Spring Batch 업데이트 성능 최적화 및 분석
아래와 같은 시나리오의 경우 배치 애플리케이션 성능을 높이기 위한 방법에 대한 내용을 정리했습니다.
시나리오#
해당 배치 애플리케이션은 등록되어 있는 가맹점(Store)에 대한 상태를 외부 API를 단건으로 조회하여(단건 API만 존재) 가맹점 상태를 OPEN("오픈"),, CLOSE("폐업"), 업데이트하는 애플리케이션입니다.
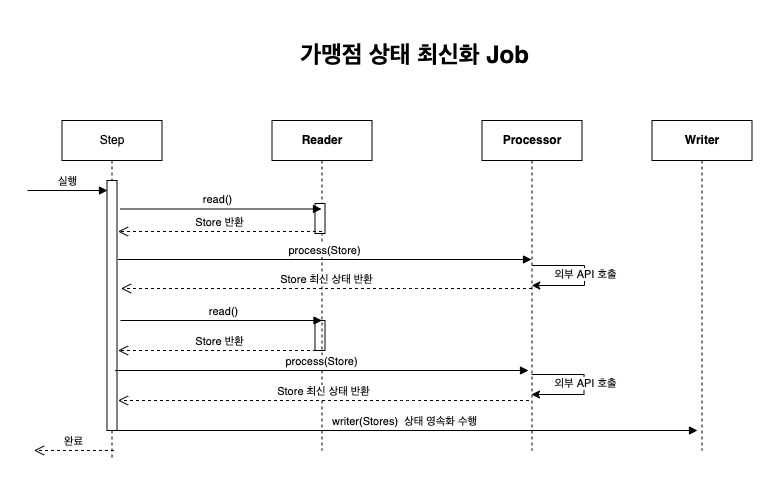
- Reader에서 Store(Item)을 ChunkSize 만큼 읽어 옵니다.
- 읽어온 Store(Item)을 한 건씩 Processor에서 외부 API를 호출하여 최신 가맹점 상태를 응답받아 가공 처리합니다.
- 가공된 데이터를 Chunk 단위만큼 쌓이면 Writer에 전달하고 Writer는 업데이트 작업을 진행합니다.
위와 같은 Step의 Job이 있는 경우 단일 스레드 기반의 가장 직관적인 JpaWriter 방법, RxKotlin을 이용한 멀티 스레드 방식의 RxWriter, 마지막으로 RxKotlin과 BulkUpdate를 진행하는 RxAndBulkWriter 방식에 대한 Step 코드 샘플과, 실제 성능 측정 정리 하였습니다.
Batch Code#
Entity & 외부 API#
1 |
|
초기 데이터는 모두 EXAMINATION("검토중")으로 들어갑니다.
1 |
|
이 외부 API는 평균 응답 속도는 150ms라고 가정하고 하고 성능 측정 시에는 150ms으로 고정하고 진행하겠습니다.
Reader#
1 |
|
JpaCursorItemReader 기반으로 성능 측정에서 모드 동일한 리더를 사용했습니다. JPA를 사용한다면 배치 애플리케이션에는 대량 처리 시 Entity 객체를 리턴하는 것이 아니라 Projections 객체를 리턴하는 것을 권장합니다. JPA에서 지원해 주는 Dirty Checking 기반으로 업데이트를 진행할 이는 거의 없으며, 있더라도 merger 기능이 동작할 때 select 쿼리가 한 번 더 발생할 위험도 있으며 Lazy Loading으로 추가 조회를 하는 경우도 거의 없습니다. 무엇보다도 처리할 데이터 rows가 많고 해당 테이블에 칼럼이 맞은 경우 JPA에서 이전에 언급한 기능들 및 다른 기타 기능들을 사용하기 위해서 더 많은 메모리를 사용하게 되기 때문에 성능적인 측면에 유의미한 차이가 있어 가능하면 Projections 객체를 리턴하는 것이 좋습니다.
CursorItemReader와 Reader에 대한 성능 분석은 Spring Batch Reader 성능 분석 및 측정 part 1, Spring Batch Reader 성능 분석 및 측정 part 2를 참고해 주세요. 본 포스팅에서는 Reader에 대해서는 깊게 다루지 않겠습니다.
