MongoDB Update 성능 측정 및 분석
MongoDB는 현대 웹 애플리케이션에서 널리 사용되는 NoSQL 데이터베이스입니다. 특히, Spring Data MongoDB는 Java 개발자에게 친숙하고 효율적인 방법으로 MongoDB와의 상호작용을 가능하게 합니다. 이번 포스팅에서는 Spring Data MongoDB를 사용하여 데이터를 업데이트하는 여러 방법의 성능을 비교하고 분석합니다. 특히, saveAll, updateFirst, bulkOps(UNORDERED), bulkOps(ORDERED) 이 네 가지 방법에 대해 깊이 있게 살펴보겠습니다.
Update Code#
Document#
1 |
|
이 코드는 Kotlin을 사용하여 MongoDB 문서에 대해 정의된 Member 클래스를 나타냅니다. 이 클래스에는 대략 11개의 필드가 정의되어 있으며, 테스트에 사용될 주요 필드는 name입니다. 이 Member 클래스는 Auditable 추상 클래스를 상속받아, MongoDB 문서의 생성 및 수정 시간을 자동으로 추적합니다. 테스트 과정에서는 name 필드만을 대상으로 업데이트 작업을 수행하고 성능을 평가할 예정입니다. 이를 통해 MongoDB에서 단일 필드 업데이트의 성능을 파악하고자 합니다.
saveAll#
1 | fun updateSaveAll(members: List<Member>) { |
saveAll 메서드는 Spring Data MongoDB의 CrudRepository 인터페이스에서 제공하는 메서드로, 여러 개의 문서를 데이터베이스에 저장하거나 업데이트하는 데 사용됩니다. 동작 방식은 다음과 같습니다.
- ID 존재 여부에 따른 동작:
saveAll메서드는 전달된Member객체 리스트를 순회하면서 각 객체의id필드를 확인합니다.
- ID가 없는 경우 (Insert):
Member객체에id필드가null이거나 존재하지 않으면, 해당 객체는 새로운 문서로 간주되어 데이터베이스에 삽입됩니다. - ID가 있는 경우 (Update): 이미
id필드가 있는Member객체는 해당id를 가진 기존 문서를 업데이트합니다.
- 일괄 처리: 여러 객체를 포함하는 리스트를 한 번에 데이터베이스에 저장하거나 업데이트할 수 있는 이점이 있습니다.
이번 테스트에서는 saveAll 메서드를 사용하여 Member 객체의 name 필드를 업데이트하는 데 집중합니다. 테스트에 사용되는 모든 Member 객체는 이미 id를 가지고 있으므로, 이 메서드는 모든 객체를 데이터베이스에 업데이트하는 작업으로 처리합니다. 이를 통해 saveAll 메서드가 대량의 업데이트 작업을 얼마나 효과적으로 처리할 수 있는지 성능을 평가하고자 합니다.
saveAll은 Spring Data MongoDB가 기본으로 제공하는 메서드이기 때문에 가장 쉽게 손이 가는 선택지입니다. 별도의 학습 없이 바로 사용할 수 있다는 것이 큰 장점입니다. 그러나 내부 동작을 들여다보면, 리스트를 순회하면서 문서 한 건마다 독립적인 DB I/O가 발생합니다. N건을 업데이트한다면 네트워크 왕복도 N회 일어난다는 뜻입니다. 또한 변경되지 않은 필드까지 문서 전체를 전송하기 때문에 payload 측면에서도 비효율적입니다. 소량의 단순 upsert에는 적합하지만, 대량 처리 시에는 “기본 제공이라 무심코 사용했다가” 성능 이슈를 만나는 대표적인 사례이므로 주의가 필요합니다.
updateFirst#
1 | fun updateFirst(id: ObjectId): UpdateResult { |
updateFirst 메서드는 Spring Data MongoDB의 MongoTemplate을 사용하여 특정 조건을 만족하는 첫 번째 문서를 업데이트하는 기능을 제공합니다. 이 메서드는 주어진 쿼리에 따라 데이터베이스 내에서 일치하는 첫 번째 문서를 찾아 해당 필드를 업데이트합니다. 동작 방식은 다음과 같습니다.
