Spring Batch Reader 성능 분석 및 측정 part 1
스프링 배치 애플리케이션에서 데이터베이스의 대량의 데이터를 처리할 때 Reader에 대한 성능 분석과 성능에 대한 측정을 정리한 포스팅입니다.
조회 대상#
1 | # created_at 인덱스 |
가장 최근 데이터부터 데이터를 읽어 특정 날짜까지 데이터를 읽는 기준으로 Item Reader를 작성했습니다.
대상 리더#
성능#
전체 성능 표#
| Reader | rows | Chunk Size | 소요 시간(ms) |
|---|---|---|---|
| JpaPagingItemReader | 10,000 | 1000 | 778 |
| JpaPagingItemReader | 50,000 | 1000 | 3243 |
| JpaPagingItemReader | 100,000 | 1000 | 8912 |
| JpaPagingItemReader | 500,000 | 1000 | 205469 |
| JpaPagingItemReader | 1,000,000 | 1000 | 1048979 |
| JpaPagingItemReader | 5,000,000 | 1000 | … |
| QueryDslNoOffsetPagingReader | 10,000 | 1000 | 658 |
| QueryDslNoOffsetPagingReader | 50,000 | 1000 | 2004 |
| QueryDslNoOffsetPagingReader | 100,000 | 1000 | 3523 |
| QueryDslNoOffsetPagingReader | 500,000 | 1000 | 15501 |
| QueryDslNoOffsetPagingReader | 1,000,000 | 1000 | 28732 |
| QueryDslNoOffsetPagingReader | 5,000,000 | 1000 | 165249 |
| HibernateCursorItemReader | 10,000 | 1000 | 448 |
| HibernateCursorItemReader | 50,000 | 1000 | 1605 |
| HibernateCursorItemReader | 100,000 | 1000 | 2886 |
| HibernateCursorItemReader | 500,000 | 1000 | 17411 |
| HibernateCursorItemReader | 1,000,000 | 1000 | 25439 |
| HibernateCursorItemReader | 5,000,000 | 1000 | 132552 |
JpaPagingItemReader의 rows 5,000,000 측정은 너무 걸려 측정하지 못했습니다. 대략 5시간 이상까지 측정하다 종료했습니다.
성능 그래프#
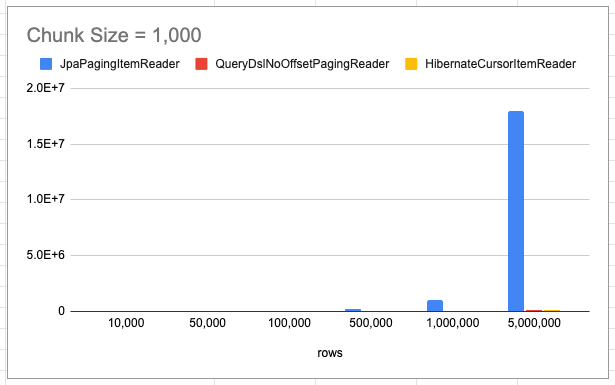
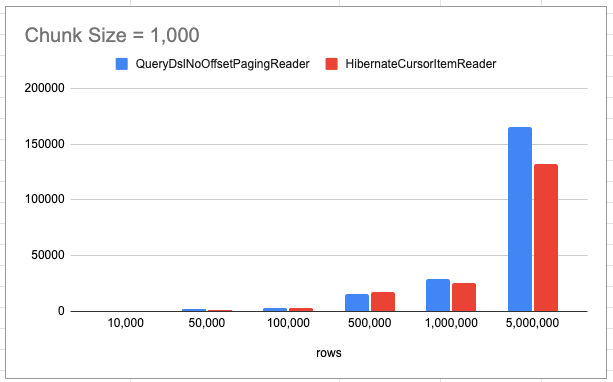
JpaPagingItemReader 리더의 시간이 너무 오래 소요되어 QueryDslNoOffsetPagingReader, HibernateCursorItemReader 리더 비교
전체 코드#
1 |
|
JpaPagingItemReader#
JpaPagingItemReader눈 Spring Batch에서 제공해 주는 ItemReader로 일반적인 페이징 방식을 통해서 가져오는 방식입니다. 모든 데이터를 한 번에 가져와서 처리할 수는 없으니 offset, limit 방식으로 데이터를 가져옵니다. 실제 쿼리는 다음과 같습니다.