단건 처리 Processor, Writer#
1 |
|
가장 일반적이고 직관적인 배치 흐름입니다. Processor에서 단건 조회 API를 조회하여 데이터를 가공하고 Writer에서 Query DSL 기반으로 업데이트를 진행합니다. 이렇게 처리하면 total rows * 150ms만큼 소요 시 간이 발생하게 되기 때문에 데이터 모수에 큰 영향을 받습니다.
Rx 기반 멀티 스레드 Writer 처리#
total rows * 150ms만큼 소요되기 때문에 처리할 수 있는 스레드 수만큼 작업 시간이 줄어들며 이론 상 rows 1,000 * 150ms / 10 Thread(Parallel(10)) 만큼 처리 시간을 단축시킬 수 있습니다. 해당 포스팅은 RxKotlin 기반으로 스레드 처리를 진행합니다.
1 |
|
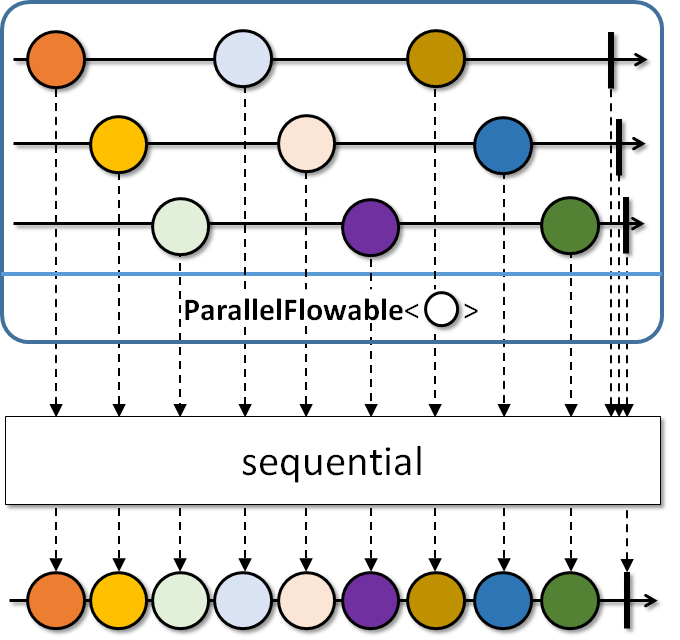
- (1): stores를 병렬화하여 위 이미지처럼 레일을 만들며 레일에게 발송할 수 있게 합니다.
- (2): Schedulers.io()를 통해서 ParallelFlowable의 병렬 처리 수준만큼 Scheduler.createWorker를 호출해서 스레드를 생성합니다.
- (3): sequential를 통해서 parallel에서 여러 레일을 생성하는 것을 다시 단일 시퀀스로 병합합니다.
- (4): 해당 레일이 정상 종료, 오류가 발생하기 전까지 Blocking 합니다.
- (5): 단일 시퀀스로 병합이 완료되고 Query DSL 기반으로 업데이트를 진행합니다.
Writer에서 넘겨받은 stores 객체를 병렬 처리하기 때문에 더 이상 Proccsor가 필요하지 않습니다. 배치 애플리케이션에서 Proccsor에서 데이터 가공 처리하는 것은 역할 책임의 분리로는 적절하나 I/O 작업처럼 상대적으로 느린 작업이 있으면 Proccsor에서 처리하지 않고 가능하면 Writer에서 벌크(병렬) 처리하는 것이 성능적으로 큰 이점이 있습니다.
