오늘날 서버 애플리케이션에서는 외부 API를 호출해 그 결과에 따라 데이터베이스의 상태를 갱신하는 작업이 빈번하게 발생합니다. 예를 들어, 주문 시스템에서는 주문을 진행하기 위해 내부 API를 호출하고, 해당 결과에 따라 주문의 상태를 ‘COMPLETED’ 또는 'FAILED’로 업데이트하게 됩니다. 단일 스레드로 이러한 작업을 수행하면 수천 건의 주문 처리 시 몇 분 혹은 그 이상의 시간이 소요될 수 있습니다.
Rx Kotlin을 활용하면, parallel()과 sequential() 연산자를 통해 여러 작업을 동시에 처리할 수 있어, 전체 처리 시간을 대폭 단축할 수 있습니다. 이 글에서는 주문 처리 시나리오를 통해, 단일 스레드 방식과 멀티 스레드(병렬) 방식의 차이와 그 성능 향상을 실제 코드 예제와 함께 자세히 살펴봅니다.
시나리오 가장 흔한 케이스로 외부 API를 호출하고 그 결과에 맞게 데이터베이스를 수정하는 방식입니다.
주문을 시스템 내부 API를 호출해서 진행한다.
내부 API 시스템 성공 여부에 따라 status를 지정한다.
Code Entity 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Entity @Table(name = "orders" ) class Order ( @Enumerated(EnumType.STRING) @Column(name = "status" , nullable = false) var status: OrderStatus ) { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) var id: Long ? = null override fun toString () return "Order(status=$status , id=$id )" } } enum class OrderStatus { READY, COMPLETED, FAILED }
엔티티 코드는 간단합니다. id, status를 가지고 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 class OrderHttpClient { fun doSomething (orderId: Long ) Boolean { runBlocking { delay(100 ) } val random = Random.nextInt(0 , 10 ) return 8 > random } }
HTTP 통신을 하는 Client 코드입니다. 성공과 실패를 리턴하는 간단한 코드입니다. 해당 코드를 호출하면 100ms 블록이 걸리게 설정했습니다.
Test 단일 스레드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Test fun `단일 스레드 작업`() val stopWatch = StopWatch() val orders = givenOrders(1_000 ) stopWatch.start() orders .forEach { val result = sampleApi.doSomething(it.id!!) when { result -> it.status = OrderStatus.COMPLETED else -> it.status = OrderStatus.FAILED } } stopWatch.stop() println(stopWatch.totalTimeSeconds) }
단일 스레드에서 5,000의 api를 호출하여 그 결과에 따라서 데이터베이스 상태를 업데이트하는 코드입니다.
멀티 스레드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @Test fun `멀티 스레드 작업`() val stopWatch = StopWatch() val orders = givenOrders(5_000 ) stopWatch.start() orders .toFlowable() .parallel() .runOn(Schedulers.io()) .map { println("Mapping orderId :${it.id} ${Thread.currentThread().name} " ) val result = sampleApi.doSomething(it.id!!) Pair(result, it) } .sequential() .subscribe( { println("Received orderId :${it.second.id} ${Thread.currentThread().name} " ) when { it.first -> it.second.status = OrderStatus.COMPLETED else -> it.second.status = OrderStatus.FAILED } }, { it.printStackTrace() }, { stopWatch.stop() println(stopWatch.totalTimeSeconds) } ) runBlocking { delay(5_000 ) } }
(1): order 데이터를 준비합니다.
(2): Back Pressure 기능을 제공하는 Flowable으로 생성 생성
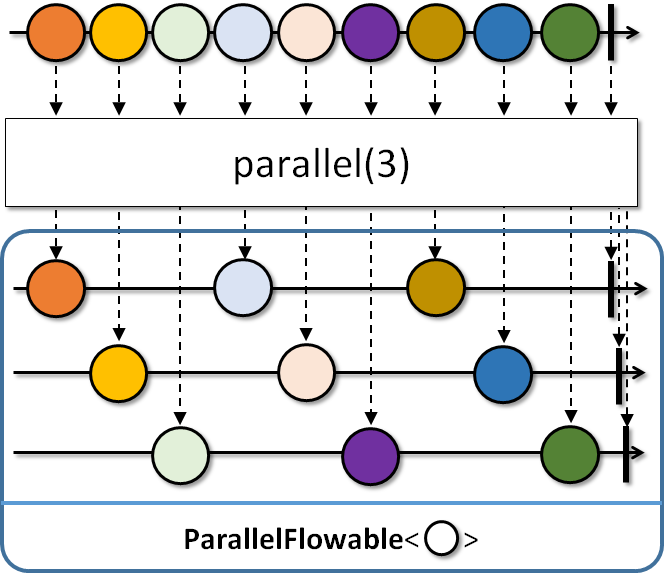
(3): CPU 수와 동일하게 ParallelFlowable을 생성할 수 있게 해줍니다.