1 | select payment0_.id as id1_0_, |
해당 리더는 위 그래프에서 확인했듯이 다른 리더에 비해서 현저하게 드립니다. 읽어야 할 총 데이터가 많고, 청크 후반으로 갈수록 더욱 느려집니다.
1 ~ 2 번째 조회#
1 | Hibernate |
첫 조회 이후 두 번째 조회까지의 시간은 26.016 - 25.963 = 0.053의 짧은 시간밖에 걸리지 않았습니다.
49,990,000 ~ 5,000,0000 조회#
1 | 2021-05-31 02:24:27.943 INFO 13475 --- [ main] uration$$EnhancerBySpringCGLIB$$4d92f8c5 : item size 1000 |
마지막 청크 사이즈 조회하는 시간은 25:18.092 - 24:27.943 대략 51초가 걸렸습니다. 즉 해당 리더는 초반 청크는 빠르지만 후반으로 갈수록 청크를 읽는 부분이 느려지며, 데이터가 많으면 많을수록 더 느려지는 것을 확인할 수 있습니다.
왜 후반 리드에서 느려지는 것일까?#
explain: 첫 청크#
1 | explain |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | payment0_ | NULL | range | IDXfxl3u00ue9kdoqelvslc1tj6h | IDXfxl3u00ue9kdoqelvslc1tj6h | 5 | NULL | 2306025 | 100 | Using index condition |
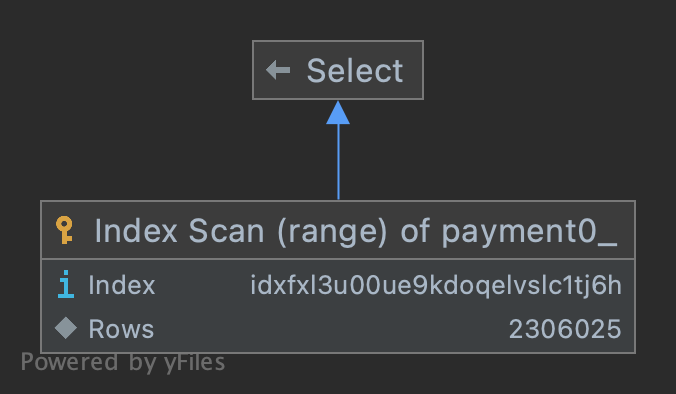
type: range인덱스 특정 범위의 행에 접근, 즉 인덱스가 제대로 동작possible_keys: IDXfxl3u00ue9kdoqelvslc1tj6h(created_at)이용 가능성 있는 인덱스의 목록key: IDXfxl3u00ue9kdoqelvslc1tj6h(created_at):possible_keys필드는 이용 가능성 있는 인덱스의 목록 중에서 실제로 옵티마이저가 선택한 인덱스의 keyrows: 2306025특정 rows을 찾기 위해 읽어야 하는 MySQL 예상 rows, 단 어디까지나 통계 값으로 계산한 값이므로 실제 rows 수와 반드시 일치하지 않는다.filtered: 100rows 데이터를 가져와 WHERE 구의 검색 조건이 적용되면 몇행이 남는지를 표시, 이 값도 통계 값 바탕으로 계산한 값이므로 현실의 값과 반드시 일치하지 않는다.Extra: Using index condition인덱스 컨디션 pushdown(ICP) 최적화가 진행(Using index와 비슷한 개념으로 인덱스에서만 접근해서 쿼티를 해결하는 것을 의미, 정확히 알고 있는 개념은 아니라서 Index Condition Pushdown Optimization참고)
해당 실행 계획을 정리하면 created_at 인덱스가 type: range로 제대로 동작했습니다. 하지만 rows: 2306025인 것을 봐서 상당히 많은 rows를 읽은 이후에 해당 rows를 찾는 거 같습니다. 대략 limit 2000000, 1000까지는 첫 청크 인덱스와 동일하게 type: range의 실행 계획을 가졌습니다.