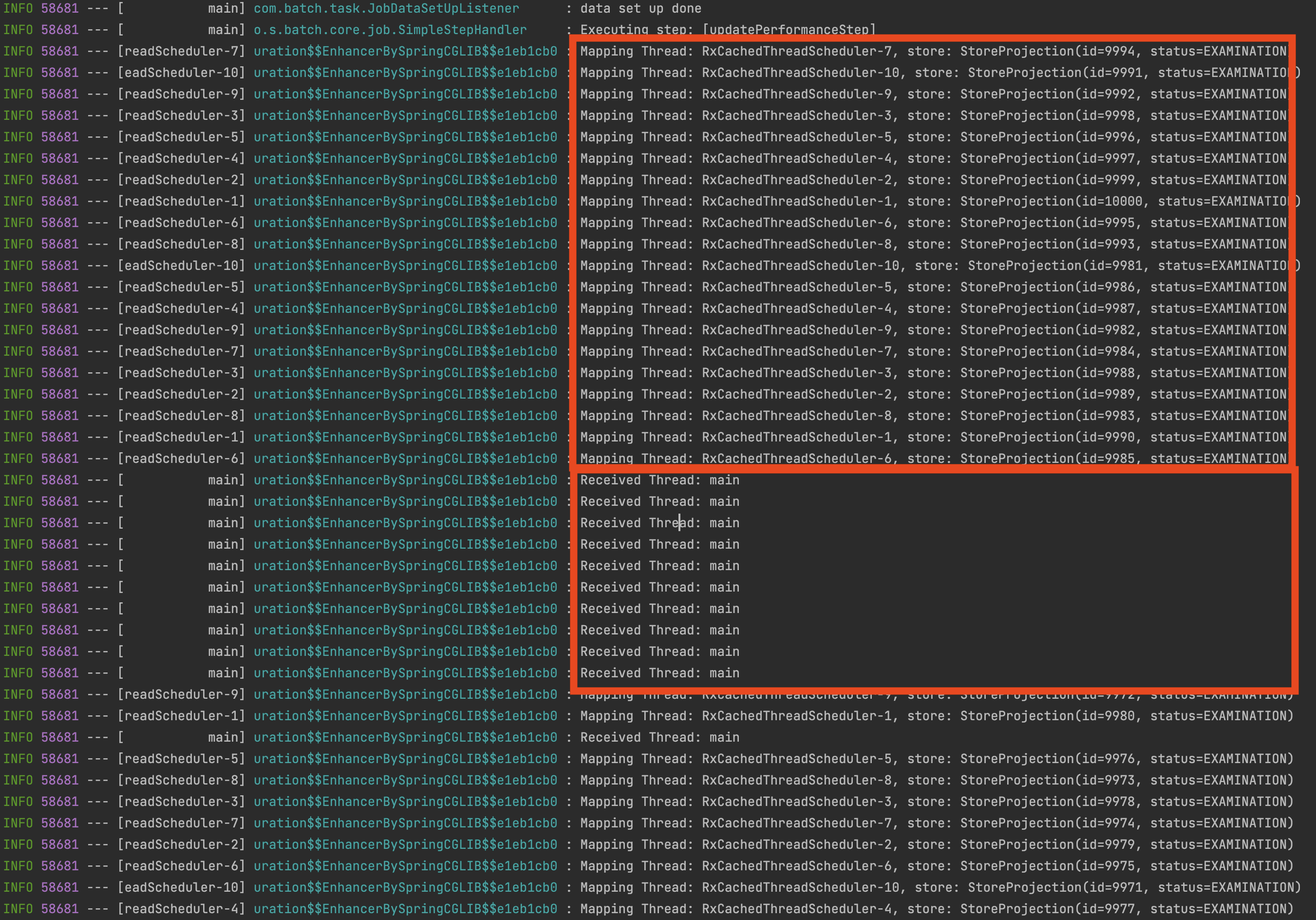
RxCachedThreadScheduler-1~10으로 10개의 스레드로 데이터를 사업자 최산 상태 조회를 하고 있으며 이후 blockingSubscribe의 onNext는 메인 스레드로 다시 전달받는 것을 확인할 수 있습니다. runOn()에 각자 환경에 맞는 Schedulers를 적절하게 사용하면 되며 모든 테스트는 10개의 스케줄러 스레드 기반으로 테스트를 진행했습니다.
