앞서 JDBC를 이용하여 대량의 데이터를 가져오는 방에 대해서 이야기해보겠습니다. 이론적인 설명은 Real MySQL을 보고 정리했습니다. MySQL를 사용 중이면 정말 추천드리는 도서입니다.
대용량 조회 스트리밍 방식#
JDBC 표준에서 제공하는 Statement.setFetchSize()를 이용해서 MySQL 서버로부터 SELECT된 레코드를 클라이언트 애플리케이션으로 한 번에 가져올 레코드의 건수를 설정하는 역할을 합니다. 하지만 Connector/J에서 Statement.setFetchSize()의 표준을 지원하지 못하고 있습니다. 즉 Statement.setFetchSize(100)을 설정해도 100개의 레코드만 가져오게 동작하지는 않습니다.

Connector/J를 사용해서 조회 쿼리를 실행하면(Statement.executeQuery()를 이용) 실행하면 Connetor/J가 조회 결과를 MySQL 서버로부터 실행 결과 모두를 다운로드해 Connector/J가 관리하는 캐시메모리에 그 결과를 저장합니다. 당연히 조회 쿼리의 결과 가를 모두 응답받기 전까지는 Blocking 상태이며 모든 결과를 응답받게 되면 ResultSEt의 핸들러를 애플리케이션에게 반환합니다. 그 이후부터 우리가 일반적으로 사용하는 ResultSet.next(), ResultSet.getSting()의 호출이 가능하고, 해당 메서드를 호출하면 Connector/J가 캐시 해둔 값으로 빠르게 응답이 가능합니다.(MySQL 서버까지 요청이 가지 않고 Connector/J를 사용한다는 의미) 이것이 클라이언트 커서라고 하며, 이는 매우 효율적이라서 MySQL Connector/J의 기본 동작으로 채택되어 있습니다.
하지만 이는 문제가 있습니다. 대량의 데이터를 조회할 때 해당 쿼리의 결과가 너무 오래 걸리기 때문에 클라이언트로 다운로드하는 데 많은 시간이 소요되며 무엇보다도 애플리케이션의 메모리를 한정적이기 때문에 OOM이 발생하기도 합니다.
JdbcResultSet#
다음 코드는 조회 대상 rows 20,480,000에 대해서 조회하는 코드입니다.
1 | public class JdbcResultSet { |
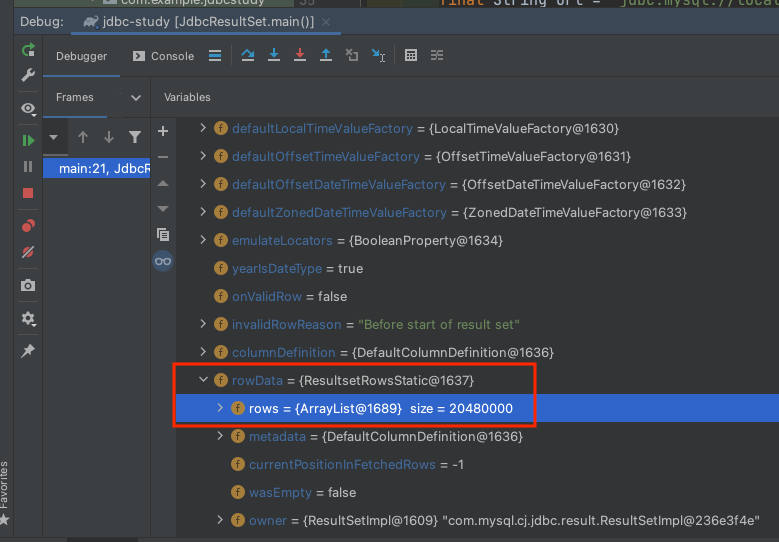
resultSet의 rowData 항목을 디버깅해보고 확인해보면 모든 조회 레코드 rows 20,480,000를 가져온 것을 확인할 수 있습니다. rows의 실제 객체는 ResultsetRowsStatic입니다. 해당 코드의 주석문을 첨부합니다.