(4): ParallelFlowable의 병렬 처리 수준만큼 Scheduler.createWorker를 호출해서 스레드를 생성합니다. Buffer size는 기본 설정 128개와 동일합니다.
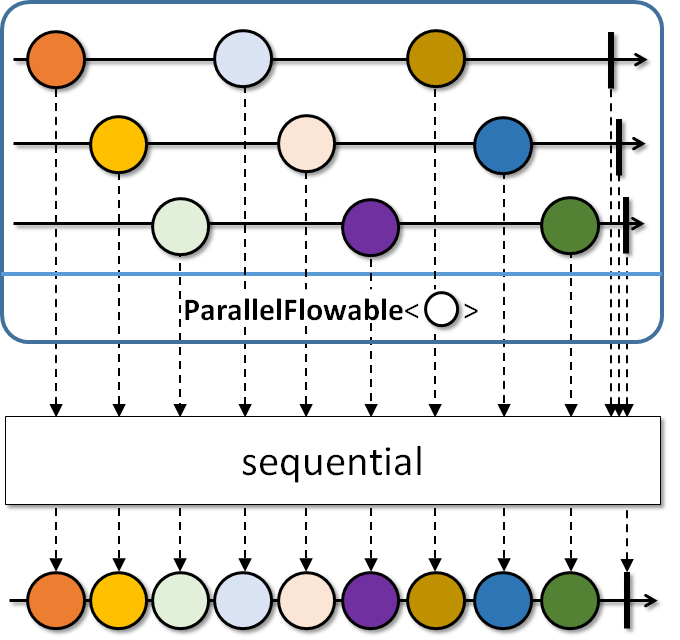
(5): 각 ParallelFlowable의 값을 병합 작업을 진행합니다.
(6): 해당 작업이 모두 테스트 스레드 Test worker에서 실행되지 않기 때문에 block을 진행합니다.
parallel
toFlowable() 메서드로 Flowable 처리를 진행했던 것을 parallel 처리하기 위해서 parallel() 메서드를 사용합니다. 해당 레일은 자체적으로 병렬로 실행되지 않으며 각 레일이 병렬로 실행하려면 runOn()메서드의 호출이 필요합니다. 이때 Schedulers.io()를 사용합니다. Schedulers.io()는 I/O 관련 작업을 수행할 수 있는 무제한의 워커 스레드를 생성하는 스레드를 제공한다. 해당 테스트 환경은 12 코어기 때문에 12 스레드를 사용하게 됩니다.
sequential
parallel메서 여러 레일을 생성하는 것을 다시 단일 스퀀스로 병합하기 위해서 사용합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ... Mapping orderId :15 RxCachedThreadScheduler-3 Mapping orderId :18 RxCachedThreadScheduler-6 Mapping orderId :22 RxCachedThreadScheduler-10 Received orderId :8 RxCachedThreadScheduler-8 Mapping orderId :16 RxCachedThreadScheduler-4 Received orderId :1 RxCachedThreadScheduler-8 Mapping orderId :23 RxCachedThreadScheduler-11 Received orderId :2 RxCachedThreadScheduler-8 Received orderId :3 RxCachedThreadScheduler-8 Received orderId :4 RxCachedThreadScheduler-8 Mapping orderId :14 RxCachedThreadScheduler-2 Received orderId :5 RxCachedThreadScheduler-8 Mapping orderId :24 RxCachedThreadScheduler-12 ...
Mapping, Received 스레드를 확인 1~12 스레드를 모두 사용하는 것을 확인할 수 있습니다. 해당 스레드는 모두 메인 스레드인 Test worker에서 진행되지 않습니다.
비교
rows
스레드
소요 시간
5,000
단일 스레드
8m 58s
5,000
12 스레드
43s
실행 환경의 CPU Core 수에 따라서 결과는 많이 달라집니다.