Rx 기반 멀티 스레드 & Bulk Update Writer 처리#
1 |
|
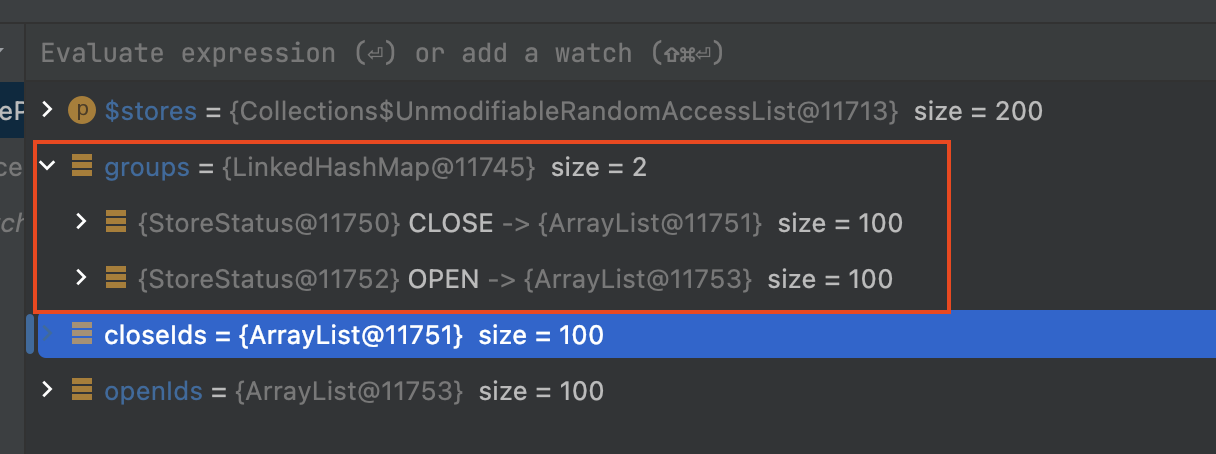
- (1): 단일 시퀀스로 병합된 stores를 StoreStatus 값으로 그룹화 진행
- (2):
OPEN("오픈"),,CLOSE("폐업"),기반으로 ids 객체 생성 - (3): ids 객체 기반으로 업데이트 진행
- (4): Query DSL
where id in기반으로 일괄 업데이트, 디비 서버와 네트워크 I/O 최소화

onComplete으로 최종 결과를 main Thread로 받는 것을 확인했습니다.
이전 Rx과 거의 동일하며 Query DSL 업데이트 처리하는 방식만 달라졌습니다. Chunk 단위로 데이터를 모아서 가맹점 상태를 기준으로 그룹화를 진행하며, 그룹화를 통해서 ids 통해서 DB 업데이트를 진행합니다. Chunk 단위로는 DB 서버와 최대 2번의 통신을 하기 때문에 기존 방식 대비 네트워크 I/O가 크게 줄어들게 됩니다. 모든 테스트는 로컬 DB 서버와 통신을 했기 때문에 JpaWriter, RxWriter 방식에서 네트워크 I/O에 비용이 크게 발생하지 않았지만 실제 운영 환경에서는 네트워크 I/O 비용이 커짐에 따라 더 안 좋은 성능을 보여주게 되며, RxAndBulkWriter와의 차이는 더 발생할 것으로 보입니다.