Represents an in-memory result set
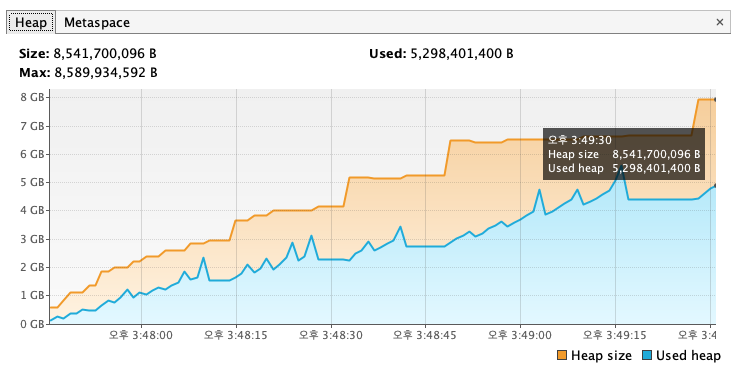
위에서도 언급했듯이 Connector/J를 사용해서 조회 쿼리를 실행하면(Statement.executeQuery()를 이용) 실행하면 Connetor/J가 조회 결과를 MySQL 서버로부터 실행 결과 모두를 다운로드해 Connector/J가 관리하는 캐시메모리에 그 결과를 저장합니다. Connector/J는 실행 결과 모두를 애플리케이션에 캐시를 하기 때문에 Heap 용량이 max 용량인 8,589,934,592 크기 중 5,298,401,400를 사용하고 있습니다. 현재 애플리케이션의 Heap 사이즈가 8GB이므로 OOM이 발생하지 않았지만, 그보다 낮은 Heap 사이즈에서는 발생할 수 있습니다.
ResultSetStreaming#
이러한 문제를 해결하기 위해서 MySQL에서는 Statement.setFetchSize()를 예약된 값인 Integer.MIN_VALUE으로 설정하면 한 번에 쿼리의 결과를 모두 다운로드하지 않고 MySQL 서버에서 한 건 단위로 읽어서 가져가게 할 수 있습니다. 이러한 방식을 ResultSet Streaming 방식이라고 합니다.

ResultSetSteaming 방식은 매번 레코드 단위로 MySQL 서버와 통신해야 하므로 Connector/J의 기본적인 처리 방식에 비해서 느리지만 레코드의 단위가 대량이고 내부적인 애플리케이션의 메모리가 크지 않다면 이 방법을 택할 수밖에 없습니다. 보다 자세한 내용은 Connector-J: 6.4 JDBC API Implementation Notes를 참고해 주세요.
다음 코드도 동일하게 rows 20,480,000에 대해서 조회하는 코드입니다.
1 | public class JdbcResultSetStreaming { |
JdbcResultSet 코드와 거의 동일하며 차이점은 connection.createStatement(...) 메서드로 Statement를 생성할 때 ResultSet.CONCUR_READ_ONLY 설정을 통해서 읽기 전용으로 설정하고, ResultSet.TYPE_FORWARD_ONLY으로 Statement 진행 방향을 앞쪽으로 읽을 것을 설정하고 마지막으로 statement.setFetchSize(Integer.MIN_VALUE); 설정을 통해 MySQL 서버는 클라이언트가 결과 셋을 레코드 한 건 단위로 다운로드한다고 간주합니다. 이는 예약된 값으로 특별한 의미를 갖는 것이 아니며 100으로 설정한다고 해서 100 건 단위로 가져오지 않습니다.
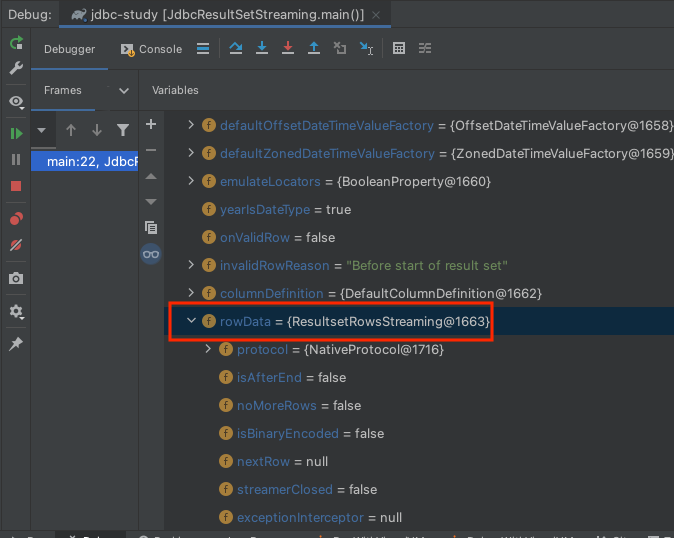
ResultSetStreaming 방식은 말 그대로 스트리밍 해오는 방식이기 때문에 ResultRowsStreaming 객체를 사용합니다. 스트리밍 하기 때문에 ResultRowsStatic 객체와 다르게 rows를 담지 않습니다. 자세한 설명은 해당 객체의 주석문을 첨부하겠습니다.