- **쿼리 매칭
**:updateFirst는Query객체를 사용하여 업데이트할 문서를 찾습니다. 이 예제에서는Criteria.where("_id").is(id)를 통해 특정id값을 가진 문서를 찾습니다. - 업데이트 내용 지정:
Update객체를 사용하여 업데이트할 내용을 지정합니다. 여기서는name필드를 새롭게 생성된 무작위 UUID 문자열로 설정합니다. - 첫 번째 일치 문서 업데이트: 쿼리에 일치하는 첫 번째 문서만 업데이트됩니다. 만약 일치하는 문서가 없으면 업데이트는 수행되지 않습니다.
- 결과 반환: 메서드는
UpdateResult를 반환하여 업데이트 작업의 결과를 나타냅니다. 이를 통해 몇 개의 문서가 영향을 받았는지 확인할 수 있습니다.
이번 테스트에서는 updateFirst 메서드를 사용하여 Member 클래스의 name 필드를 업데이트합니다. 테스트는 특정 id를 가진 Member 문서를 대상으로 하며, 이 메서드는 해당 문서의 name 필드를 새로운 값으로 업데이트합니다. 이 방법을 통해 updateFirst 메서드의 단일 문서 업데이트 성능을 평가하고자 합니다.
updateFirst는 변경할 필드만 명시적으로 지정할 수 있어 payload 면에서는 saveAll보다 효율적입니다. 하지만 DB I/O 메커니즘은 saveAll과 동일합니다. 호출 한 번이 곧 네트워크 왕복 한 번이므로, N건을 업데이트하려면 외부에서 루프를 돌며 N번 호출해야 합니다. 결과적으로 두 방식은 성능 특성상 같은 한계를 공유합니다. 또한 _id 외 다른 필드로 조회할 경우 인덱스 상태에 따라 매칭 비용이 추가되어 성능 차이가 더 벌어질 수 있습니다.
updateMulti#
1 | fun updateStatusBulk(targetIds: List<ObjectId>, status: MemberStatus): Long { |
updateMulti는 MongoTemplate에서 제공하는 메서드로, 조건에 매칭되는 여러 문서를 단일 쿼리 한 번으로 동일한 값으로 업데이트합니다. 동작 방식은 다음과 같습니다.
- 단일 쿼리로 다수 문서 업데이트:
updateFirst가 첫 번째 매칭 문서 하나만 업데이트하는 것과 달리,updateMulti는 조건에 해당하는 모든 문서를 한 번의 DB 호출로 처리합니다. - 동일한 값을 모든 대상에 적용: 이 메서드는 매칭된 모든 문서에 동일한
Update내용을 적용합니다. 따라서 업데이트하려는 값의 종류가 한정적인 시나리오에서 효과가 극대화됩니다.
updateMulti가 가장 빛을 발하는 사례는 회원 상태(정상/비정상) 처럼 값의 종류가 정해진 경우입니다. 100건의 회원 상태를 변경해야 한다고 가정하면, 대상 ID 목록을 정상과 비정상 두 그룹으로 나누어 updateMulti를 최대 2회 호출하면 됩니다. saveAll이나 updateFirst로 처리했다면 100회 발생했을 DB I/O가 최대 2회로 줄어들며, 이는 곧 성능의 획기적인 향상을 의미합니다.
단, updateMulti는 모든 대상 문서에 동일한 값을 써야 한다는 제약이 있습니다. 회원별 포인트 적립처럼 각 문서마다 set해야 하는 값이 다를 경우에는 이 메서드 하나로 처리할 수 없습니다. 이런 케이스가 바로 다음에 소개하는 bulkOps가 필요한 이유입니다.
bulkOps#
1 | fun updateBulk( |
bulkOps 메서드는 Spring Data MongoDB의 MongoTemplate을 사용하여 대량의 업데이트 작업을 효율적으로 처리하는 방법을 제공합니다. bulkOps는 한 번의 연산으로 여러 업데이트 작업을 모아서 실행할 수 있으며, BulkMode에 따라 순서대로(ORDERED) 또는 순서에 구애받지 않고(UNORDERED) 실행할 수 있습니다. 동작 방식은 다음과 같습니다.