1 | # |
Performance 측정 및 분석#
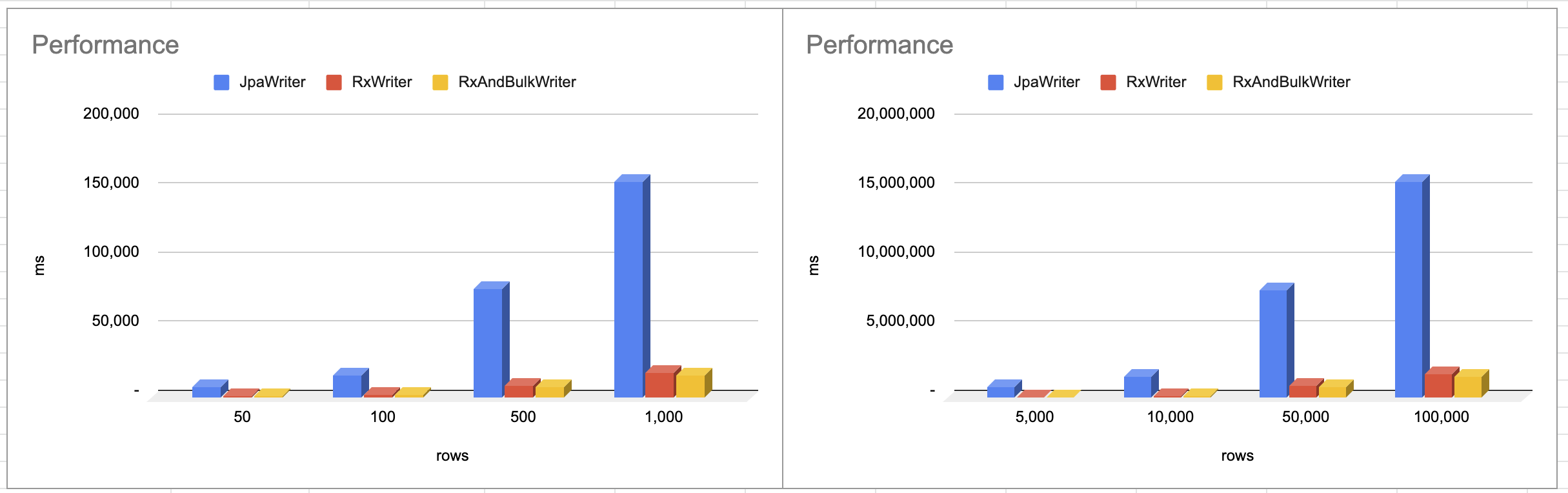
| Rows | ChunkSize | JpaWriter | RxWriter | RxAndBulkWriter |
|---|---|---|---|---|
| 50 | 10 | 8,252 ms | 1,406 ms | 1,258 ms |
| 100 | 20 | 16,207 ms | 2,357 ms | 2,078 ms |
| 500 | 100 | 78,738 ms | 9,106 ms | 8,268 ms |
| 1,000 | 200 | 156,420 ms | 17,751 ms | 1,6001 ms |
| 5,000 | 1,000 | 776,786 ms(12 min) | 83,670 ms(1.3 min) | 77,732 ms(1.2 min) |
| 10,000 | 1,000 | 1,556,775 ms(25 min) | 169,473 ms(2.8 min) | 155,777 ms(2.5 min) |
| 50,000 | 1,000 | 7,781,424 ms(129 min) | 881,320 ms(14 min) | 774,789 ms(12 min) |
| 100,000 | 1,000 | 15,622,542 ms(260 min) | 1,699,994 ms(28 min) | 1,581,545 ms(26 min) |
JpaWriter는 단일 스레드, RxWriter는 10 스레드로 진행하여 대략적인 수치는 스레드 차이만큼의 결과를 보여주는 것을 확인할 수 있습니다. RxWriter와 RxAndBulkWriter의 차이는 대략 10% 정도 차이가 있습니다. 이 차이는 배치 애플리케이션과 DB 서버가 로컬에 있어 루프백으로 통신을 진행하여 차이가 크게 발생하지 않았으나 실제 환경에서는 더 유의미한 차이가 있을 것으로 보입니다. 네트워크 I/O 비용뿐만 아니라 트랜잭션을 점유하는 시간, 커넥션을 맺고 있는 시간 등등 그룹화하여 where in 절로 처리가 가능하다면 이렇게 처리하는 것이 훨씬 더 효율적이라고 판단됩니다.
또 RxAndBulkWriter 경우 where in으로 처리하기 때문에 ChunkSize를 늘리면 더 성능이 좋을 것으로 생각했지만 5,000 보다 1,000 Chunk가 더 좋은 성능이 좋았습니다. 아마 Rx에서 스레드를 알맞게 나누고 그것을 다시 병합하는 과정의 비용이 비싸기 때문이라고 추정됩니다. 대량 처리를 진행하는 경우는 각 환경에 맞는 ChunkSize를 측정하여 사용하는 것이 바람직해 보입니다.