explain: 마지막 청크#
1 | explain |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | payment0_ | NULL | ALL | IDXfxl3u00ue9kdoqelvslc1tj6h | NULL | NULL | NULL | 4612051 | 50 | Using where; Using filesort |
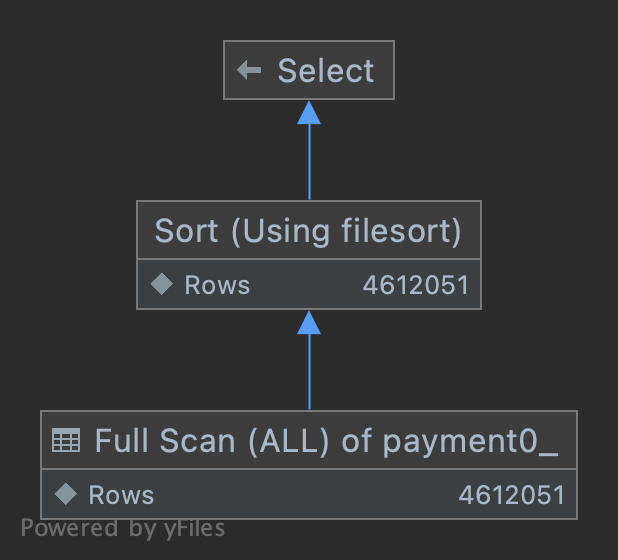
type: ALL풀 스캔, 테이블의 데이터 전체에 접근key: NULL:possible_keys필드를 이용하지 않음, 즉 인덱스 사용 안 함ExtraUsing where테이블에서 행을 가져온 후 추가적으로 검색 조건을 적용해 행의 범위를 축소Using filesortORDER BY 인덱스로 해결하지 못하고, filesort(MySQL의 quick sort)로 행을 정렬
특정 청크 이후부터는 index를 타지 못하고 풀 스캔이 진행되고 있습니다. 당연히 해당 쿼리는 느릴 수밖에 없습니다.
왜 후반 청크에서는 Full Scan을 하는 것일까?#
인덱스를 통해 테이블의 레코드를 읽는 것은 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 드는 작업입니다. 만약 100만 건의 레코드가 있다고 가정하고 그중 50만 건을 읽어야 하는 쿼리가 있다고 하면 테이블 전체를 읽어서 필요 없는 50만 건을 버리는 것이 효율적인지, 인덱스를 통해 필요한 50건만 읽어 오는 것이 효율적인지 옵티마이저는 판단해야 합니다. 일반적으로 DBMS의 옵티아미저에서 인덱스를 통해 레코드를 1건 읽는 것은 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 발생한다고 예측합니다. 즉, 인덱스를 통해 읽어야 할 레코드의 건수(옵티마이저가 예측한)가 전체 테이블의 20~25%를 넘어서면 인덱스를 이용하지 않고 직접 테이블을 모두 읽어서 필요한 레코드만 필터링하는 방식이 효율적이라고 판단하게 됩니다.
즉, 옵티마이저가 인덱스를 통한 비용 보다 테이블에서 직접 레코드를 읽는 것이 더 효율적이라고 판단하고 Full Scan을 진행한 것입니다.
정리#
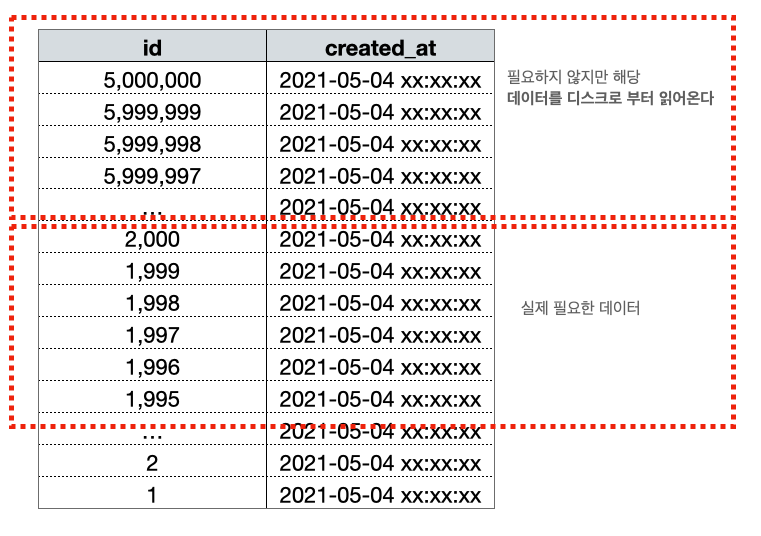
초반 청크에서는 WHERE 조건이 인덱스 칼럼만으로 처리(커버링 인덱스)가 진행돼서 그나마 빠르지만 후반 청크에서는 페이징 쿼리가 커버링 인덱스로 처리되지 못하게 되고 해당 데이터를 풀 스캔해서 디스크로부터 가져오기 때문에 후반 청크가 느려지게 됩니다.
