데이터 저장소에 값을 저장하는 경우, 저장된 데이터를 가져오는 경우 적절하게 컨버팅이 필요한 경우 JPA에서는 @Converter를 사용하면 손쉽게 제어할 수 있습니다. Exposed에서는 VarCharColumnType를 확장하는 방식으로 해당 기능을 사용할 수 있습니다.
1 2 3 4 5 6
object Writers : LongIdTable("writer") { val name = varchar("name", 150).nullable() val email = varchar("email", 150) val createdAt = datetime("created_at").clientDefault { LocalDateTime.now() } val updatedAt = datetime("updated_at").clientDefault { LocalDateTime.now() } }
title 필드에 불필요한 공백을 제거하고 싶은 Converter를 사용하고 싶은 경우에는 VarCharColumnType를 확장하여 구현이 가능합니다.
overridefunvalueFromDB(value: Any): String { returnwhen (value) { is String -> value.trim() else -> throw IllegalArgumentException("${value::class.java.typeName} 타입은 Exposed 기반 컨버터에서 지원하지 않습니다.") } } }
title 칼럼은 varchar 타입이므로 VarCharColumnType을 통해서 구현합니다. valueToDB에는 데이터 저장소에 들어가는 컨버팅 로직을, valueFromDB에는 반대로 데이터베이스에서 가져온 데이터에 대한 컨버팅 로직을 작성합니다. 해당 로직은 공백을 제거하는 로직이므로 trim()을 사용해서 동일하게 구현합니다. 해당 코드는 String 자료형에만 동작하게 구성했으며 필요에 따라 추가적인 자료형을 추가하면 됩니다.
1 2 3 4 5 6 7 8 9
object Writers : LongIdTable("writer") { val name = registerColumn<String>( name = "name", type = TrimmingWhitespaceConverterColumnType(length = 150) ).nullable() val email = varchar("email", 150) val createdAt = datetime("created_at").clientDefault { LocalDateTime.now() } val updatedAt = datetime("updated_at").clientDefault { LocalDateTime.now() } }