Provides streaming of Resultset rows. Each next row is consumed from the input stream only on next() call. Consumed rows are not cached thus we only stream result sets when they are forward-only, read-only, and the fetch size has been set to Integer.MIN_VALUE (rows are read one by one).
Type parameters:
– ProtocolEntity type
해당 주석에도 Integer.MIN_VALUE (rows are read one by one). 한 건으로 가져온다고 나와있습니다.
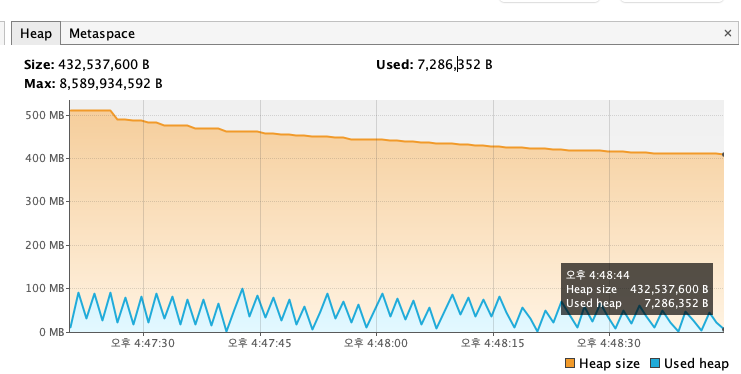
Connector/J에서 모든 결과를 캐시하지 않기 때문에 Heap 메모리는 균일한것 확인할 수 있습니다.
HibernateCursorItemReader#
다시 본론으로 돌아가서 HibernateCursorItemReader에 대해서 설명드리겠습니다. HibernateCursorItemReader는 ResultSetStreaming 방식을 사용합니다. HibernateCursorItemReader의 doRead 코드를 break point를 찍고 보면 다음과 같습니다.
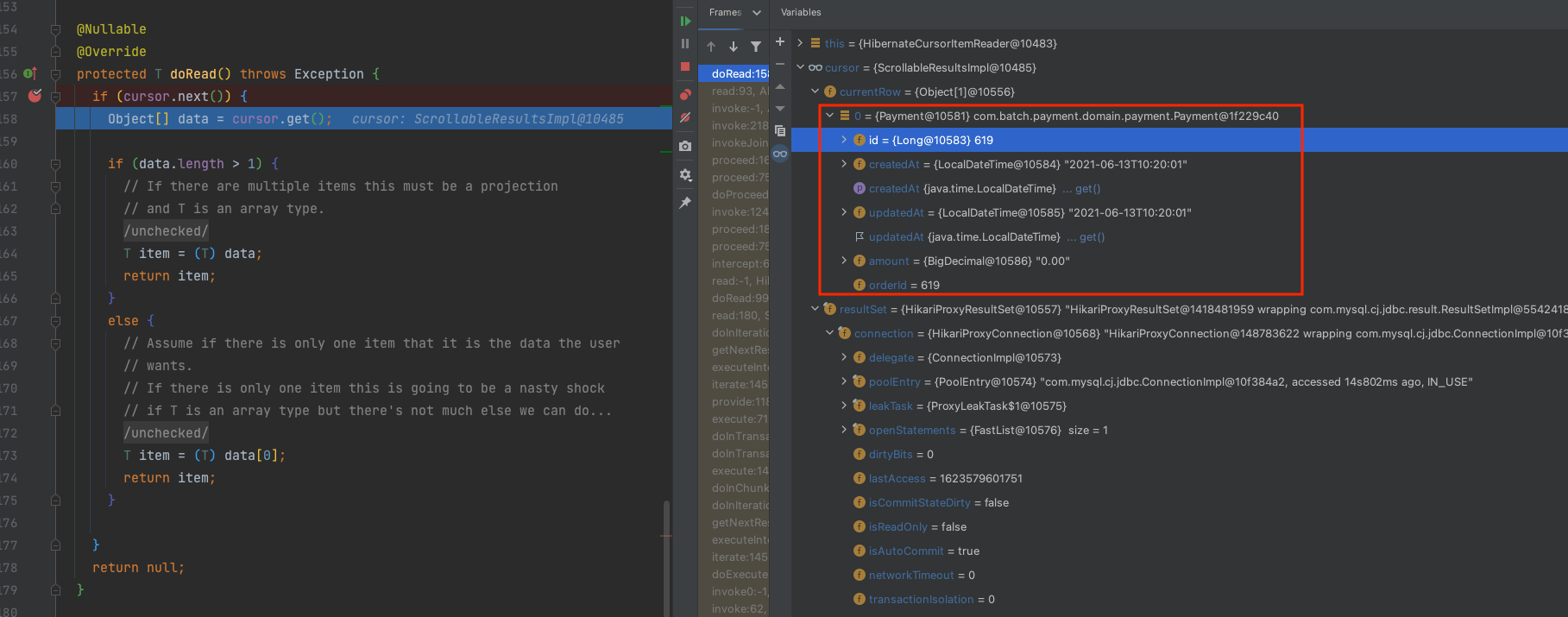
cursor.get();를 통해서 가져온 currentRow 데이터가 1개인 것을 확인할 수 있습니다. 이는 ResultSetStreaming 방식과 동일하게 한건 한건 가져오는 방식과 동일합니다.