- Bulk Operations 설정:
bulkOps는 주어진BulkMode와 문서 클래스(Member::class.java)를 기반으로 초기화됩니다. - 업데이트 작업 추가:
updateOne메서드를 사용하여 각id에 대한 업데이트 작업을 추가합니다. 여기서는name필드를 새로운 무작위 UUID 문자열로 설정합니다. - Bulk 작업 실행:
execute메서드를 호출하여 누적된 모든 업데이트 작업을 한 번에 실행합니다. - 결과 반환: 메서드는
BulkWriteResult를 반환하여 대량 업데이트 작업의 결과를 나타냅니다.
이번 테스트에서는 bulkOps 메서드를 사용하여 Member 클래스의 name 필드를 대량으로 업데이트합니다. 여러 id를 가진 Member 문서에 대해 각각 name 필드를 새로운 값으로 업데이트하는 작업을 모아 한 번에 실행합니다. 이 방법을 통해 bulkOps 메서드의 대량 업데이트 성능과 UNORDERED와 ORDERED 모드 간의 성능 차이를 평가하고자 합니다.
bulkOps의 핵심도 updateMulti와 마찬가지로 DB I/O 횟수를 줄이는 것이지만, 접근 방식이 다릅니다. 회원별 포인트 적립처럼 각 문서마다 다른 값을 set해야 하는 경우, updateMulti 한 번으로는 묶을 수 없어 결국 N회 I/O가 발생합니다. bulkOps는 update 명령들을 클라이언트 측 버퍼에 누적하다가 execute() 시점에 한 번의 네트워크 왕복으로 묶어 전송합니다. 즉, 각기 다른 값을 N건 업데이트하더라도 실제 DB로 나가는 네트워크 I/O는 1회에 수렴합니다.
정리하면 두 메서드의 차이는 다음과 같습니다.
- 동일한 값을 다수 문서에 적용 →
updateMulti: 조건 쿼리만으로 한 번에 처리 - 문서마다 다른 값을 적용 →
bulkOps: 각 update 명령을 버퍼에 쌓고execute()시점에 일괄 전송
BulkMode 차이점:#
BulkOperations.BulkMode.UNORDERED:- 작업들이 순서에 구애받지 않고 병렬적으로 처리됩니다.
- 성능 측면에서 더 효율적일 수 있으나, 하나의 작업 실패가 다른 작업에 영향을 미치지 않습니다.
- 대량의 독립적인 작업을 빠르게 처리해야 할 때 유용합니다.
BulkOperations.BulkMode.ORDERED:- 작업들이 추가된 순서대로 처리됩니다.
- 하나의 작업이 실패하면 그 이후의 작업은 실행되지 않을 수 있습니다.
- 작업들 간의 순서가 중요한 경우에 적합합니다.
성능 측정 결과#
성능 테스트는 saveAll, updateFirst, bulkOps(UNORDERED), bulkOps(ORDERED) 세 가지(+ 두 가지 BulkMode)를 대상으로 진행했습니다. updateMulti는 이번 벤치마크에서 의도적으로 제외했는데, 그 이유는 두 가지입니다. 첫째, updateMulti는 단일 쿼리 한 번으로 다수 문서를 처리하므로 N 값에 관계없이 사실상 상수에 가까운 처리 시간을 보입니다. 이를 “행 수에 따른 시간 변화”를 측정하는 다른 방식들과 같은 축에 놓으면 비교 자체가 의미를 잃습니다. 둘째, updateMulti는 모든 대상에 동일한 값을 적용하는 시나리오에만 사용 가능하므로, 각 문서마다 다른 값을 set하는 이번 워크로드와 동일한 조건으로 테스트를 재현할 수 없습니다. 따라서 아래 표는 “문서마다 서로 다른 값을 set하는 워크로드”에서 나머지 세 방식을 비교한 결과입니다.