registerColumn을 활용해서 Converter 코드 TrimmingWhitespaceConverterColumnType을 적용시킵니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
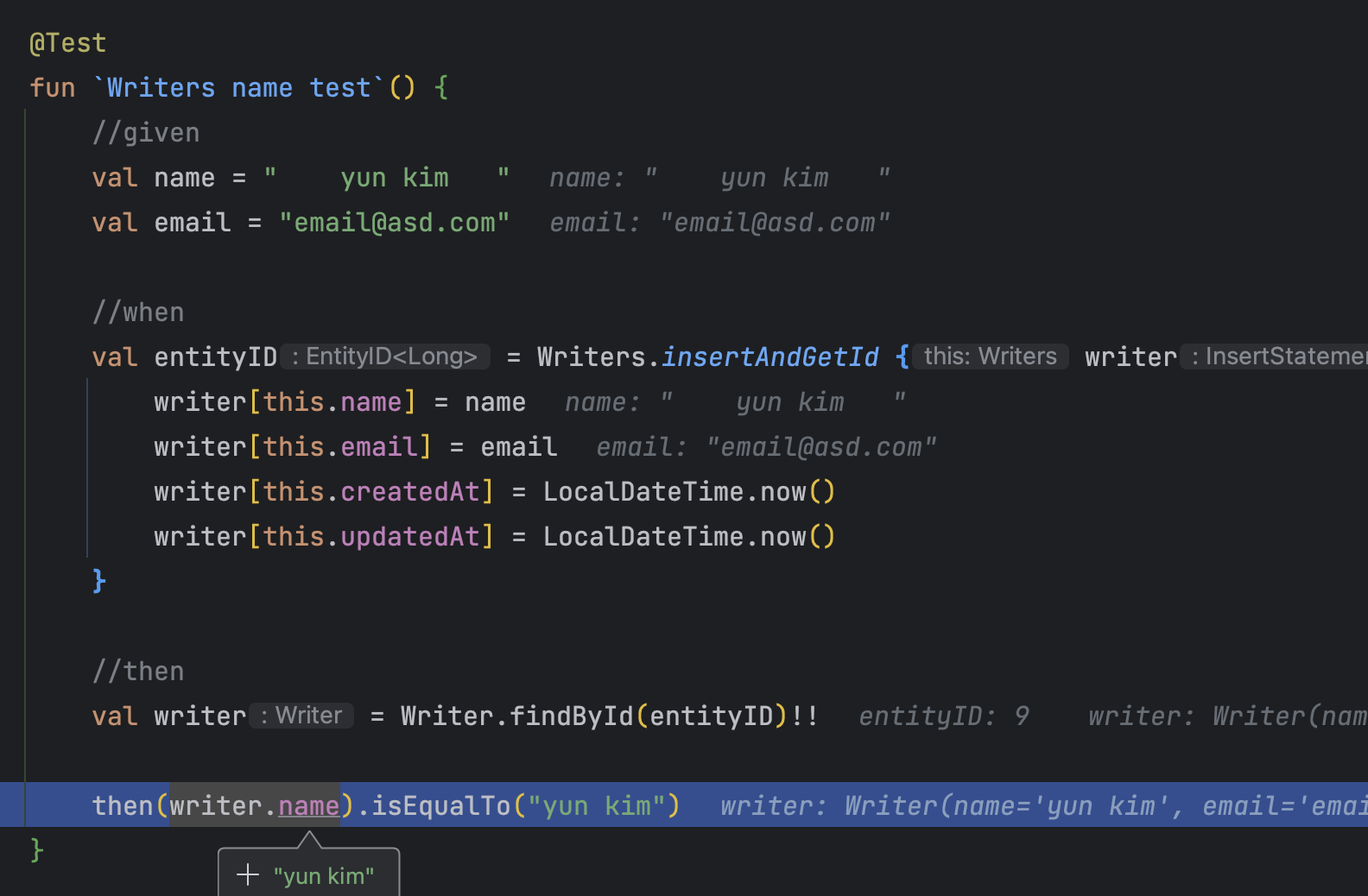
@Test fun `Writers name test`() { //given val name = " yun kim " val email = "email@asd.com"
//when val entityID = Writers.insertAndGetId { writer -> writer[this.name] = name writer[this.email] = email writer[this.createdAt] = LocalDateTime.now() writer[this.updatedAt] = LocalDateTime.now() } //then val writer = Writer.findById(entityID)!!
then(writer.name).isEqualTo("yun kim") }
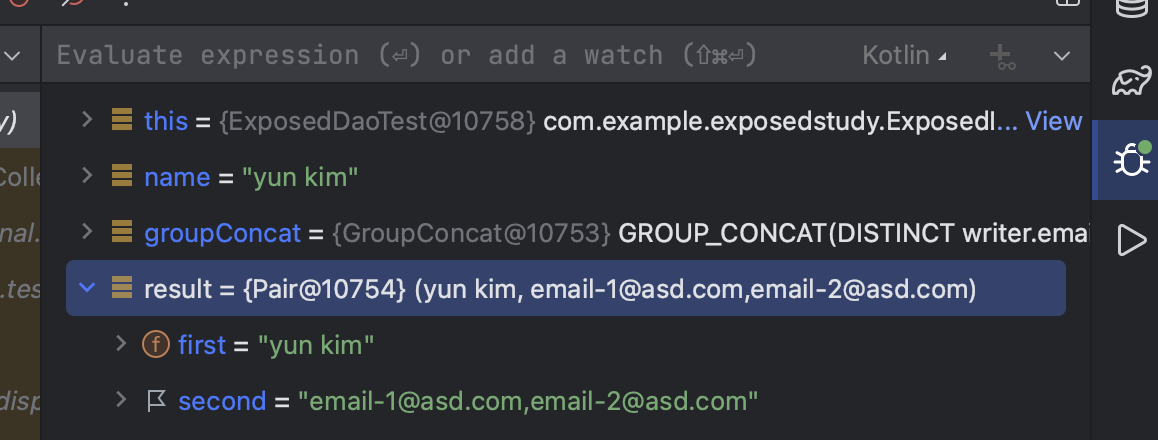
앞뒤 공백이 있는 문자열에 대해서 실제 데이터베이스에 정상적으로 Converter 로직이 동작하는지 테스트를 진행해 보겠습니다. 실제 디버깅으로 확인해 보겠습니다.
@Test fun `groupConcat`() { //given val name = "yun kim" Writers.batchInsert((1..2)) { this[Writers.name] = name this[Writers.email] = "email-${it}@asd.com" }
//when val groupConcat = Writers.email.groupConcat(distinct = true) val result = Writers .slice( groupConcat, Writers.name, ) .select { Writers.name eq name } .map { Pair( it[Writers.name], it[groupConcat] ) } .first()