QueryDslNoOffsetPagingReader#
QueryDslNoOffsetPagingReader는 Spring Batch QuerydslItemReader 오픈소스 코드로 자세한 내용은 기억보단 기록을: Spring Batch와 QuerydslItemReader에 정리되어 있습니다.
해당 내용을 간단하게 정리하면 다음과 같습니다.
where AND id < 마지막 조회 ID조건으로 균일할 리드 속도를 보장- 복잡한 정렬 기준이(group by, 집계 쿼리 등등) 있는 경우 사용 불가능
- 대량의 페이지 조회에 적합 (개인적으로 대략 5만 건 이상의 경우 사용이 적합하다고 생각합니다.)
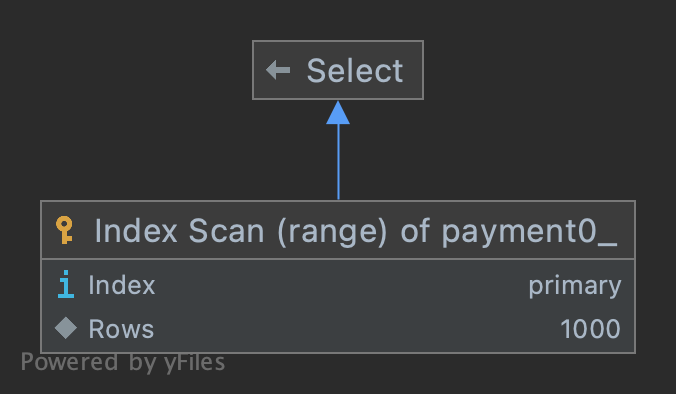
explain: 첫 청크#
1 | explain |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | payment0_ | NULL | range | PRIMARY,IDXfxl3u00ue9kdoqelvslc1tj6h | PRIMARY | 8 | NULL | 1000 | 50 | Using where |
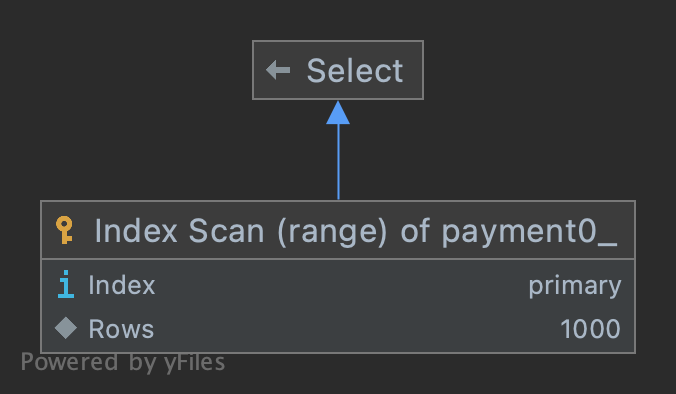
explain: 마지막 청크#
1 | explain |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | payment0_ | NULL | range | PRIMARY,IDXfxl3u00ue9kdoqelvslc1tj6h | PRIMARY | 8 | NULL | 1000 | 50 | Using where |
type: range인덱스 특정 범위의 행에 접근, 즉 인덱스가 제대로 동작possible_keys: PRIMARY, IDXfxl3u00ue9kdoqelvslc1tj6h(created_at)는id,created_at칼럼 인덱스로 사용 가능key: PRIMARY:possible_keys필드 중id를 인덱스로 사용, InnoDB 테이블에서는 기본적으로PRIMARY키를 기준으로 클러스터링 되어 저장되기 때문에 실행 계획에서PRIMARY키는 기본적으로 다른 보조인덱스에 비해 비중이 높게 설정된다.Extra: Using where테이블에서 행을 가져온 후 추가적으로 검색 조건을 적용해 행의 범위를 축소
첫 청크와 마지막 청크의 실행 계획이 동일한 것을 확인할 수 있습니다. 즉 해당 리더는 청크 사이즈, 데이터 총 rows와 별개로 조회 시간이 균일합니다.
다음편은 Spring Batch Reader 성능 분석 및 측정 part 2를 참고해주세요.