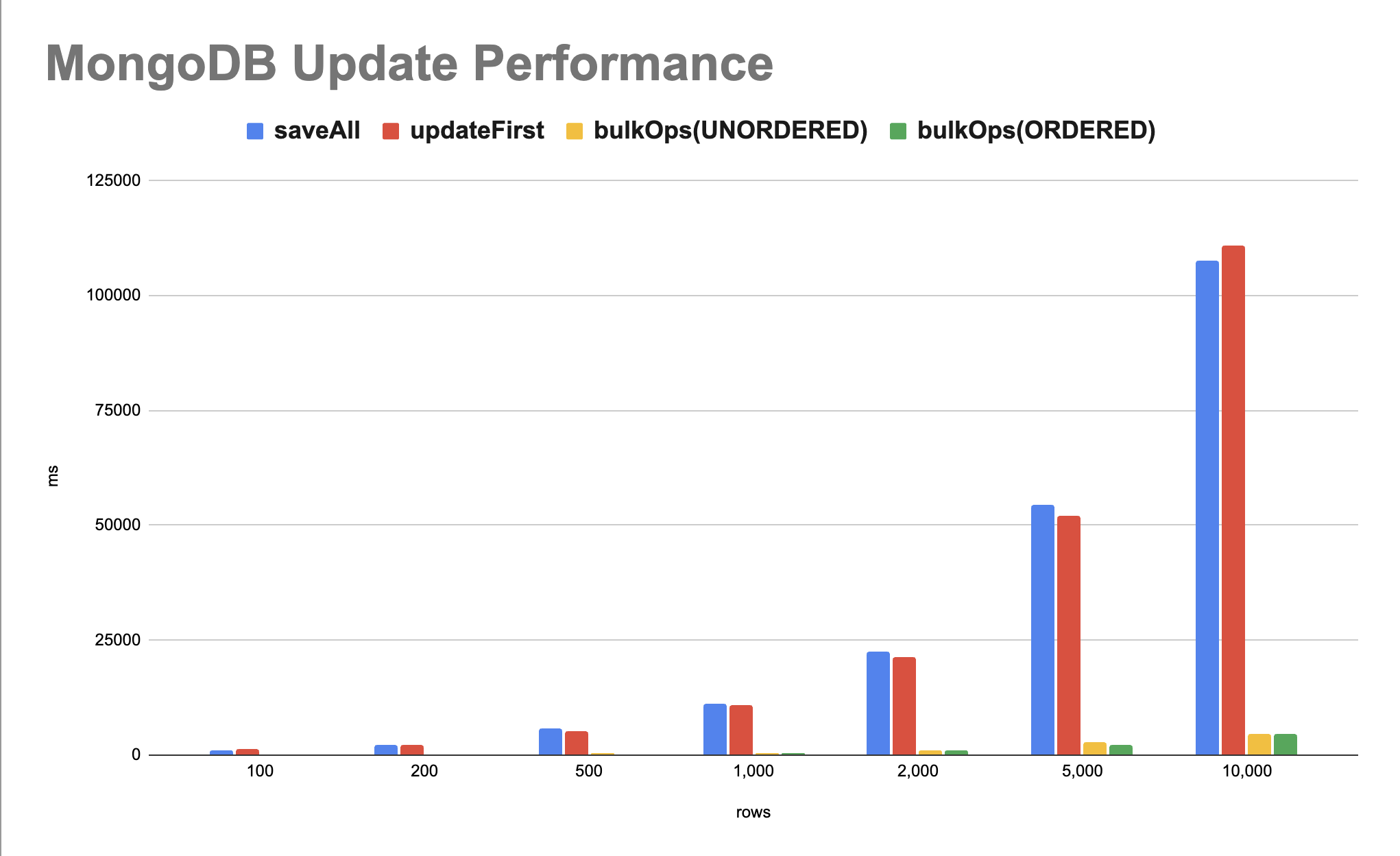
| rows | saveAll | updateFirst | bulkOps(UNORDERED) | bulkOps(ORDERED) |
|---|---|---|---|---|
| 100 | 1,052 ms | 1,176 ms | 46 ms | 79 ms |
| 200 | 2,304 ms | 2,196 ms | 103 ms | 124 ms |
| 500 | 5,658 ms | 5,250 ms | 309 ms | 257 ms |
| 1,000 | 11,106 ms | 10,846 ms | 418 ms | 412 ms |
| 2,000 | 22,592 ms | 21,427 ms | 1,060 ms | 1,004 ms |
| 5,000 | 54,407 ms | 52,075 ms | 2,663 ms | 2,292 ms |
| 10,000 | 107,651 ms | 110,884 ms | 4,514 ms | 4,496 ms |
결과는 saveAll, updateFirst, bulkOps(UNORDERED), bulkOps(ORDERED) 세 가지 방법에 대해 다양한 행(rows) 수에 따라 수행 시간(밀리초)을 비교합니다.