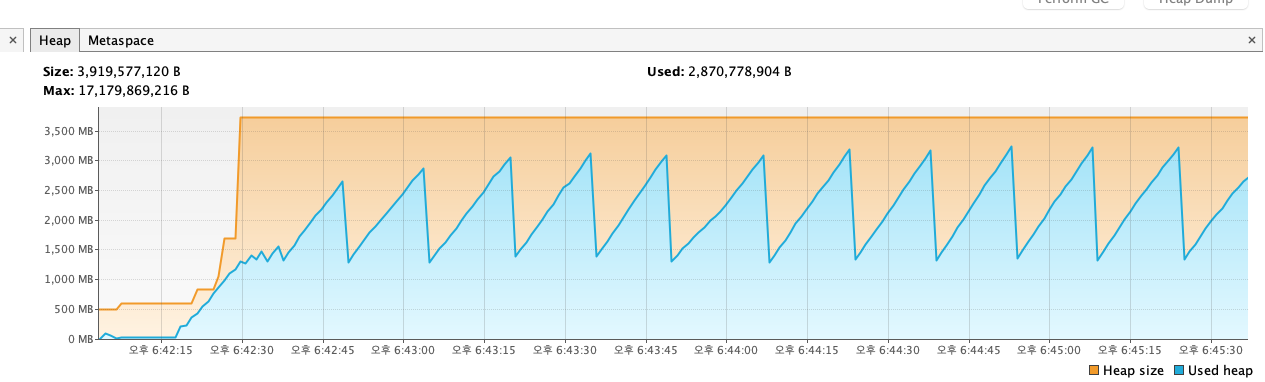
Heap 사이즈를 보면 위에서 확인했던 ResultSetStreaming Heap 사이즈와 비슷한 그래프를 확인할 수 있습니다. 그리고 fetchSize 옵션에 대해 약간 오해가 소지가 있을 수 있습니다.
1 |
|
fetchSize를 위처럼 10으로 주면 마치 Statement.setFetchSize(10)이 입력되게 되며 해당 rows 별로 스트리밍 하는 거 같지만 저건 어디까지나 청크 사이즈 개념으로 해당 해당 Reader가 fetchSize 만큼 읽고 나서 Processor or Writer로 넘어가는 사이즈입니다.
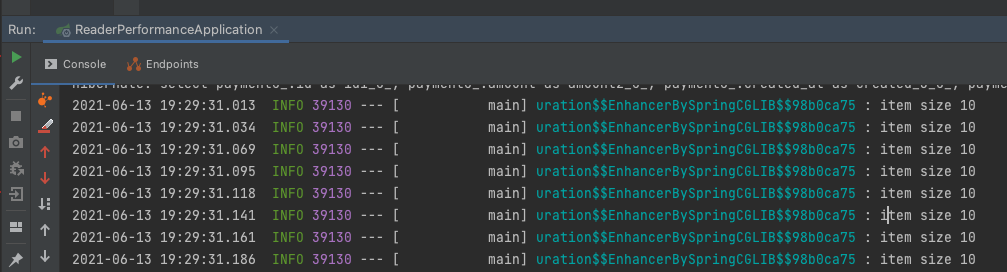
fetchSize를 10으로 설정하면 10단위 Writer으로 넘어 게가 됩니다.
주의 사항#
한 번 맺은 커넥션으로 계속 스트리밍을 하기 때문에 애플리케이션은 한번 연결한 커넥션을 애플리케이션 종료될 때까지 사용하게 됩니다. 이는 Connection을 반납하지 않는 구조이기 때문에 Connection Timeout이 발생할 수 있기 때문에 조심해야 합니다. 당장은 데이터가 상대적으로 적어서 발생하지 않더라도 데이터가 많아짐에 따라 Connection 시간도 증가하기 때문에 각별히 조심해야 합니다.