분석 결과:#
saveAll과updateFirst:
- 이 두 방법은 유사한 성능을 보입니다. 행의 수가 증가함에 따라 수행 시간이 선형적으로 증가하는 경향을 보이며, 대량의 데이터를 처리할 때 상대적으로 높은 지연 시간을 가집니다.
saveAll과updateFirst메서드의 성능 차이는 유의미하지 않습니다. 따라서, 상대적으로 데이터 양이 적은 경우에는 upsert 기능을 제공하는saveAll을 사용하여 로직을 단순화할 수 있습니다.- 예제 코드에서는
updateFirst메서드를 사용하여 기본 키(PK)를 기반으로 업데이트를 수행했습니다. 그러나 다른 키 값으로 조회를 진행할 경우, 조회 속도가 느려져 성능 차이가 발생할 수 있습니다. saveAll메서드는Member객체의 모든 변경 사항을 반영합니다. 따라서, 특정 필드만을 명확하게 업데이트하고자 할 때는updateFirst와 같은 메서드를 사용하여 정확한 업데이트 쿼리를 작성하는 것이 좋은 대안이 될 수 있습니다. 이 방법은 업데이트하고자 하는 필드를 직접 지정할 수 있어, 더 세밀한 데이터 업데이트 제어가 가능합니다.
bulkOps(UNORDERED)와bulkOps(ORDERED):
- 이 방법들은
saveAll과updateFirst에 비해 현저히 빠른 성능을 보입니다. 특히bulkOps(UNORDERED)는 가장 빠른 처리 시간을 나타냅니다. bulkOps(UNORDERED)는 순서에 구애받지 않고 여러 작업을 동시에 처리할 수 있기 때문에, 대량의 데이터 처리에 더 효율적이며, 개별 작업들이 독립적으로 처리됩니다. 이는 특정 작업이 실패해도 다른 작업들에 영향을 주지 않는다는 것을 의미합니다.bulkOps(ORDERED)도 비교적 빠른 성능을 보이지만,bulkOps(UNORDERED)에 비해 약간 느린 경향이 있습니다. 이는 작업을 순서대로 처리해야 하는 부가적인 비용 때문 이며, 순차적으로 작업이 진행되기 때문에 한 작업이 실패하면 그 이후의 작업은 실행되지 않을 수 있습니다.bulkOps(UNORDERED)와bulkOps(ORDERED)방식은 10,000개의 데이터 모수까지는 큰 성능 차이가 나타나지 않았습니다. 그러나 데이터가 많은 노드에 분산되어 저장된 경우, 이 두 방식 사이에서 더 유의미한 성능 차이가 발생할 수 있습니다. 분산 환경에서는 데이터의 위치와 네트워크 지연이 성능에 영향을 미칠 수 있으며, 이러한 조건에서는bulkOps(UNORDERED)와bulkOps(ORDERED)의 처리 방식 차이가 더 명확하게 드러날 가능성이 있습니다.
결론#
- 소량의 데이터를 업데이트할 때는
saveAll과updateFirst메서드가 적합할 수 있습니다. 하지만 데이터 양이 많아질수록 이 두 방법의 성능은 상대적으로 감소합니다. 데이터 모수가 적은 경우,saveAll과updateFirst각각의 장단점이 있으므로, 특정 환경과 요구사항에 맞게 적절한 메서드를 선택하는 것이 중요합니다. - 대량의 데이터 처리에는
bulkOps메서드 사용이 효율적입니다.bulkOps(UNORDERED)와bulkOps(ORDERED)각각의 장단점이 존재하므로, 이 두 방식 중에서는 특정 환경과 요구사항에 맞게 적절한 옵션을 선택하는 것이 중요합니다.
이번 결과에서 얻을 수 있는 가장 중요한 인사이트는, 복잡한 병렬 처리나 멀티스레드 같은 기법 없이 네트워크 I/O를 모아서 보내는 것만으로도 성능 향상의 폭이 매우 크다는 점입니다. bulkOps가 saveAll · updateFirst 대비 10,000건 기준으로 약 24배 빠른 이유는 알고리즘이 우월해서가 아니라, 단순히 네트워크 왕복 횟수를 N회에서 1회로 줄였기 때문입니다.
성능 최적화에는 단계가 있습니다. 직관적이고 유지보수가 쉬운 방법부터 순서대로 적용해보고, 그래도 부족하다면 다음 단계로 넘어가는 접근이 디버깅·운영 비용을 포함한 총비용을 가장 낮춥니다.
- 데이터 양이 적고 단순한 경우 →
saveAll/updateFirst로 충분, 코드 단순성을 우선 - 같은 값을 다수 문서에 일괄 적용하는 경우 →
updateMulti로 I/O를 “유니크한 값 수”로 수렴 - 문서마다 다른 값을 적용해야 하는 경우 →
bulkOps로 I/O를 1회로 수렴 - 위 방법으로도 성능이 부족한 경우 → 그제야 청크 분할, 비동기/병렬 처리, 샤딩 키 설계 등 다음 단계로 진입
복잡한 기법일수록 코드 가독성이 떨어지고 운영 중 문제 발생 시 추적이 어렵습니다. 동기적이고 직관적인 방향으로 성능 개선의 여지가 있는지 먼저 확인하고, 그 이후에도 더 끌어올려야 한다면 적절한 다음 방법을 찾는 것이 바람직합니다.
bulkOps 편의 기능 제공#
이전 포스팅인 Spring Data MongoDB Repository 확장에서는 MongoCustomRepositorySupport를 사용해 MongoRepository에 편의 기능을 추가하고, 보일러플레이트 코드를 줄이는 방법을 소개했습니다. 이 방법은 코드의 재사용성을 높이는 효과가 있습니다. 마찬가지로, bulkOps와 updateMulti 같은 반복적인 코드도 MongoCustomRepositorySupport에 통합하면 각 Repository마다 같은 초기화 로직을 중복 작성할 필요가 없어집니다.
bulkOps를 직접 사용할 때마다 반복되는 패턴을 생각해보면, 매번 mongoTemplate.bulkOps(bulkMode, documentClass)로 초기화하고, 루프를 돌며 updateOne으로 작업을 추가한 뒤, 마지막에 execute()를 호출하는 세 단계가 항상 고정적입니다. 이 보일러플레이트를 추상 클래스에 한 번만 구현해두면, 각 Repository 구현체는 핵심 비즈니스 로직인 Query와 Update 조합만 정의하면 됩니다.
MongoCustomRepositorySupport을 통한 bulkOps 기능 제공#
1 | abstract class MongoCustomRepositorySupport<T>( |
bulkUpdate는 Pair<() -> Query, () -> Update> 형태의 람다 리스트를 받습니다. Query와 Update를 즉시 생성하지 않고 람다로 감싸는 이유는, 리스트를 조립하는 시점과 실제로 쿼리가 필요한 시점을 분리하기 위해서입니다. 호출 측은 어떤 조건으로 어떤 필드를 업데이트할지에만 집중하면 되고, 실제 객체 생성은 bulkUpdate 내부에서 invoke() 시점에 일어납니다.
updateMany는 updateMulti를 감싸는 래퍼로, 동일한 값을 다수 문서에 일괄 적용하는 시나리오에서 사용합니다. bulkUpdate와 함께 추상 클래스에 포함시켜두면, 어느 Repository든 상속만으로 두 메서드를 모두 활용할 수 있습니다.
Repository 구현체에서의 활용#
1 | class MemberCustomRepositoryImpl(mongoTemplate: MongoTemplate) : |
두 메서드를 나란히 놓고 보면 앞서 설명한 선택 기준이 코드 수준에서도 명확하게 드러납니다. updatePoints는 회원마다 적립 포인트가 다르기 때문에 bulkUpdate로 각 update 명령을 버퍼에 쌓아 한 번에 전송하고, deactivateMembers는 모든 대상에 동일한 INACTIVE 상태를 적용하므로 updateMany로 단일 쿼리 한 번에 처리합니다. 두 경우 모두 MongoCustomRepositorySupport가 내부 구현을 캡슐화하고 있어, Repository 구현체는 비즈니스 의도를 명확하게 표현하는 코드만 남습니다.